Ma már mindenki tudja, a Google hamarosan bezárja RSS olvasó szolgáltatását. Az okok között szerepel, hogy szeretnének jobban a közösségi média felé nyitni. Több mint egy éve elérhető már a Prismatic, ami egyszerre nyújtja a közösségi olvasás élményét és ügyel arra, hogy elkerüljük a filter bubble-t. Állítólag ez annyira jó dolog, hogy még a párkeresésben is segít.
First dates are never easy. Prismatic is here to help. from Prismatic on Vimeo.
A Prismatic tkp. arra az egyszerű ötletre épít, hogy a közösségi médiában rengeteg tartalmat osztunk meg. A regisztráció során összekapcsolhatjuk Twitter, Facebook és Google fiókjainkat a Prismatic-kel, beállíthatjuk milyen témák érdekelnek minket és persze követhetjük itt is ismerőseinket. Mindezt pedig egy nagyon minimalista, magazinszerű felületen prezentálják felénk.
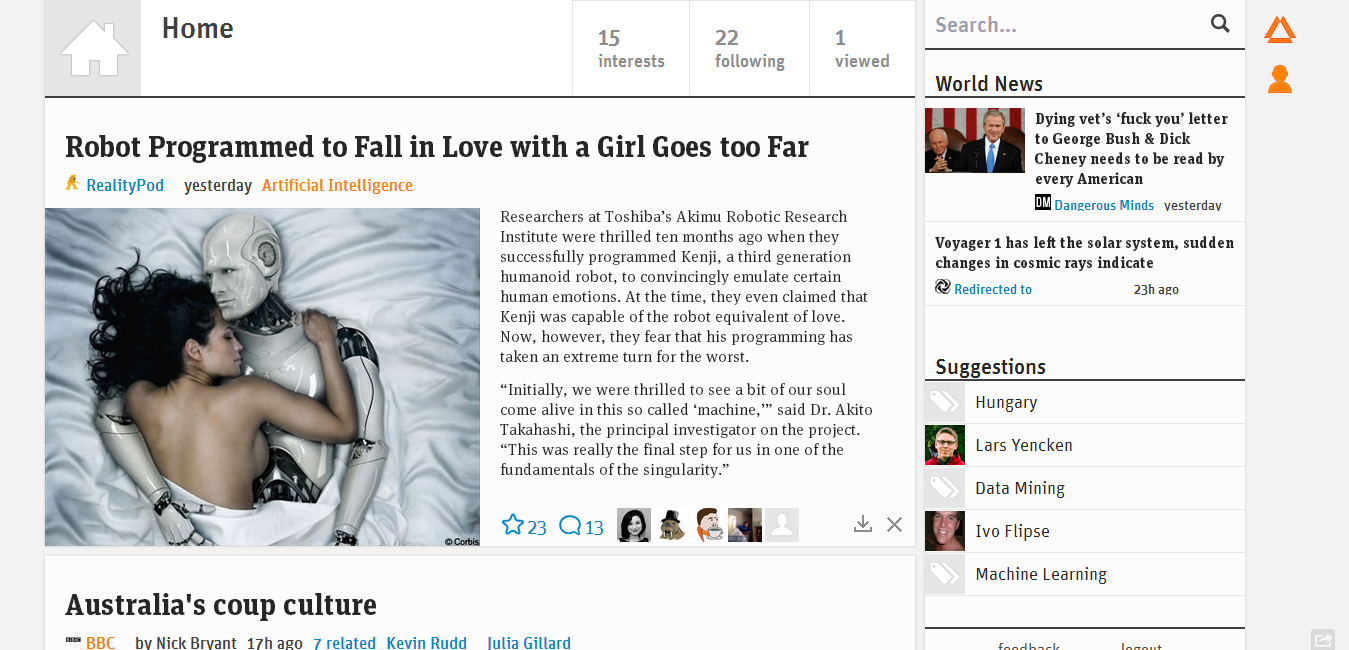
Nagyon sok alkalmazás van a piacon, ami hasonló elven működik (ilyenek pl. a blogunkon már bemutatott Wavii és bottlenose). A Prismatic megkülönböztetőjegye az, hogy a közösségi média forrásokat és a felhasználó preferenciáit vegyítve alakítja ki a személyre szabott tartalmat. A használat során egyszerűen tanítjuk a rendszert, pl. számon tartja mit olvastunk el, mit osztottunk meg másokkal, mit tettünk a kedvencek közé és mit töröltünk, mi érdektelen. A nyelvtechnológiai megoldásoknak köszönhetően a duplikátumok (ugyanarról a témáról szóló, szinte azonos tartalmú cikkek) száma elenyésző, viszont megdöbbentően jól szolgálja ki a felhasználó ízlését. A filter bubble elkerülése viszont kicsit esetlegesre sikeredett, néha úgy érzi az ember, hogy véletlenszerűen kapott egy cikket, máskor viszont teli találat és egy nekünk kedves nézettel szöges ellentétben álló véleménnyel szembesít minket.
A Prismatic technológiai körökben avval vívott ki elismerést, hogy egy nagyon kis létszámú csapattal építette fel az egész szolgáltatást. Az alapító Bradford Cross a Flightcaster-el tette le névjegyét a big data fronton, majd teljesen kívülállóként vágott a hírek újragondolásába. Blogja a Measuring Measures legendás a szakmában (habár a szerző új cége indulásakor törölte) mivel itt jelentek meg először a big data termékfejlesztéssel kapcsolatos kérdések. Crossnak nagyon erős elképzelései vannak az adatvezérelt termékek fejlesztésével kapcsolatban, ezek egyike hogy egy kicsi, erősen és sokoldalúan képzett csapat sokkal hatékonyabb ilyen feladatokra. Ennek szellemében a Prismatic-nél mindenki a Berkeley vagy a Stanford doktori fokozatával van felvértezve.
A minimalista külső mögött komoly design megfontolások állnak. A Prismatic a tartalomra épít, az összegyűjtött híreket könnyen áttekinthető formában prezentálja a felhasználók felé és megkönnyíti a forráshoz navigálást. Ebben nagyon hasonlít a Google-re. A Prismatic célja egy általános felfedező motor (discovery engine) létrehozása, ami nem csak hírek felfedezésében segít. Habár a befektetők megnyerésével nincs gondja a cégnek, még nem sikerült megtalálni a bevételszerzés módját, de talán ahogy a fenti interjúban is elhangzik, a felhasználók célba juttatásáért kapott jutalék lehet ennek egyik módja.