A közösségi média elemzése az egyik legfelkapottabb téma manapság. Megszámolni is lehetetlen hány startup célja, hogy információt nyerjen ki a netezők által generált tartalmakból. Kevesen jutnak el pl. a DiscoverText szintjére és tudnak széles rétegek számára használható elemzést kínálni. Azok a cégek pedig, melyek a megrendelő igényeihez jobban alkalmazkodnak és mélyebb elemzést végeznek, mint pl. a Quid, sokkal drágábban dolgoznak. A svéd gavagai az utóbbi irányzat egyik legerősebb tagja, olyan eljárást dolgozott ki, amely a közösségi médiát hatékonyan tudja elemezni.

A cég nevét Willard Van Orman Quine analitikus filozófus híres gondolatkísérletében szereplő nyúlról kapta. Szabadalmaztatott "ethersource" technológiájuk az ún. disztribúciós szemantikán alapul, mely dióhéjban annyit tesz, hogy egy szó jelentését az határozza meg milyen környezetben, azaz milyen más szavakkal fordul elő. Így egy mondat, vagy egy hosszabb szöveg nem más, mint egy újabb disztribúciója (eloszlása) a benne szereplő szavaknak. A módszer az ún. látens dirichlet allokáció (latent dirichlet allocation, röviden lda) eljárásra épít, de ennél többet - érthető okokból - nem lehet megtudni róla. Ez a metódus viszonylag könnyen átültethető egyik nyelvről a másikra. Mivel mérhetővé teszi az egyes szavak egymáshoz viszonyított jelentését, teret nyit arra hogy, pl. szentiment analízist (érzelmi viszonyt) végezzenek szövegeken, vagy trendeket kövessenek nyomon.
Az idei Eurovízió Twitter elemzése sikeresen előrejelezte a svéd győzelmet.
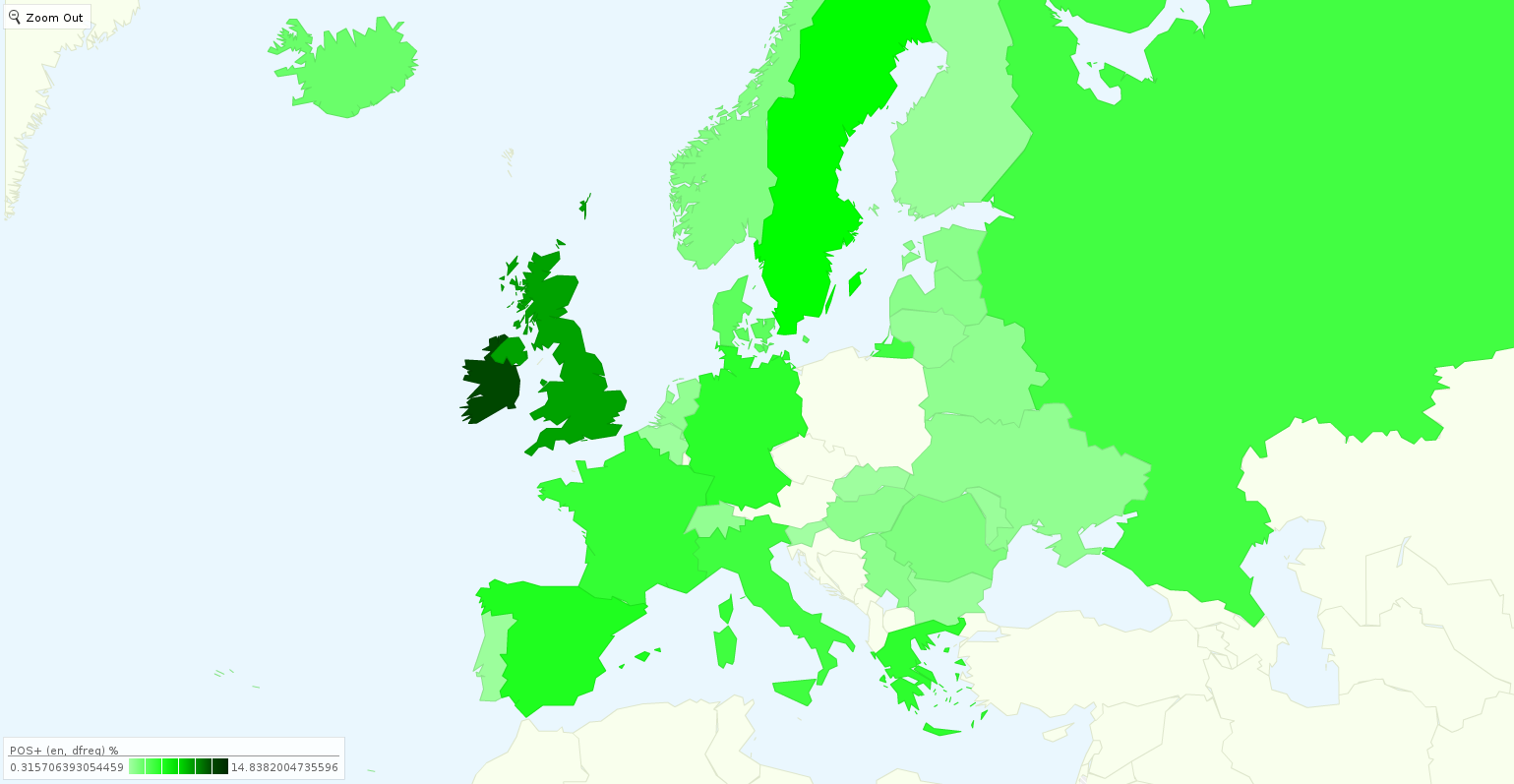
Figyelembe véve az egyes országok közötti különbségeket (pl. internet penetráció és Twitter használati eltérések) még sokkal jobb eredményt kaptak.
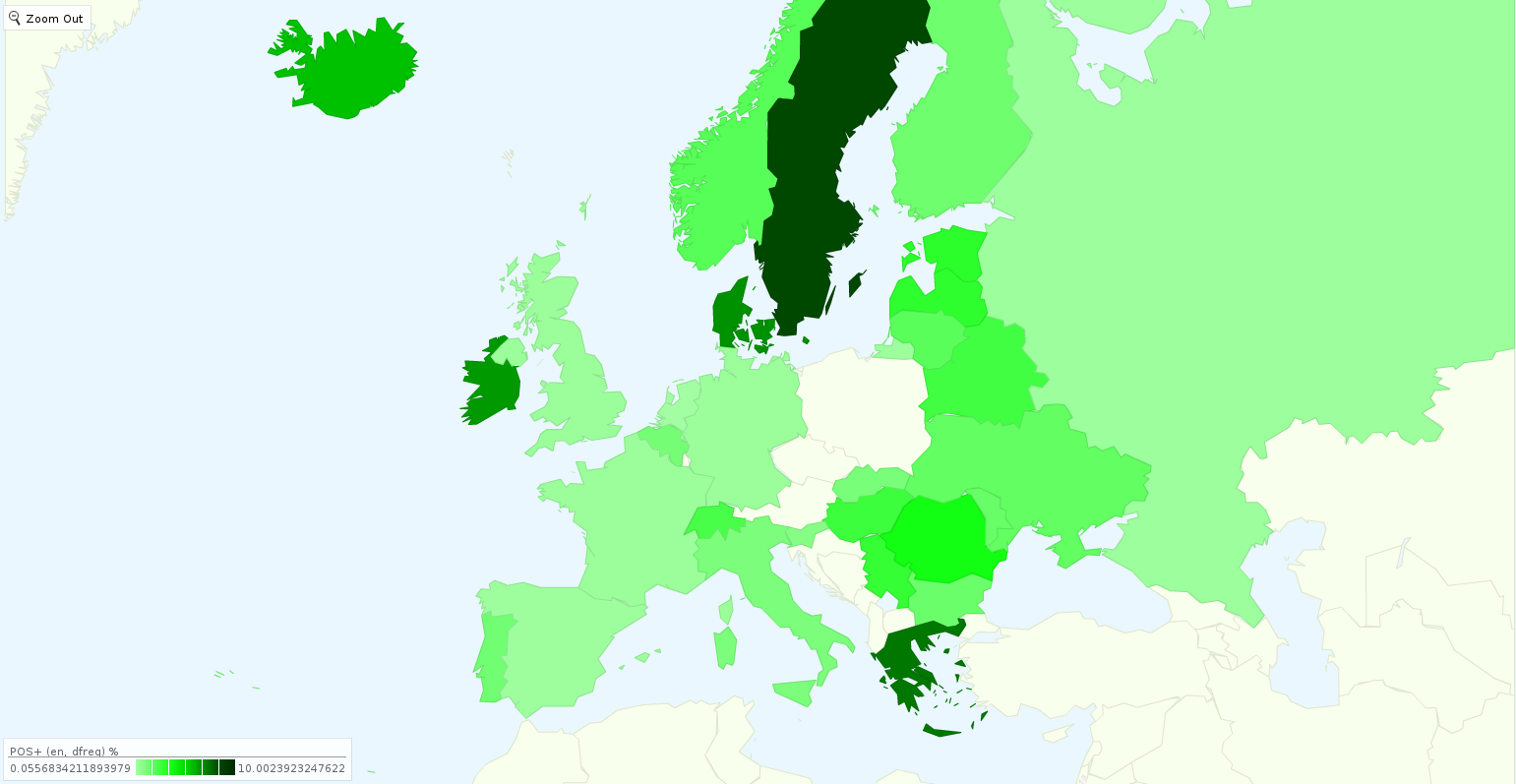
A gavagai példája jól mutatja, hogy ha igazán fontos számunkra a közösségi média elemzése, akkor (még) nem hagyatkozhatunk a "dobozos" megoldásokra. Az adatok kezeléséhez, kiegészítő információk kereséséhez és az elemzés értelmezéséhez szükséges szakértők bevonása. Ez azonban meg is drágítja egy-egy ilyen eszköz használatát, de az IT területén viszonylag gyorsan tömegtermékké válhat egy árú vagy szolgáltatás szerencsére, ami leszoríthatja az árakat.