Gondolatolvasásnak (másnéven elmeolvasásnak, azaz mind reading) nevezik a kognitív tudósok és elmefilozófusok azon képességünket, hogy mások viselkedését megfigyelve gondolatokat, cselekvési terveket tulajdonítunk másoknak, melyre alapozva egész jól meg tudjuk jósolni embertársaink viselkedését adott helyzetekben. A Google Now (futtatásához legalább 4.1-es Android szükséges) arra vállalkozik, hogy válaszoljon kérdéseinkre még mielőtt feltennénk azokat, mindezt viselkedésünk tüzetes elemzésére alapozva, ami sok adatvédelmi kérdést vet fel.
A mobil ereje a kontextusban rejlik, hiszen a böngészési és egyéb használati adatokat összeköthetjük geolokációs és időbeli változókkal. Az új, Jelly Bean néven futó, Android mobil operációs rendszer ezt meg is teszi. A felhasználó Google fiókját alaposan feltúrja és a mobil adatokkal kiegészített kontextus alapján figyelmeztet minket, ha találkozónk van, elemzi utazási szokásainkat és segít elkerülni a közlekedési dugókat stb.
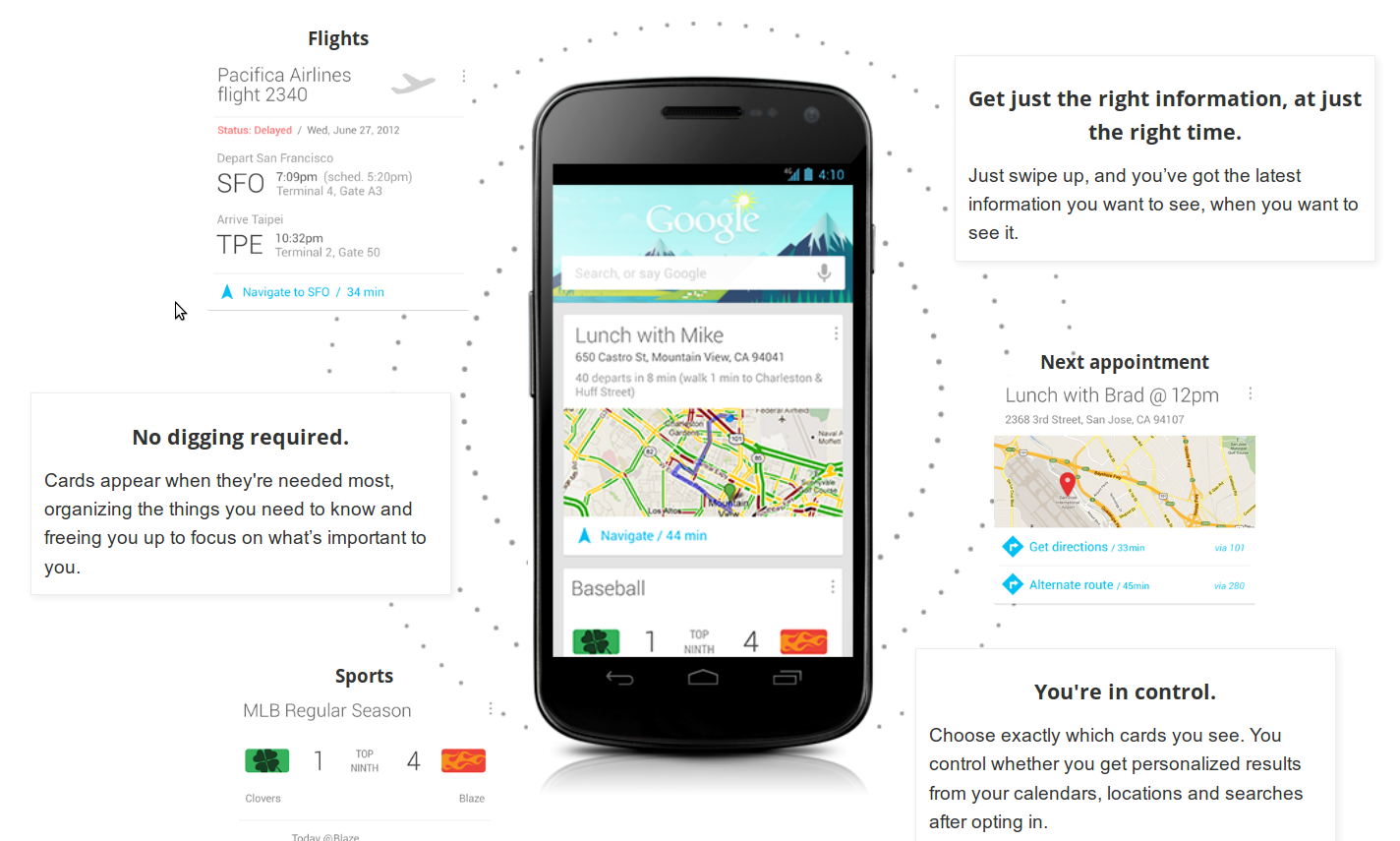
A kontextusfüggő információkat ún. kártyákon jeleníti meg nekünk a rendszer. Ezek egy része, mint pl. az időjárás és az idő, ismerős lehet sokak számára.
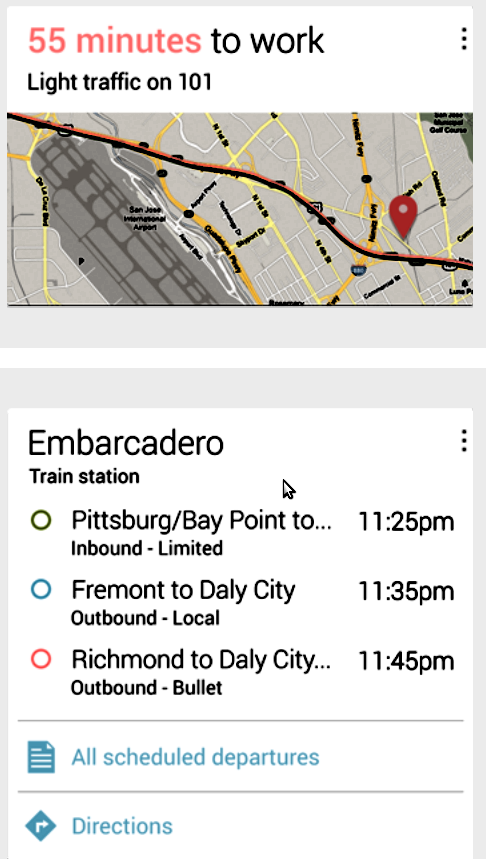
Az útfigyelés és alternatív útvonalak ajánlása azonban mutatja, hogy a Google igazi nagy testvér módjára eltárolja adatainkat és tisztában van vele merre járunk munkába.
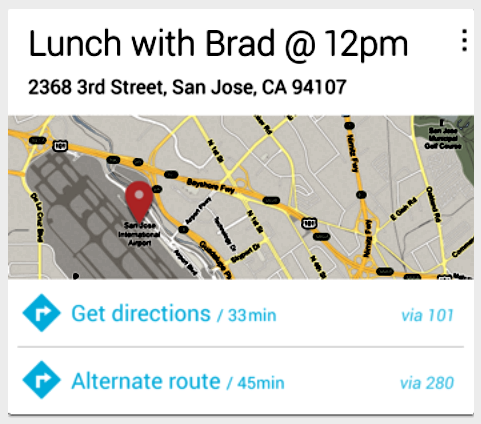
A helyi információkra alapozva még azt is elárulja nekünk telefonunk, hogy késni fogunk a következő találkozónkról.
A kártyák már most lefedik a mindennapok legfontosabb eseményeit. A közúti- és tömegközlekedési információk, találkozók, idő és időjárás mellett, sportrendezvényekről, helyekről, repülőjáratokról kapunk információt és ha külföldre tévedünk akkor a Google Translate segít nekünk a kommunikációban.
Az ember egyszerre csodálkozik és borzad el azon, hogy a kontextus erejére alapozva a technika szinte szó szerint olvassa gondolatait és siet a segítségére miközben a Google lassan jobban ismer minket mint mi saját magunkat.