


A céges adatokban rejlő potenciált kiaknázása a jövőbeli üzleti siker kulcsa. Ennek alapja pedig a szervezeti tudáscsomagban történő eredményes keresés.
- Hogyan valósítható meg az intelligens, többek között a mesterséges intelligenciát és számos szöveganalitikai megoldást is alkalmazó vállalati keresés?
- Hogyan működik mindez a gyakorlatban?
- Mely típusú dokumentumokban kereshetünk? Mit jelent az egyszerű és az összetett keresés?

Mindezekre választ kaphatnak az érdeklődők azon a KM Expert által szervezett hibrid eseményen, amelynek vendégelőadói Kiss-Vincze Róbert vezető szoftverfejlesztő és Gelencsér Gábor üzleti elemző lesz a Precognox részéről.
Okos keresés: gyors válaszok a céges tudásról (hibrid esemény)
Az 2023. október 31-i eseményen történő részvétel ingyenes, ugyanakkor regisztrációhoz kötött, a személyes férőhelyek száma pedig korlátozott. Éppen ezért döntöttek a szervezők amellett, hogy az előadást hibrid módon valósítják meg, tehát a személyes részvétel mellett online (Microsoft Teams-en keresztül) is csatlakozhatnak az érdeklődők. Mindez jelezhető az a KM Expert eseményt bemutató oldalán található regisztrációs űrlapon.
Az előadás személyesen az Eco-Office közösségi iroda oktatótermében (1064 Budapest Izabella u. 68/b) tekinthető meg.
Az esemény programja:
- 16.45 Érkezés, ismerkedés
- 17:00 Bevezető, bemutatkozás
- 17:10 A Precognox két bemutatója (bemutató, problémafelvetés és előadói válaszok)
- 18:20 Záró gondolatok
- 18:30 Helyszíni networking
- 19:00 Zárás
Mikor érdemes feltétlenül részt venni az eseményen?
Az okos vállalati keresésben rejlő lehetőségek megismerése számos esetben lehet érdekes, többek között amennyiben:
- hatalmas vállalati adatvagyon áll rendelkezésre
- a céges dokumentumokban nehézkes és időigényes a keresés
- speciális keresési igények merülnek fel a szervezetben
- ismétlődő, összetett keresések futtatására van szükség
Az eseményen bemutatásra kerül az a mesterséges intelligenciát is integráló, Precognox által fejlesztett keresőmegoldás, amely segítségével kérdéseken kersztül kaphatunk válaszokat üzleti kédréseinkre.
A téma a cégvezetők, a döntéshozók, az IT szakemberek mellett az adminisztrációban dolgozó munkatársak érdeklődésre is egyaránt számot tarthat. A felvetődő kérdések és az azokra adott válaszok pedig szinte bármely szegmens képviselői számára érdekesek és üzletileg hasznosak lehetnek.
Az esemény leírása és regisztráció
Az esemény szervezői és házigazdái már várják a jelentkezéseket!
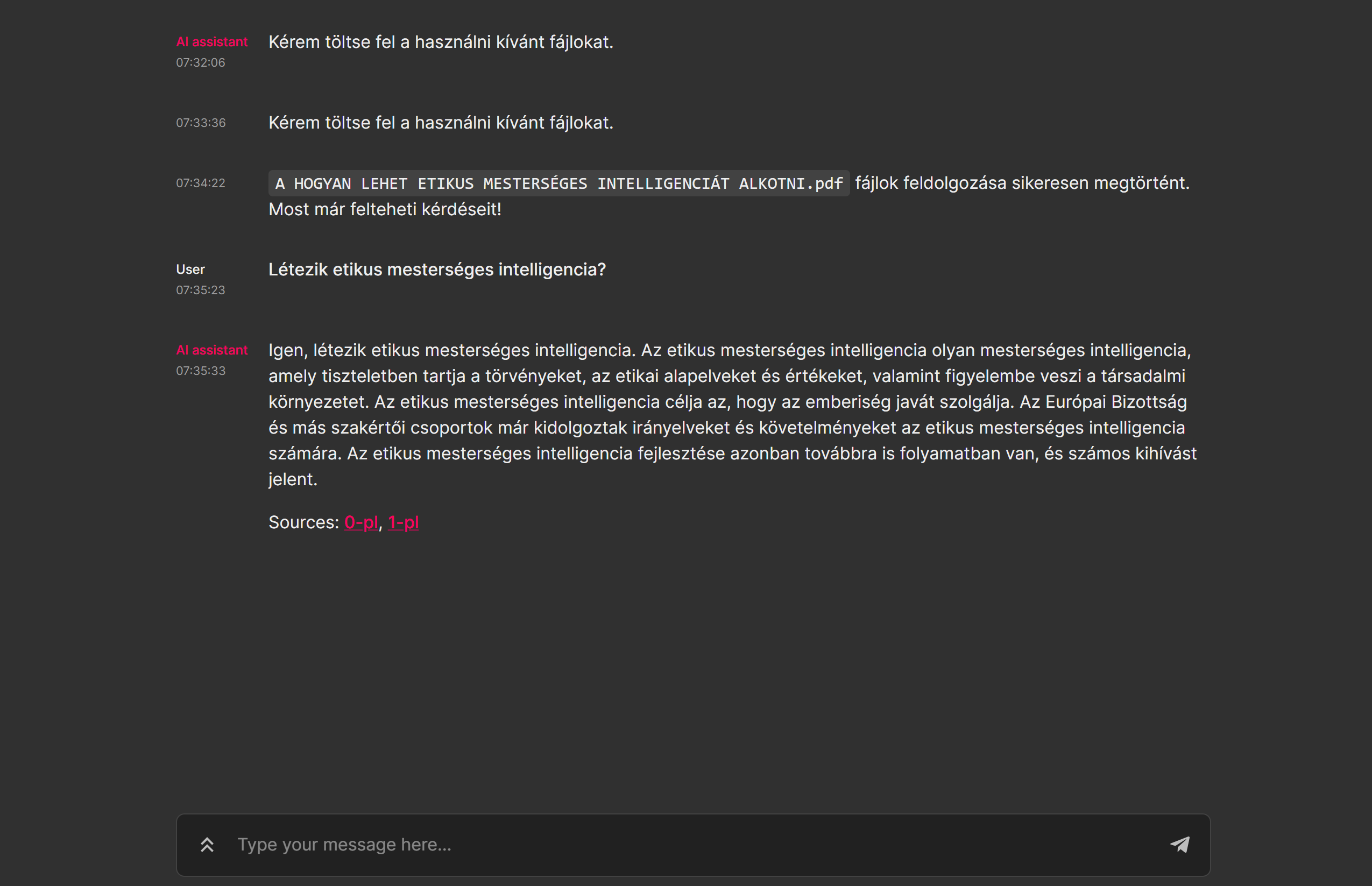


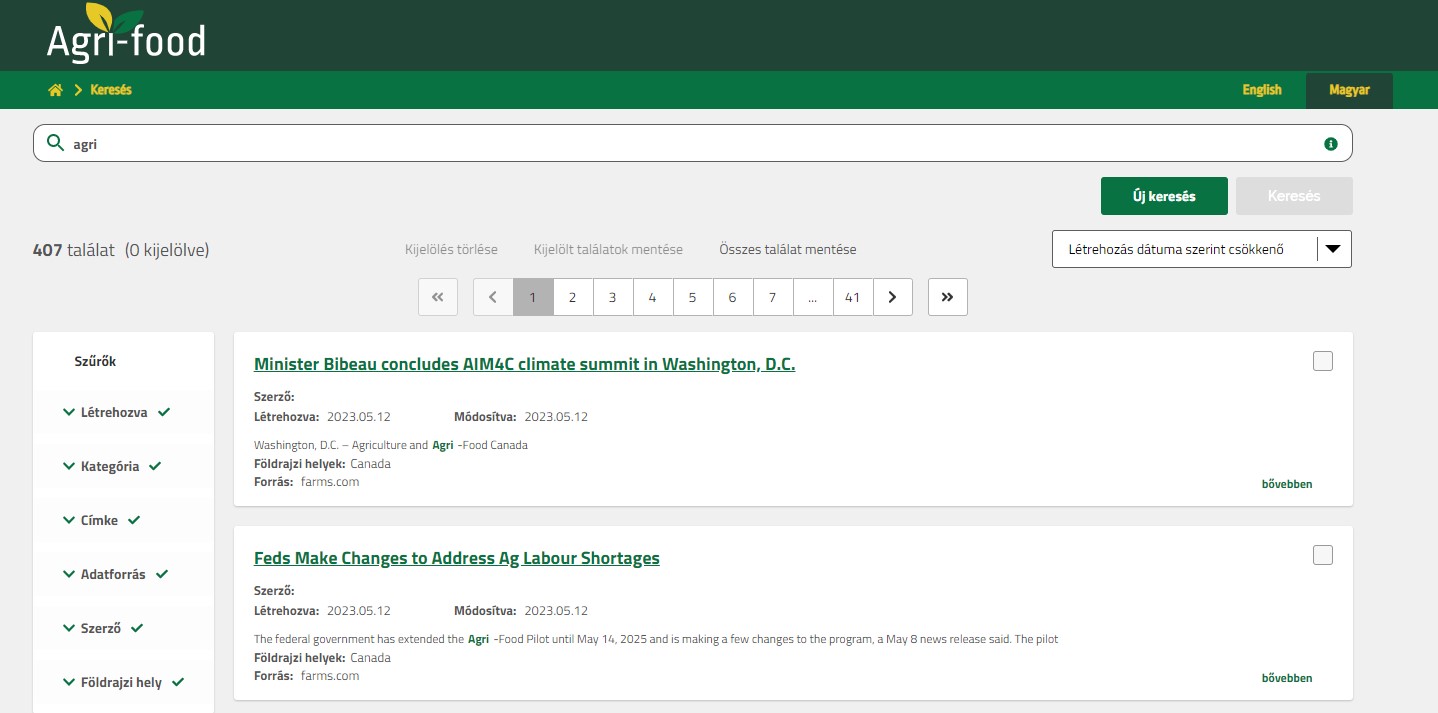




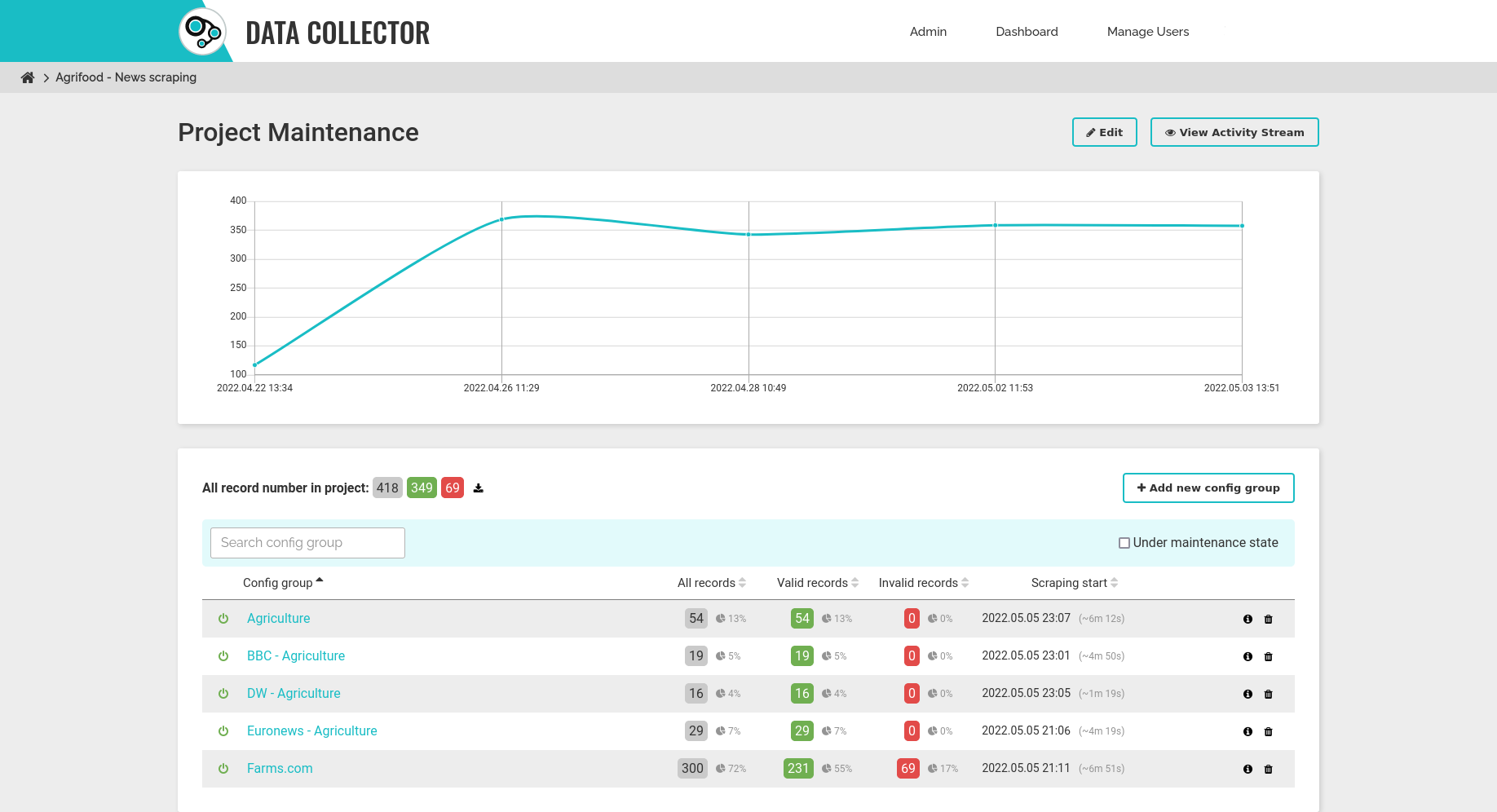
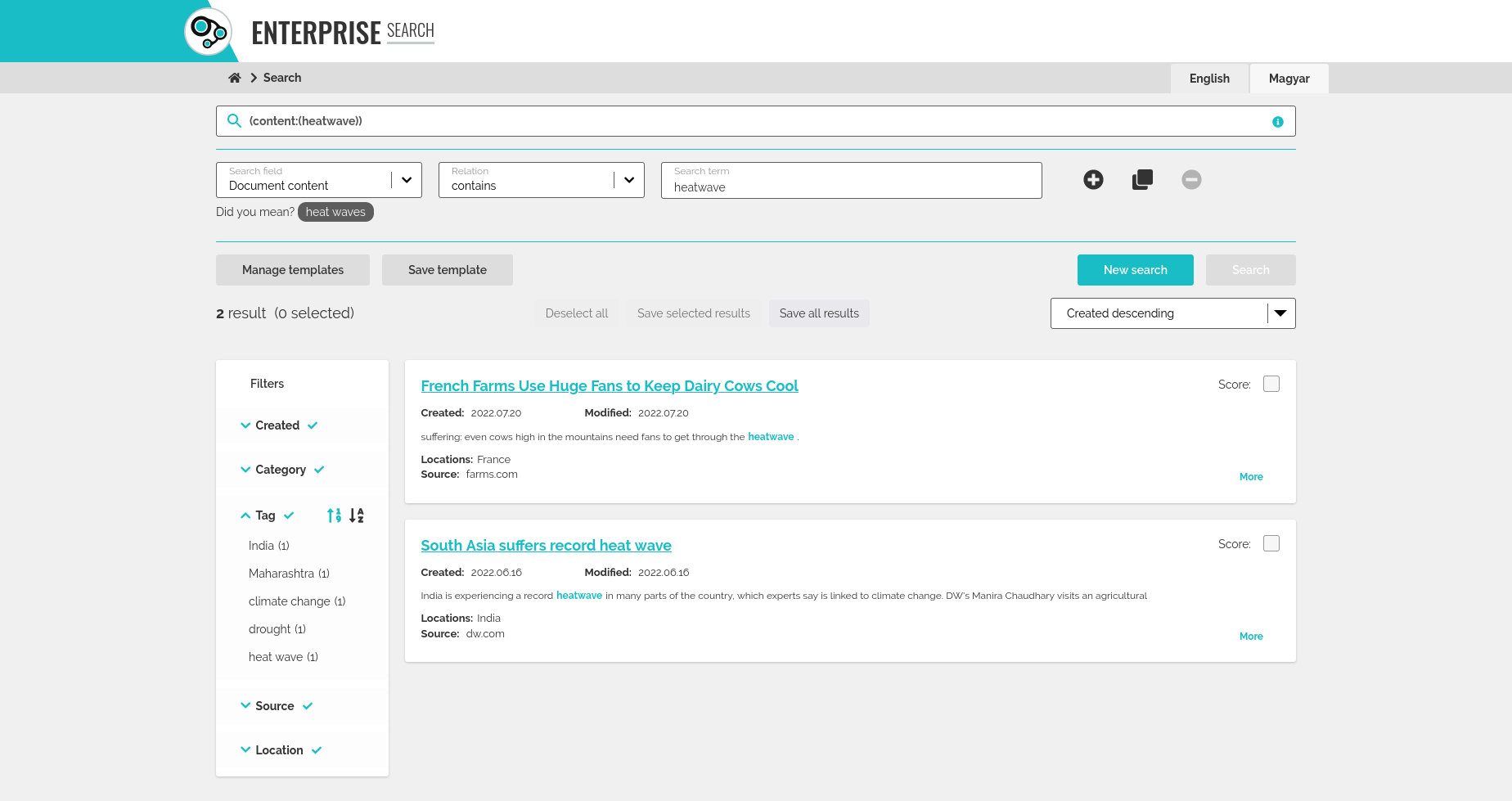 a jelenlegi keresőfelület és funkciói
a jelenlegi keresőfelület és funkciói