A webes tartalmak elszánt fogyasztói körében egyre elterjedtebbek az olyan böngészőkiegészítők, melyek eltüntetnek minden felesleges körítést és a szöveget nyomtatott oldalhoz hasonlóan jelenítik meg. Ebben az írásban röviden áttekintjük a legnépszerűbb ilyen alkalmazásokat, majd megvizsgáljuk ennek technikai hátterét és végül kitérünk arra, hogy ez egy komoly nyelvelméleti problémával is kapcsolatban van.
A gyakorlat: Legyen olyan mint a print!
Egyre elterjedtebbek a mobil eszközök, de ezek kijelzői általában sokkal kisebbek egy asztali gép vagy notebook képernyőjénél. A legtöbb táblagép böngészője alapbeállításként tartalmaz valamilyen olvasást könnyítő megoldást. Jelen esetben az iPad Safari böngészőjén mutatjuk ezt a funkciót.

A nyíllal jeleztük a címmezőben megjelenő "Reader" gombot, melyet megnyomva sokkal olvashatóbb formában jelenik meg a megnyitott oldal.

A népszerű Feedly hírolvasó mobil alkalmazásában is elérhető hasonló funkció. Alapesetben a hírolvasó az egész cikket le tudja tölteni és egy egyszerű oldalon jeleníti meg nekünk a tartalmat. Sok oldal azonban csak a leader szöveg átvételét engedi az olvasóknak. Ilyenkor a Feedly-ben így jelenik meg a hír.
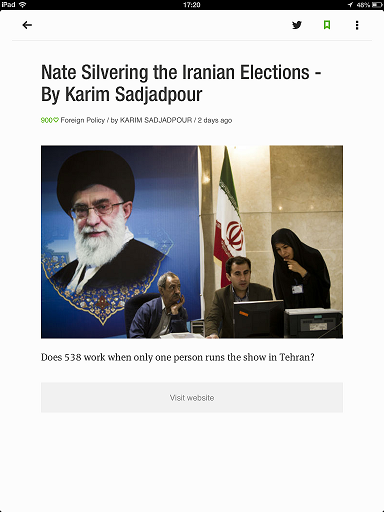
Ha ellátogatunk a hír forrására, akkor az appon belül maradva láthatunk egy hagyományos oldalt. A Feedly "Remove clutter"-nek nevezi a fölösleg eltávolítását, nyíllal jeleztük hol is található ez.
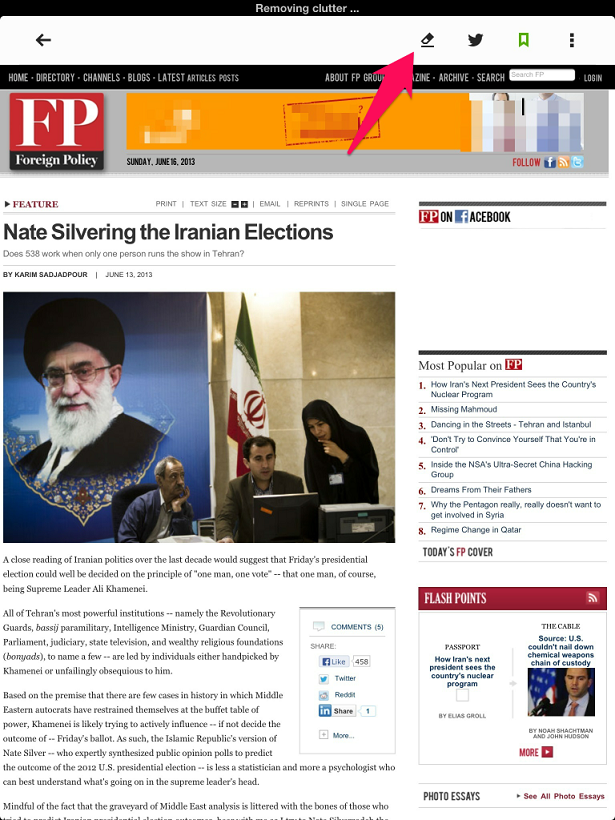
A tisztítás eredménye egy sokkal olvashatóbb lap.

A hosszabb írások képernyő előtti fogyasztása nagyon fárasztja a szemet, ezért sokan inkább e-könyv olvasón olvassák ezeket. Az Amazon Kindle olvasójához minden nagyobb böngészőre és Android készülékekre is elérhető a SendToKindle alkalmazás. Chrome böngészőt használva telepítés után a címsor mellett találhatjuk a bővítmény ikonját (szintén nyíllal jeleztük).

Az ikonra kattintva láthatjuk mit tudott "kibányászni" az SendToKindle.
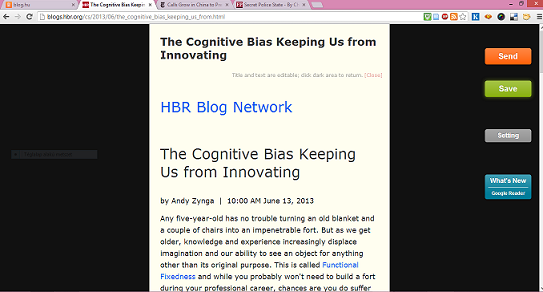
A "Send" gombra kattintva az Amazon elvégzi a többit és olvasónkon pillanatokon belül meg is jelenik a tartalom. Amennyiben a SendToKindle nem tudja magától eltávolítani a nem kívánt részeket, jelzi a problémát. Ilyenkor egyszerűen ki kell jelölni egérrel a szöveget, majd kattinthatunk az alkalmazás ikonjára s a fenti képhez hasonlóan megjelenik a kijelölt tartalom. Ha egy oldalon kétszer-háromszor találkozunk hasonló problémával és elvégezzük ezt a műveletet, akkor a SendToKindle "megtanulja" hol található a törzsszöveg és a továbbiakban magától is képes azt felismerni.
A technológia: gépi tanulás
A webes tartalmak HTML oldalak. A HTML a HyperText Markup Language azaz hyper-text jelölő nyelv rövidítése. A HTML dolga a tartalom strukturálása, a megjelenítésért a CSS (Cascading Style Sheets) felelős. Bonyolítja a helyzetet, hogy az interneten szeretünk könnyen navigálni, amihez menük kellenek. Továbbá adatlapokat töltünk ki, szeretjük a vizualizációkat és úgy általában elvárunk bizonyos fokú interaktivitást egy szájttól manapság. Ezért pedig a JavaScript felelős. De még itt sincs vége a dolognak, a honlap egy felület az interneten szörfölők felé, a szerveren sokkal bonyolultabb dolgok történnek, amit általában egy vagy több programozási nyelven írnak meg. A tartalmat és formázást leíró parancsok mellett így sok más is bekerül egy honlap forráskódjába ún. tagek, azaz a böngésző számára fontos, de számunkra nem megjelenített parancsok formájában. Elvben természetesen ezek a nyelvek formálisak, nem engednek kivételeket és nagyon szigorú szabályok szerint íródnak. Így egyszerű írni egy olyan programot, ami beolvassa a HTML-t és képes elkülöníteni a tartalmat annak formázásától és minden egyéb információtól (ez a parsing, vagyis szintaktikai elemzés). A gyakorlat azonban azt mutatja, hogy nem mindenki követi a szabványokat és a legjobb eljárásokat. Így sokszor kell egy adott oldalra szabni a tartalmat kinyerő alkalmazásokat. Ez rendkívül időigényes és aprólékos munkát kíván.

Napjainkban a fent ismertetett okok miatt kezdenek elterjedni a gépi tanulásra alapozott tisztítási eljárások. Ha egy kellően nagy korpuszon meg tudjuk jelölni a törzsszöveget, akkor rálátással rendelkezünk arra, hogy milyen tagekkel asszociálhatjuk a lényeget és mivel a felesleges dolgokat.
Dr. Christian Kohlschütter fejlesztette ki a boilerpipe nevű Java könyvtárat, ami a fent leírt módon nagy hatékonysággal ismeri fel a lényeges tartalmakat. Saját tapasztalatunk szerint a könyvtár angol és német honlapok felhasználásával készített modellje nagy hatékonysággal alkalmazható magyar oldalak tartalmának kinyerésére is. Tartalomelemzésre kiváló eszköz, mivel a parsing nem minden esetben ad kielégítő eredményt. Megfelelő tréningkorpusz használatával nagyon jó eredményeket lehet elérni, akár a tartalom, akár kommentek vagy más fontos információk kinyerése terén is a boilerpipe használatával.
Elmélet: komplexitás és szabályok
 A múlt század ötvenes-hatvanas éveiben jelent meg a generatív grammatika, mely a nyelv formális, matematikai leírására törekedett. Ez a ma is aktív irányzat nagyon szofisztikált modellekkel képes leírni sok nyelvi jelenséget. Richard Montague alkotta meg a szintaktikai elemzéssel párhuzamosan felépülő szemantikát. Montague mondása, mely szerint formális és természetes nyelvek között nincs különbség szállóigévé vált és egészen a kilencvenes évekig nem nagyon kérdőjelezték meg. A formális modellek hiába adnak remek eredményeket lokális problémákra, ha nagy adathalmazon próbáljuk őket alkalmazni, akkor nem működnek olyan jól. A statisztikai elemzés ellenben pont akkor remekel, amikor sok adattal tudunk dolgozni. A kilencvenes években a kutatók elkezdtek az ilyen módszerek felé fordulni.
A múlt század ötvenes-hatvanas éveiben jelent meg a generatív grammatika, mely a nyelv formális, matematikai leírására törekedett. Ez a ma is aktív irányzat nagyon szofisztikált modellekkel képes leírni sok nyelvi jelenséget. Richard Montague alkotta meg a szintaktikai elemzéssel párhuzamosan felépülő szemantikát. Montague mondása, mely szerint formális és természetes nyelvek között nincs különbség szállóigévé vált és egészen a kilencvenes évekig nem nagyon kérdőjelezték meg. A formális modellek hiába adnak remek eredményeket lokális problémákra, ha nagy adathalmazon próbáljuk őket alkalmazni, akkor nem működnek olyan jól. A statisztikai elemzés ellenben pont akkor remekel, amikor sok adattal tudunk dolgozni. A kilencvenes években a kutatók elkezdtek az ilyen módszerek felé fordulni.
A mesterséges nyelvek szabályai viszonylag egyszerűek és a természetes nyelvekkel ellentétben előre dokumentáltak. Az "internet nyelve", a HTML jó példa arra, hogy a formális nyelvek esetében is rendkívüli mértékben megnövekedhet a komplexitás, melyet a generáló szabályok visszafejtésével nem egyszerű kezelni. A boilerpipe nagyon jó példa arra, hogy lokálisan nagyon jók a precíz szabályok, de bizonyos adatmennyiség felett megjelennek a hibák és hihetetlen mértékben megnő a komplexitás.
Hasonló folyamat zajlik napjainkban a szoftverfejlesztés terén is. Az ún. empirikus szoftverfejlesztés (empirical software engineering) kutatási irányzat célja, hogy empirikus vizsgálatokon keresztül rendszerezze a szoftverfejlesztés során használt jó és rossz gyakorlatokat. Ennek egyik bevett eszköze a forráskód-bázison (repository) alkalmazott szövegbányászat (l. pl. Mining Source Code Repositories at Massive Scale using Language Modeling).
Montague mondása úgy tűnik másképp igaz, mint ahogy anno gondolták. Úgy tűnik mikro- és makroszinten másképp viselkedik a nyelv, ami meglepő hasonlóságot mutat a fizika világával és a társadalomtudományokkal is.