Egyre több kereséssel foglalkozó cég fordul az ún. big data, vagyis a nagy adatok begyűjtése és elemzése felé. Blogunkon is egyre többet foglalkozunk olyan szolgáltatásokkal, melyek az adatok körül mozognak. De hogyan is jutottunk el a kereséstől a big data-hoz?
A híres PageRank keresési algoritmus az egyes potenciális találati oldalakat rangsorolja annak tükrében, hogy hány külső link mutat rájuk. Mivel tulajdonképpen az egész Google e köré épül belátható, hogy egész jól működik ez az eljárás. Igen ám, de ahhoz, hogy az egész webre vonatkozóan tudjuk rangsorolni az oldalakat, meg kell vizsgálnunk a közöttük lévő linkeket, amihez be kell gyüjetni minden oldal forráskódját, hogy lássuk ezeket az információkat. Ez önmagában hatalmas adatmennyiség, ami időben változik (egy weboldal általában frissül, bővül, új oldalak születnek nap mint nap stb). Így időről-időre ún. crawlerek, automatikus programok mentik el az oldalak tartalmát.
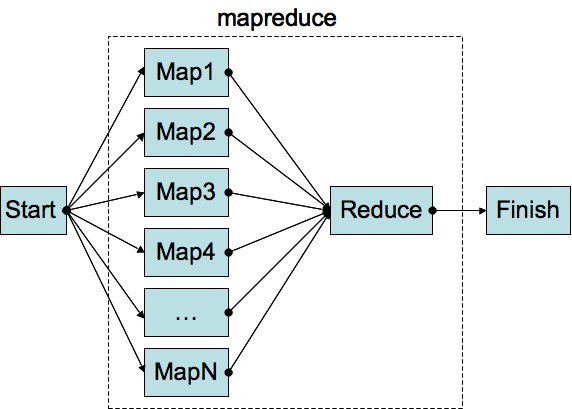
A begyűjtött adatok mennyisége gyorsan hatalmasra duzzadhat, különösen ha az egész webet figyeljük így. Ebből kell kiszámítanunk, hogy egy keresési kifejezéshez, mely oldalak milyen PageRank értékkel párosíthatóak. Ez rendkívül erőforrásigényes feladat. Sokáig úgy gondolták a szakemberek, hogy speciális hardver szükséges ehhez, de később a hardver árak csökkenésével egyszerűbbé vált nagy tömegben viszonylag olcsó eszközök alkalmazása. A Google 2004-ben fedte fel megoldását híres MapReduce: Simplified Data Processing on Large Clusters című tanulmány publikálásával. Az eljárás lényege, hogy két, jól elkülöníthető feladatként fogalmazzuk meg az adatok feldolgozását. Az első lépésben ugyanazt a feladatot "visszük ki" az elosztott rendszer minden tagjához (map fázis), majd összesítjük az adatokat. Képzeljük el, hogy gyorsan szeretnénk gyöngyöt fűzni egy csapattal. Minden tag megkapja a csomag gyöngyöt. Kérjük meg őket, hogy válasszák ki a kék gyöngyöket, majd csakis a kék gyöngyöket fűzzék rá a damilra, amit körbe adunk. A map fázist a csoport tagjai végzik, a reduce pedig a kiválasztott gyöngyök felfűzése. Az előző feladathoz hasonlóan a gyöngyök színeiről is készíthetünk összesítését. Kérjünk meg minden tagot számolja meg melyik színből hány van a csomagjába, ez a map fázis. Így nem kell minden csomagot külön-külön feldolgoznunk, hanem ha pl a zöld gyöngyök száma érdekel minket csak megkérdezzük kinél hány darab van, pl. 9, 9, 9, 8, 5 és összeadva megkapjuk hogy 40 (reduce fázis).
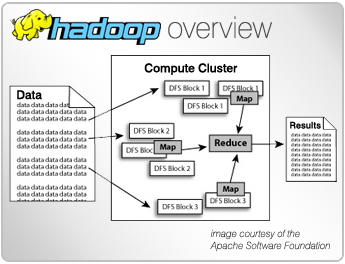
Miután a Google kutatói közölték tanulmányukat az Apache alapítvány a Yahoo! támogatásával megalkotta a Hadoop keretrendszert, mely egy nyílt forráskódú mapreduce implementáció ami köré egy kis ökoszisztéma alakult ki és egyre több cég nyújt támogatást is. A felhőalapú szolgáltatások terjedésével immár a kedves olvasó is pár perc alatt olcsón felállíthat egy Hadoop klasztert, amivel több gigabájtnyi adatot is elemzhet. Ahogy adatpiac sorozatunkban bemutattuk egyre többféle és egyre nagyobb mennyiségű adat érhető el olcsón vagy akár ingyen is.
Azonban a Hadoop csak egyik oldalát oldja meg a problémának, nevezetesen az adatelemzést. Az adatok beszerzése ellenben külön probléma marad. Vehetünk adatokat, gyakran egy cég működése során is rengeteg adat keletkezik, de sokszor magunknak kell beszerezni az elemezni valót. Ezzel vissza is jutottunk a crawlerekhez.

Az InfoHarvester a WebLib új terméke tkp. irányítottan képes összeszedni és a Hadoop számára elemezhető formában eltárolni a szükséges adatokat. Így rögtön kereshetővé és elemezhetővé is válik az adatbázis.
A big data tehát a keresés egyik speciális problémája, nem csoda, hogy egyre több eredetileg keresőkkel foglalkozó cég fordul a terület felé.