Az érdekelt minket, hogy hogyan jelenik meg az online médiában a civil szervezetek és a CEU ügye. Négy oldalt vizsgáltunk (Index, 444, Origo és 888), hogy képet alkothassunk erről. Azt találtuk, hogy napjaink nagy figyelmet kiváltó eseményeit nagyon eltérően mutatják be a híroldalak, mondhatni két párhuzamos valóságot tárnak élénk világnézeti beállítottságuktól függően. Adatok, szófelhők és egy interaktív topik modell vizualizáció.
A korpusz jellemzői
Vizsgálatunk a 2017.04.01. és 2017.04.14. között megjelent írásokra korlátoztuk. A négy vizsgált oldalt önkényesen választottuk ki, remélve, hogy tükrözik a mai magyar sajtóban meglévő elkötelezettséget. A cikkeket az oldalakon található címkéket felhasználva gyűjtöttük be (pl. Soros, CEU, civil szervezetek, stb.), ez alól kivételt képez az index, mivel az oldal nagyon kényelmesen használható aktákba rendezi tartalmait. A nyelvi feldolgozást magyalánccal végeztük, ezen kívül a Python nltk csomagjával dolgoztunk. A szövegeken a hunNERwiki korpuszon trénelt névelemfelismerőt futtattunk le, hogy a lehető legtöbb személy- és intézménynevet egyben tudjuk tartani, majd igyekeztünk a leggyakoribb elemeket egyértelműsíteni (pl. Orbán lecserélhető Orbán Viktorra, Soros, Soros Györgyre, de Gulyás esetében nem járhattunk el így).
| site | cikkek száma |
lexikai diverzitás (szótövek száma / egyedi szótövek száma az adott oldal összes szövegére) |
karakterek száma/cikk | karakterek száma/mondat | mondatok száma/cikk | átlagos szóhossz karakterben |
| index | 84 | 5.94 | 4351.4 | 137.4 | 18.6 | 6.9 |
| 444 | 267 | 12.37 | 2071.2 | 142.9 | 19.31 | 5.9 |
| origo | 50 | 11.61 | 3293.3 | 170.2 | 21.6 | 6.36 |
| 888 | 112 | 5.52 | 1961.8 | 143.7 | 18.5 | 6.28 |
A jobboldali irányultságú lapok sokkal kevesebbet írtak az eseményekről, ugyanakkor alapvető szövegstatisztikai különbséget nem mutatnak írásaik. A lexikai diverzitás a legérdekesebb mutató a táblázatban, ez azt mutatja, hogy mennyire gyakran használnak újra egy adott szót, tehát minél kisebb ez a szám, annál változatosabb az adott szöveg szókincse. Az index és a 888 eredményei kiugróan jók, annak tükrében, hogy saját tapasztalatunk szerint egy-egy oldal rovatára nézve ez az érték 12-13 között szokott lenni. A 444 esetében a teljesen átlagos érték annak köszönhető, hogy egy-egy témáról rengeteg cikket közöltek, ami óhatatlanul szóismétlésekkel jár.
Szógyakorisági adatok
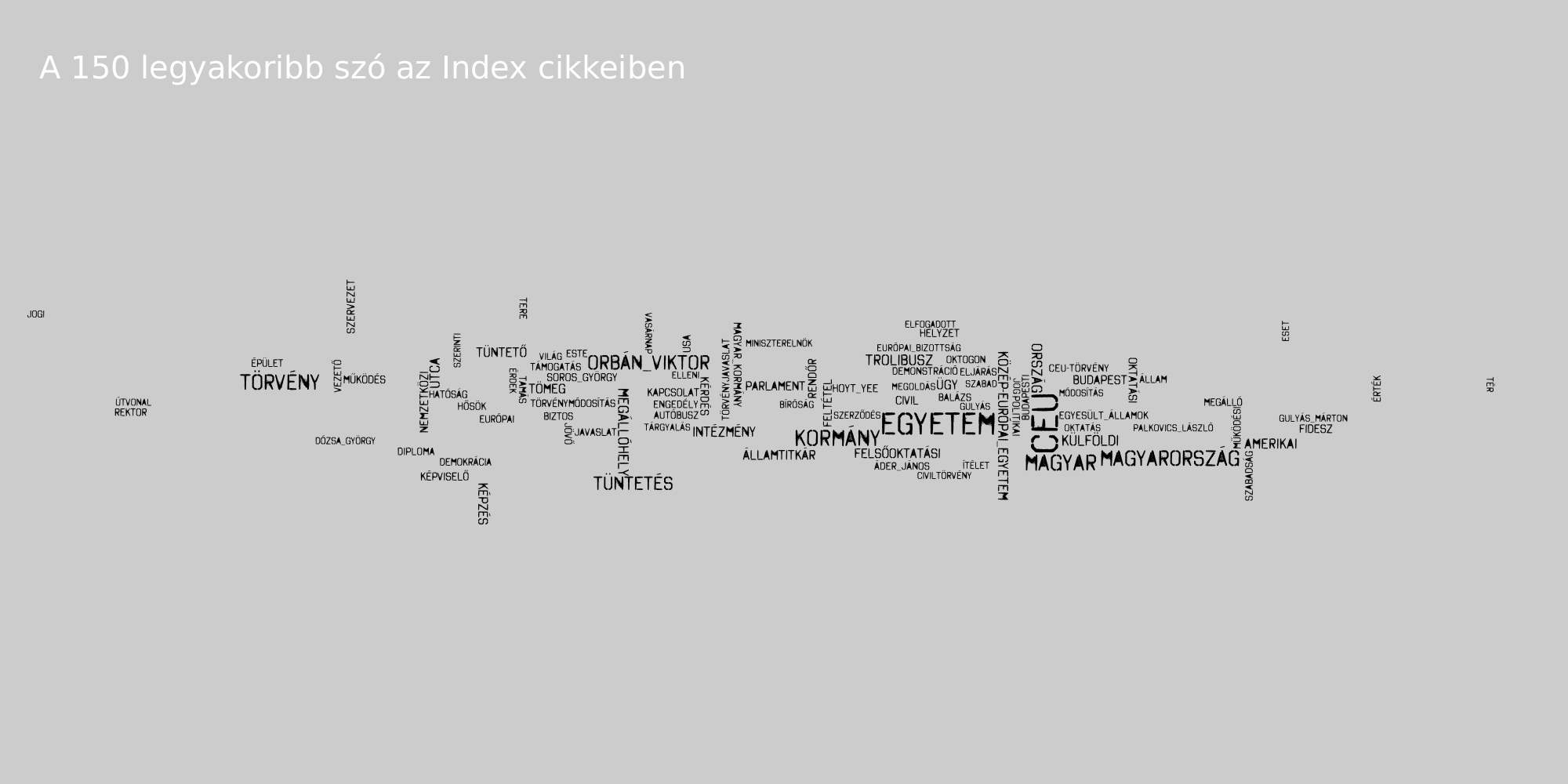
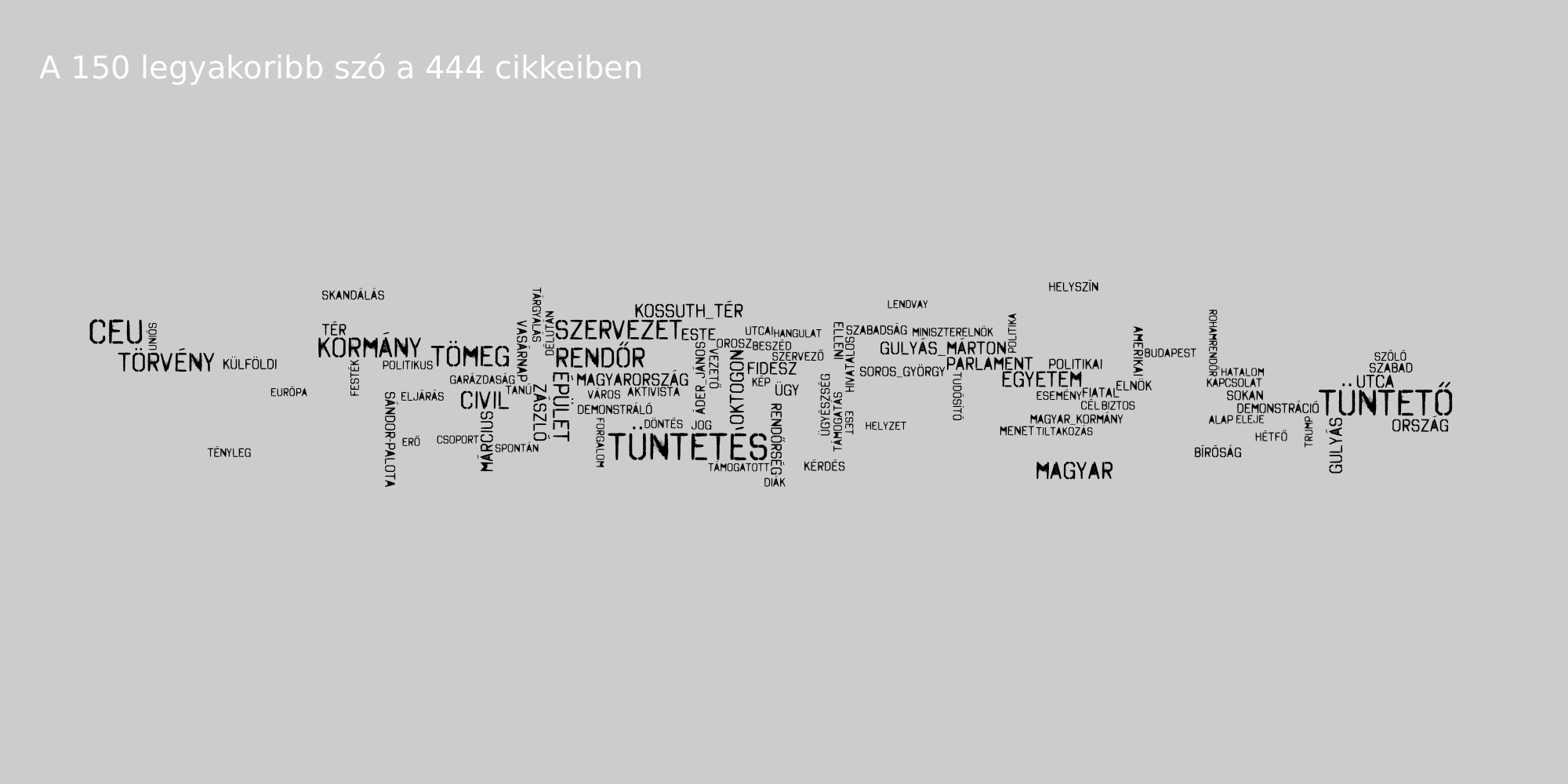
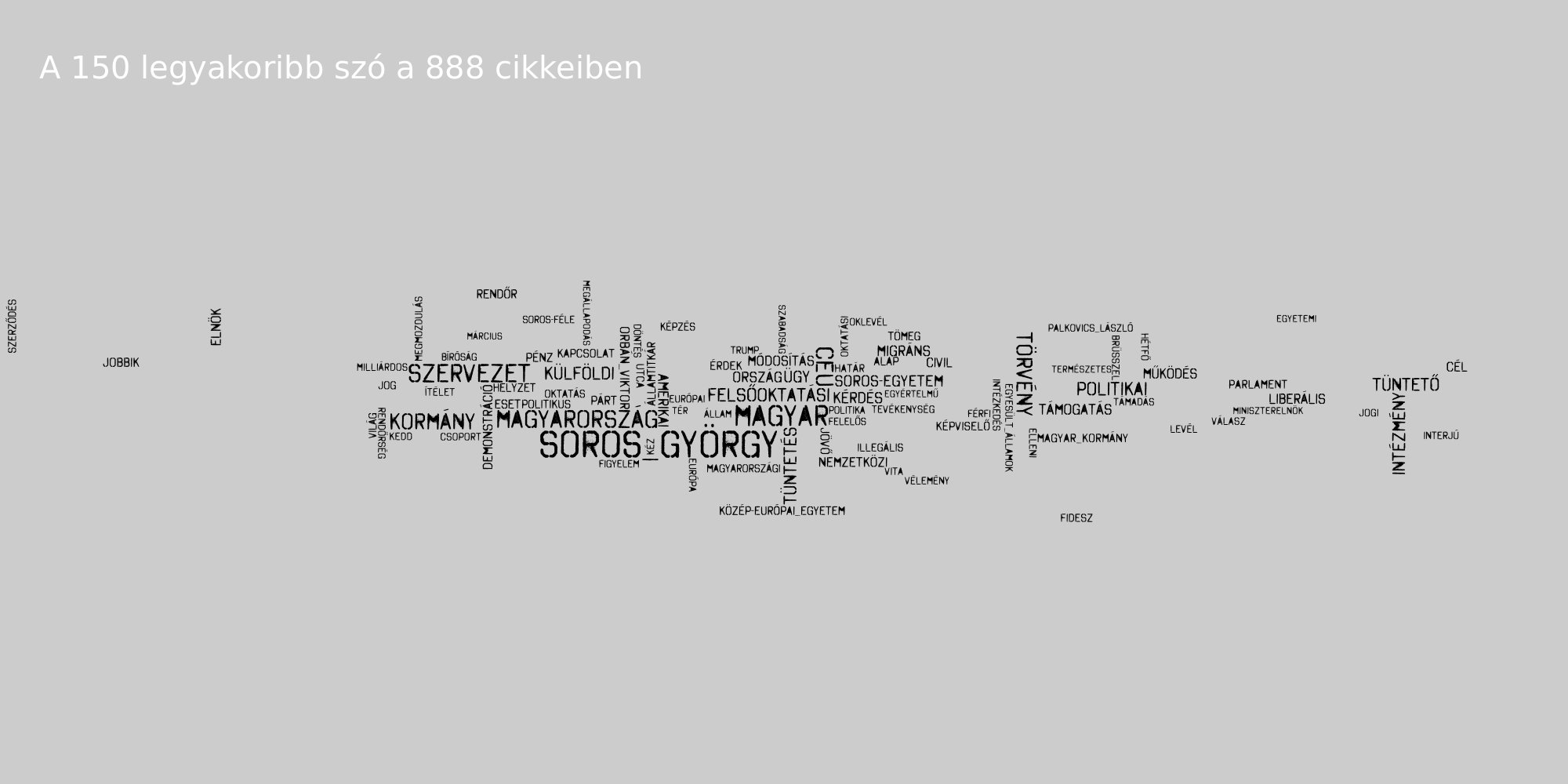
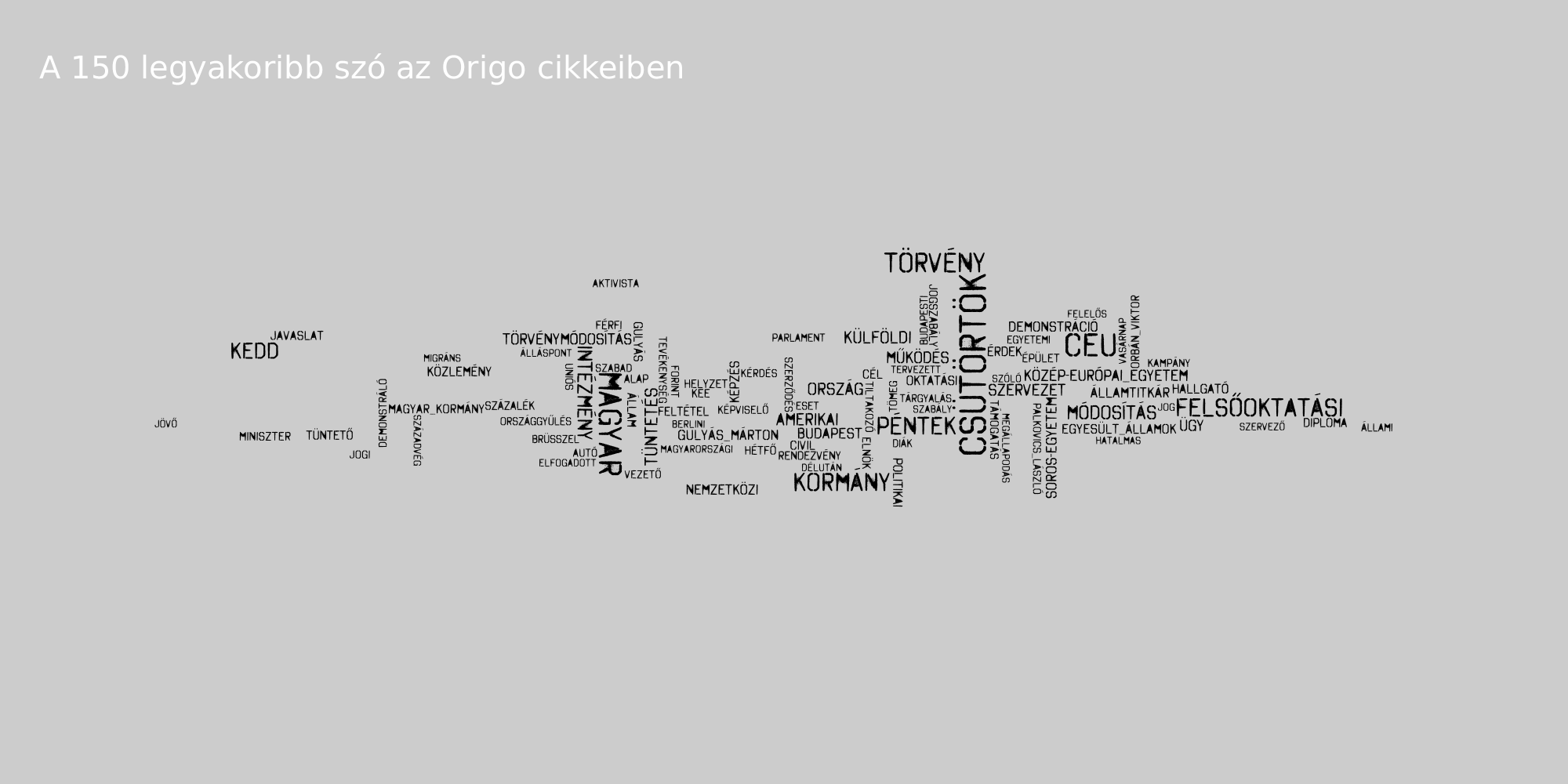
Kulcsszavak
Az AntConc program segítségével megnéztük, hogy az egyes oldalakon mely szavak és kifejezések kulcsszavak (azaz az korpusz adott részhalmazán belül az átlagos szógyakoriságuk magasabb).

Látható, hogy a 888 szereti Soros György nevét, illetve a belőle képzett Soros-egyetem, Soros-féle stb. szerkezeteket. az Index Gulyás Márton tárgyalásának részletes taglalásával emelkedik ki a mezőnyből, a 444 a tüntetések taglalásával és Mészáros Lőrinc nevének említésével, az Origo szereti kiemelni, mely nap történéseiről is ír, illetve a Századvég kap náluk külön hangsúlyt.
Topik modell
A topik modell a gensim csomag felhasználásával készült, a vizualizációt a pyldavis könyvtárral készítettük. Az interaktív vizualizáció ezen a linken érhető le. Akárhogyan is próbáltuk optimalizálni a topikok számát, mindig maradt pár marginális (8, 9, 11, 12, 13 és 14). Illetve vannak nagyon átfedésben lévő topikok (a különféle tüntetések, a civil szervezetek ellen hozandó ill. a CEU ellen meghozott törvény). A legmeglepőbb azonban az, hogy az egyes és a kettes topik nagyon jól elkülönül. Annak ellenére, hogy ugyanazon eseményekről szólnak az ezen topikokba tartozó írások, az egyes topikba (két kivételtől eltekintve) kizárólag indexes és 444-es, a kettes topikba pedig origós és 888-as cikkek kerültek.
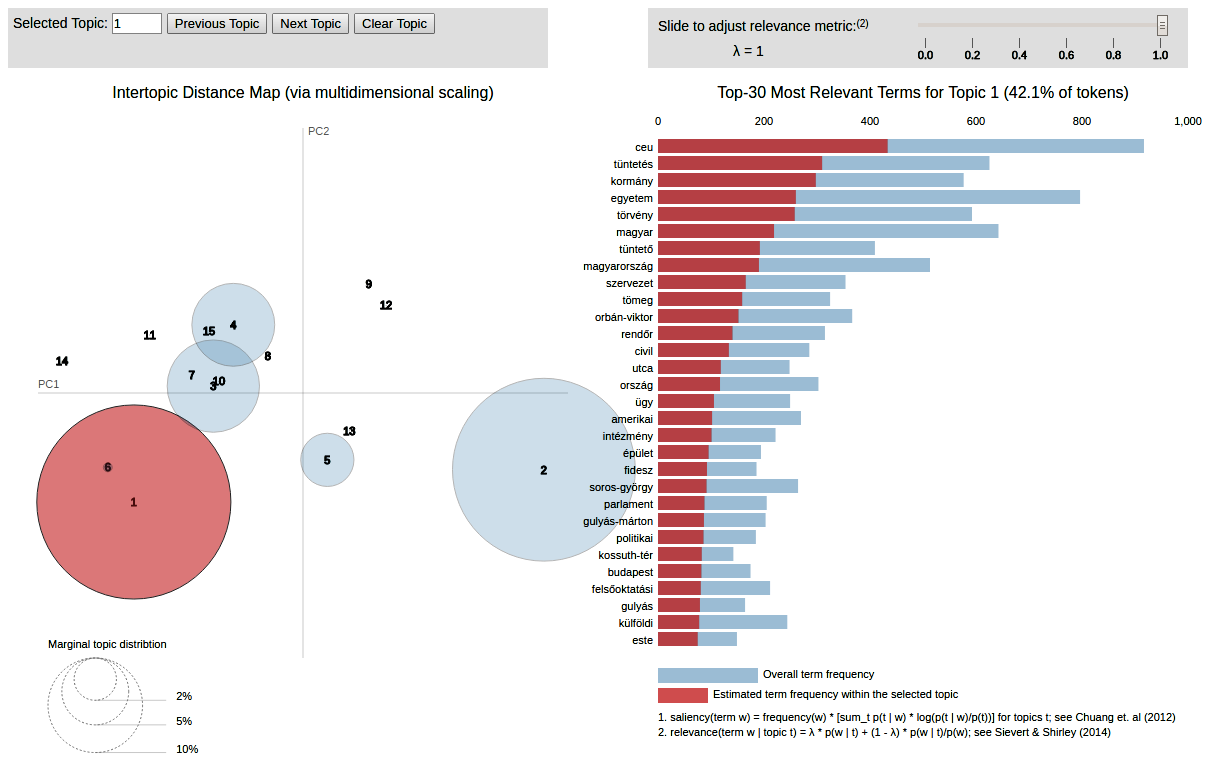
A 444 és az Index legtöbb cikkje egy topikba sorolható
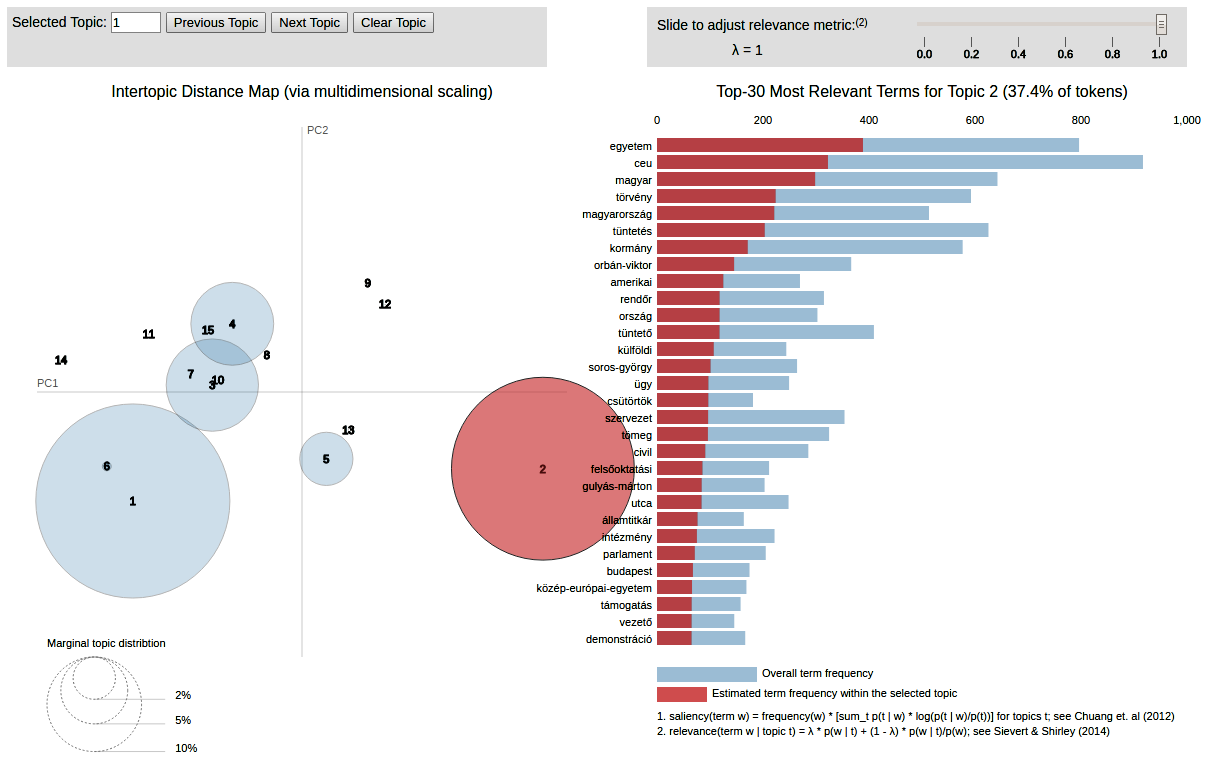
Habár ugyanarról ír az Origo és a 888, annyira más szóhasználattal, hogy az LDA külön topikba sorolja
De miért fontos ez?
Az internet nem csak totális elérést hozta el, hanem a filter bubble jelenségét is. Egyre inkább homogén közösségek alakulnak ki, a perszonalizált ajánlásoknak köszönhetően a saját világnézetünknek és preferenciáinknak megfelelő hírekkel kerülünk szembe a közösségi oldalakon. Ez hatással van ránk, egyre jobban megerősíti azt a fogalmi keretrendszert, ahogy a világot látjuk, amin keresztül például a társadalmi vitákban állást foglalunk. Ha két ennyire merőben eltérő narratívája alakul ki egy eseménynek, akkor az akár ellehetetlenítheti azt, hogy polgártársaink demokratikus, racionális vitákon keresztül közösen találjanak megoldást.
Irodalom
Balogh Kitti: A látens Dirichlet allokáció társadalomtudományi alkalmazása
Bill Bishop: The Big Sort: Why the Clustering of Like-Minded America is Tearing Us Apart, Mariner Books, 2009
Eli Pariser: The Filter Bubble: How the New Personalized Web Is Changing What We Read and How We Think, Penguin Books, 2012
George Lakoff: Ne gondolj az elefántra! - A progresszív gondolkodás nélkülözhetetlen zsebkönyve, Napvilág Kiadó, 2006
Norman Fairclough: Language and Power, 3rd Edition, Routledge, 2014