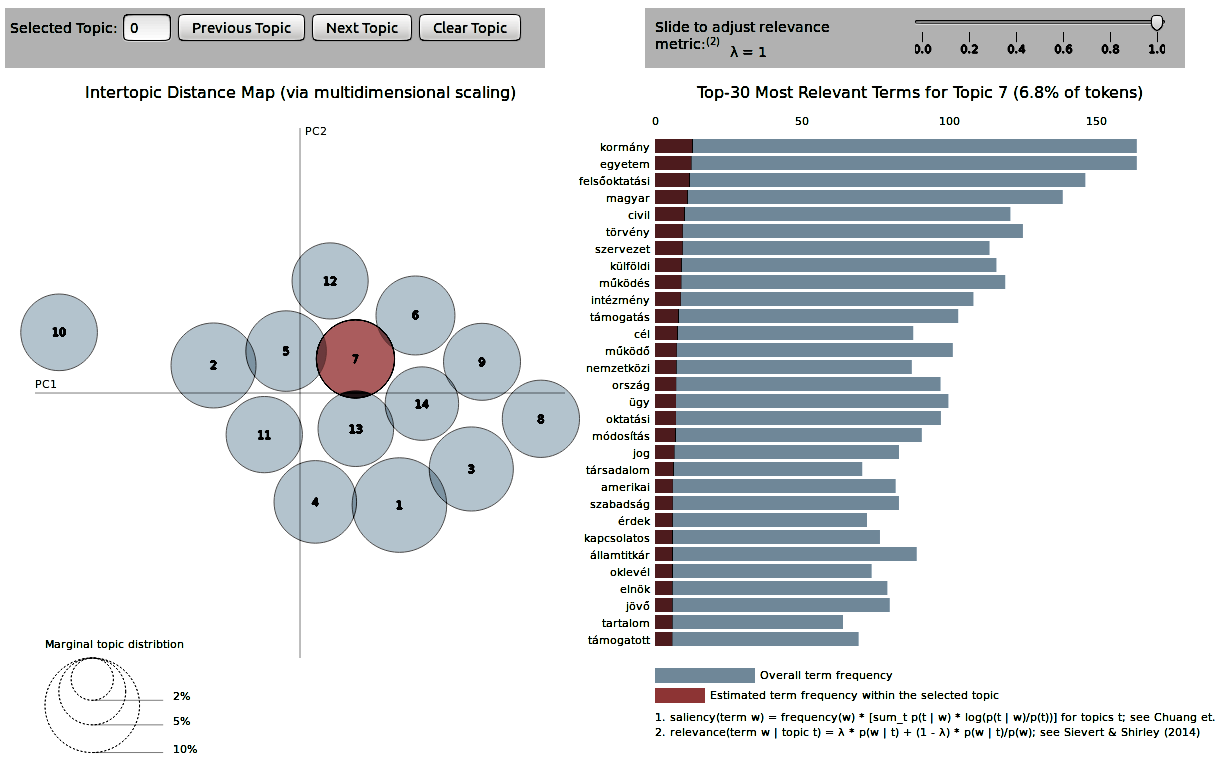
Egy korpuszunkon kipróbáltuk az lda2vec algoritmust, mert már nem bírtuk tovább. Jelentjük, nem is olyan rossz az eredmény! Itt meg is lehet nézni!

Christopher E. Moody Mixing Dirichlet Topic Models and Word Embeddings to Make lda2vec tanulmányát megjelenése óta imádjuk és párszor már használtuk is az általa implementált változatát. Most egy kicsit belekontárkodtunk a kódba (pl. Chainer helyett mi Keras-t használunk), hogy a tüntetések, és a CEU-ügy kapcsán megjelent cikkeket tartalmazó korpuszunkat elemezhessük.
De miért?
Itt már megírtuk, hogy az LDA két külön topikba pakolta az jobb- és baloldali lapokban ugyanazon témában megjelenő cikkeket. A korpuszon trénelt word2vec modell azonban azt mutatja, hogy az eltérő kifejezések, mint pl. CEU és a Soros-egyetem nagyon hasonló helyet foglalnak el a szemantikai térben. Nem gondoljuk, hogy az LDA rossz, mert a két eltérő narratíva bezavarta. Ellenben arra voltunk kíváncsiak, hogy a word embeddings-re alapozott topik modell képes-e ezen túllépni. Számításunk bejött! Habár még sokat kell pofozni a modellen, de a prototípusra kapott pyldaviz vizu megtekinthető itt.