Nagyon büszkék vagyunk Morvay Gergő gyakornokunkra, aki elnyerte az ELTE Alumni Alapítvány ösztöndíját. Gergő Szabó Martina kollégánkkal dolgozik szentiment- és emócióelemzés projektünkön.
![]()
A blog készítői a Precognox Kft. keretein belül fejlesztenek intelligens, nyelvészeti alapokra épülő keresési, szövegbányászati, big data és gépi tanulás alapú megoldásokat.
Az alábbi keresődoboz segítségével a Precognox által kezelt blogok tartalmában tudsz keresni. A kifejezés megadása után a Keresés gombra kattintva megjelenik vállalati keresőmegoldásunk, ahol további összetett keresések indíthatóak. A találatokra kattintva pedig elérhetőek az eredeti blogbejegyzések.
Ha a blogon olvasható tartalmak kapcsán, vagy témáink alapján úgy gondolod megoldással tudunk szolgálni szöveganalitikai problémádra, lépj velünk kapcsolatba a keresovilag@precognox.com címen.

Az opendata.hu egy ingyenes és nyilvános magyar adatkatalógus. Az oldalt önkéntesek és civil szervezetek hozták létre azzal a céllal, hogy megteremtsék az első magyar nyílt adatokat, adatbázisokat gyűjtő weblapot. Az oldalra szabadon feltölthetőek, rendszerezhetőek szerzői jogvédelem alatt nem álló, nyilvános, illetve közérdekű adatok.
 A long time ago, in a galaxy far, far away data analysts were talking about the upcoming new Star Wars movie. One of them has never seen any eposide of the two trilogies before, so they decided to make the movie more accessible to this poor fellow. See more...
A long time ago, in a galaxy far, far away data analysts were talking about the upcoming new Star Wars movie. One of them has never seen any eposide of the two trilogies before, so they decided to make the movie more accessible to this poor fellow. See more...

Kereső Világ by Precognox Kft. is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at http://kereses.blog.hu/.
Permissions beyond the scope of this license may be available at http://precognox.com/.
A Kereső Világ blogon közölt tartalmak a Precognox Kft. tulajdonát képezik. A tartalom újraközléséhez, amennyiben nem kereskedelmi céllal történik, külön engedély nem szükséges, ha linkeled az eredeti tartalmat és feltünteted a tulajdonos nevét is (valahogy így: Ez az írás a Precognox Kft. Kereső Világ blogján jelent meg). Minden más esetben fordulj hozzánk, a zoltan.varju(kukac)precognox.com címre írt levéllel.
Nevezd meg! - Ne add el! - Ne változtasd!
Nagyon büszkék vagyunk Morvay Gergő gyakornokunkra, aki elnyerte az ELTE Alumni Alapítvány ösztöndíját. Gergő Szabó Martina kollégánkkal dolgozik szentiment- és emócióelemzés projektünkön.
A Kereső Világ a ![]() Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
A Recession/R-indexet az 1990-es évek elején találták ki a The Economistnál azzal a céllal, hogy az USA gazdasági helyzetét, kiváltképp a válság időszakokat egy egyszerű mérőszámmal tudják előrejelezni. Ez az általuk kitalált index azt méri, hogy a „recession” - azaz „válság” vagy „recesszió” - szó hányszor jelenik meg negyedévente két befolyásos amerikai napilapban, a New York Timesban és a Washington Postban. Az index segítségével jelezni tudták az 1981-es, az 1990-es és a 2001-es válság kezdetét is. Azonban arra is volt példa, hogy tévedett a mutató, ugyanis az 1990-es évek eleji válság vége után még egy évvel is recessziót jeleztek vele. A The Economist próbálkozásán túl mások is megkíséreltek összehozni egy működő R-indexet. A sikeresek közé sorolhatjuk például Iselin és Siliverstovs svájci, illetve Maticek és Mayr német R-indexét. Utóbbiakon felbuzdulva úgy döntöttünk, mi is megpróbálunk létrehozni egy magyar R-indexet.
Az utóbbi évtizedben egyre többen használják az online elérhető szövegeket és a közösségi médiában található tartalmakat arra a célra, hogy gazdasági trendeket elemezzenek és jelezzenek előre. Egy társadalmi, gazdasági jelenség médiabeli megjelenése egyrészt az érdeklődésre és a közönséghangulatra reflektál, másrészt a médiabeli megjelenés is befolyásolja az emberek véleményét, fogalmi kereteiket és fókuszálja figyelmüket. Ez az oda-visszaható folyamat megfelelő mérőszámokat eredményezhet adott társadalmi, gazdasági jelenség médiabeli lecsapódása során. Emellett az információs technológiák megengedik, hogy valós időben kövessük a társadalmi, gazdasági történéseket az interneten, például a digitalizált újságokban, valamint hogy magunk is lenyomatot hagyjunk, például a keresések során. Tehát a különböző webes tartalmak olyan információknak a forrásai lehetnek, amelyeket hatékonyan és gyorsan lehet előrejelzési célokra használni. A társadalmi, de főleg gazdasági folyamatok online szöveges tartalmakkal történő elemzése során az utóbbi időben két csapásirány jellemző. Az egyik a digitalizált folyóiratokban található tartalmak használatára terjed ki, a másik pedig a Google Trendsről leszedett keresési adatokat próbálja előrejelző modellekbe belegyúrni.
Mi mindkét csapásiránnyal megpróbálkozunk a magyar R-index előállításakor. A befolyásos, sokak által olvasott online folyóiratként az Indexet választottuk ki, emellett a Google Trendsről is letöltöttük a kiválasztott kulcsszavak keresési idősorát.
ADATOK
Egy ország gazdaságának állapotáról adott ország GDP-jének segítségével kaphatunk általános képet, amely a gazdasági termelés mértékének meghatározására használt mérőszám. Mivel ennek mozgását szeretnénk előrejelezni, a GDP termelés volumenindexével dolgoztunk, amelyet az előző év azonos időszakához képest határoztak meg. Ennek idősorát a KSH honlapján értük el.
Az egyik féle R-indexhez az Index online hírportált használtuk, melynek saját keresője megengedi, hogy beállítsuk a keresőszót, a keresési időszakot, valamint a megfelelő rovatot. A dolog szépsége, hogy az idei évtől megváltozott az Index keresője annyiban, hogy már nem lehet a töredékszavas találatokat kiszűrni az összes találat közül. Így vannak a még 2014. III. negyedévében leszedett adataink, amelyek 2006. I. negyedévétől 2014. II. negyedévéig tartanak. Ezekből, mivel volt lehetőségünk, kiszűrtük a töredékszavas találatokat, mert úgy gondoltuk, ezek relevánsabb találatokat tartalmaznak. Emellett rendelkezésünkre állnak a 2015. januárban leszedett adatok, amelyek 2006. I. negyedévétől 2014. IV. negyedévéig tartanak és a töredékszavas találatokat is tartalmazzák, mivel már nincs opció ezek kiszűrésére. A következő kulcsszavakra kapott gyakorisági idősorokat használtuk fel az elemzéshez negyedéves bontásban:
Régi keresés szerint (töredékszavak nélkül):
Új keresés szerint (töredékszavakkal):
A másik féle R-indexhez a Google Trendsről töltöttük le az adott kulcsszavakhoz tartozó Magyarországra beállított idősorokat. Ezekből nem szedtünk le frisset, az idősorok 2006. I. negyedévétől 2014. II. negyedévéig tartanak. Mivel az idősorokat heti vagy havi bontásban lehet lekérni, az idősorokat negyedévesre aggregáltuk. A következő kulcsszavakra kapott standardizált gyakorisági idősorokat használtuk fel az elemzéshez negyedéves bontásban:
A GDP negyedéves értékét a KSH az adott negyedév utáni 3. hónap elején közli. Ezzel szemben az Indexes , valamint a Google Trendses R-indexet akár már az adott negyedév utáni első napon is elérhetjük. Így ha sikerülne létrehozni egy megfelelő R-indexet, a KSH-val szemben 2 hónapos előnnyel tudnánk megfelelő becslést adni a GDP adott negyedéves értékére.
MÓDSZERTAN
Az elemzés során követett módszertanban nagy segítséget jelentett David Iselin és Boriss Siliverstovs két tanulmánya, a The R-Word Index in Switzerland, valamint a Using Newspapers for Tracking the Business Cycle: A comparative study for Germany and Switzerland.
Elméleti modellként hozzájuk hasonlóan az autoregresszív osztott késleltetésű modellt (autoregressive distributed lag model, ARDL) használtuk (2. képlet), ezekbe ágyaztuk be az R-indexeket. A benchmark modellünk pedig az autoregresszív modell (1. képlet) volt.
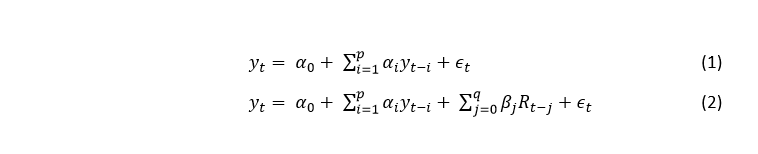
Az yt függő változó a GDP volumenváltozása az előző év azonos negyedévéhez képest. A t futóindex jelöli a GDP megfigyelési időpontjait, azaz t = 2006Q1, 2006Q2, …, 2014Q3. A magyarázó változók egyrészt a GDP idősorának időben késleltetett értékei, amelyeket az yt-i jelöl, ahol i = 1, 2, …, p. A függő változó időben eltolt értékeit az AR és ARDL modell is tartalmazza magyarázó változóként. Ezeket hívjuk autoregresszív tagoknak, ugyanis ezek jelzik, hogy a függő változó melyik múltbeli értékeivel korrelál. Az ARDL modell ezenkívül tartalmaz még egy tagot, amely helyére az előállított R-indexek jelenbeli vagy múltbeli értékei kerülhetnek (j = 0, 1, …, q). Ez a tag lehet azonos idejű a függő változóval vagy lehetnek időben eltoltak is, míg az autoregresszív tagok csak időben késleltetettek lehetnek, ezért hívják a modellt osztott késleltetésűnek.
Az adatok vizsgálata során úgy találtuk, hogy az AR(2)-es modell lesz a megfelelő benchmark modell (3. képlet) és az ARDL(2,0) volt az alkalmazási feltételeknek eleget tevő, az adatokra legjobban illeszkedő modell (4. képlet).
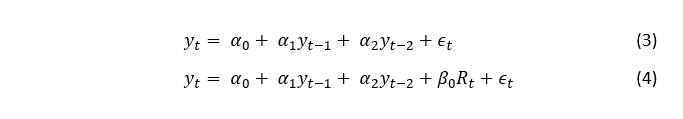
ELEMZÉS
A régebbi idősorok összesen 34 megfigyelésből állnak 2006. I. negyedévtől 2014. II. negyedévig, a hosszabb idősorok 36 megfigyelést tartalmaznak 2014. IV. negyedévéig. A GDP Idősora 2006. I. negyedévtől tart 2014. III. negyedévig (1. ábra).
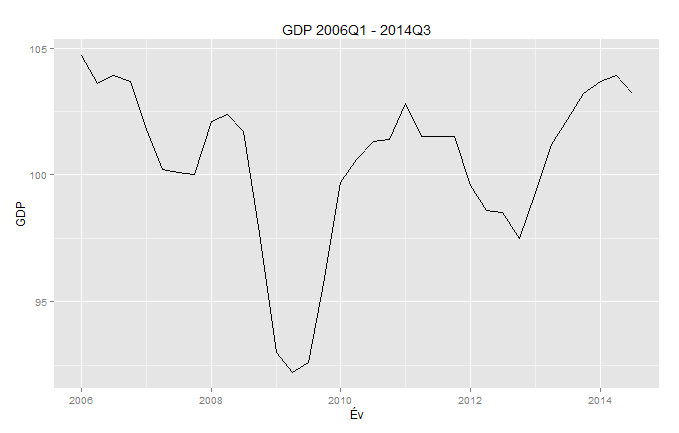
Ábra 1. A GDP volumenértékei az előző év azonos időszakához képest, 2006 I. negyedév- 2014. III. negyedév
A függő változó és a magyarázó változók korrelációjának vizsgálata során a következő változókat ítéltük a legjobbnak a modellalkotásra:
Az ARDL(2, 0) rendű modellek építésekor a 2. és 3. modellt ki kellett ejtenünk, ugyanis erős multikollinearitást jeleztek az egyes magyarázó változókhoz tartozó VIF értékek. A modellek többségénél szemmel úgy láttuk, gond lehet a reziduálisok normalitásával, noha a Shapiro-Wilk teszt alapján egyik esetben sem volt elvethető a nullhipotézis, miszerint a reziduálisok normális eloszlásúak. Ezért megnéztük, hogyan lehetne bootstrappelni az idősorokat. Egyrészt mivel szerettük volna megtartani az épített modelleket az újramintavételezés során, másrészt mivel a használt idősorok mindegyike autoregresszív és ezért nem használhattunk naiv bootstrapet, úgy döntöttünk, az egyes modellekben kapott standardizált reziduálisokat fogjuk bootstrappelni. Először elmentettük a modellek illesztett értékeit, valamint a reziduálisokat, majd a reziduálisokat 999-szer újramintavételeztük visszatevéssel. Ezután az illesztett értékeket és a reziduálisokat összeadtuk, és minden így kapott új idősorra újraillesztettük az ARDL(2,0) modellt.
Az összes Index rovatbeli, új keresés szerinti „recesszió” keresőszó gyakoriságával épített bootstrappelt modellek például a következőképp néztek ki (a fekete vonal az eredeti modell):
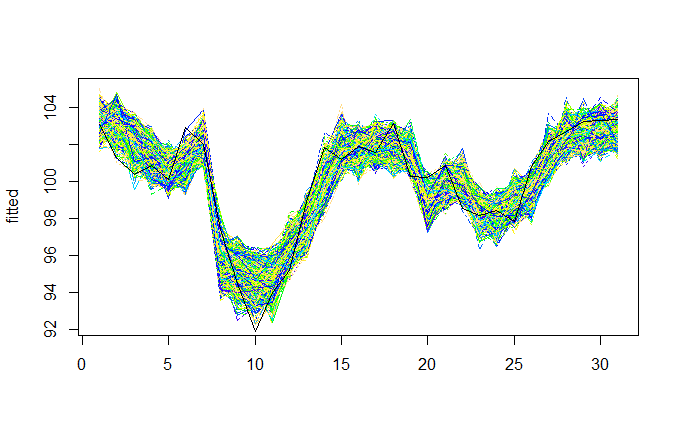
Ábra 2. Bootstrappelt idősorok - „recesszió” Index, összes rovat modell
A bootstrappelt minták alapján konfidenciaintervallumokat állítottunk a különböző statisztikákra, és nem találtunk az alkalmazási feltételeknek nem megfelelő modellt.
Végül a 3 legjobban illeszkedő modellt tartottuk meg, amelyek a következő R indexeket tartalmazzák:
A modellek előrejelzési pontosságát és a robusztusságát úgy vizsgáltuk, hogy kiválasztottunk egy rövidebb becslőablakot 2006 I. negyedévétől 2010. IV. negyedévéig, előrejeleztünk a következő időszakra, majd minden egyes lépésben bővítettük a becslőablakot egy negyedévvel és úgy jeleztünk előre. Ezt mind a három modell esetében megtettük 2014. II. negyedévig, valamint az AR(2) modell esetében is. Az előrejelzések a következő táblázat szerint alakultak:
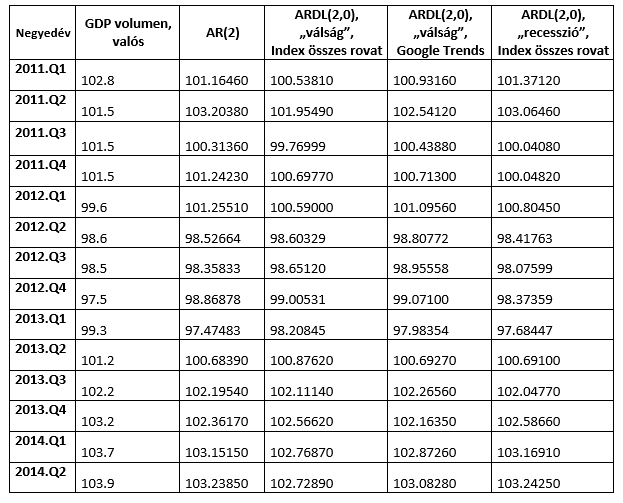
Táblázat 1. A modellek előrejelzései
Az előrejelzések pontosságát az átlagos hiba (ME), az átlagos négyzetes hiba négyzetgyöke (RMSE), az átlagos abszolút hiba (MAE), az átlagos százalékos hiba (MPE) és az átlagos abszolút százalékos hiba (MAPE) mérőszámokkal mértük, valamint a Diebold-Mariano teszttel vizsgáltuk meg, hogy szignifikánsan jobbnak bizonyul-e valamelyik modell előrejelzése az AR(2) modellénél. (Táblázat 2.)
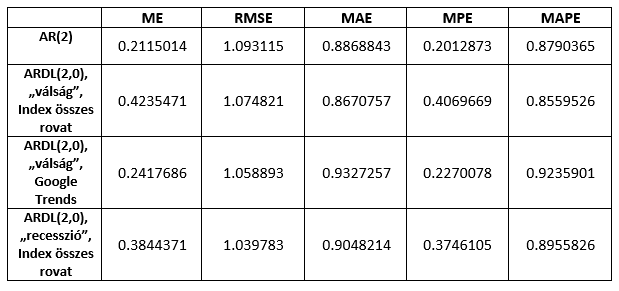
Táblázat 2. A modellek előrejelzésének pontossága
Az előrejelzés pontosságában csak az átlagos négyzetes hiba négyzetgyöke alapján láthatunk egyöntetű javulást a 2-es rendű autoregresszív modellhez képest. Ez a mérőszám jobban bünteti a nagyobb eltéréseket, tehát az AR(2) modell bár abszolút értékben átlagosan nagyjából ugyanannyit tévedett, mint a többi modell, de egyes esetekben viszonylag jobban eltért az előrejelzés értéke a valós értéktől, mint a többi modellnél. A Diebold-Mariano teszt alapján azonban nem utasíthatjuk el a nullhipotézist, miszerint a modellek becslési pontossága ugyanolyan. Így hát szomorúan konstatáltuk, hogy a szimpla szógyakorisági indexekkel nem sikerült statisztikailag jobb modellt összehoznunk.
EREDMÉNYEK
Az elemzés során három ARDL(2,0) modellt építettünk háromféle R-index modellbe foglalásával. A benchmark modellünk az AR(2) modell volt, amelynél nem sikerült a GDP volumenértékét becslő statisztikailag sikeresebb modellt építenünk. Emellett egyik modell sem bizonyult megfelelőnek a 2012. I. negyedévében bekövetkező kisebb válságidőszak előrejelzésére, noha az Indexről származó R-indexekkel bővített két modell is stagnálást jelzett. Összefoglalásképp tehát egyik modellt sem tartjuk célnak megfelelőnek. Annyi pozitívumot azonban megemlíthetünk, hogy 2014. IV. negyedévében az AR(2) és az Indexes "recesszió" kulcsszóval bővített ARDL(2, 0) modell szerint is nőtt a GDP, előbbi 102.1231, utóbbi 102.5951 volumenértéket jósol.
Na de azért nem adjuk fel! A szógyakorisági idősorok mellett ugyanis egyes kulcsszavakhoz a cikkeket is letöltöttük. Így a cikkek szentiment- illetve emócióértékeivel is futni fogunk még egy kört...
A Kereső Világ a ![]() Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
A deep learning buzzword lett, a big data területén lassan nem szexi az, ami nem alkalmaz valamilyen deep neural networköt vagy valami hasonlót. A Google Brain projekt kapcsán a mesterséges intelligencia reneszánszáról beszélnek sokan. Avval viszont kevesen vannak tisztában, hogy alapvetően a "forradalmian új" ötlet a kognitív tudományból érkezett, leánykori nevén konnekcionizmusnak és párhuzamos megosztott feldolgozásnak hívták, gyökerei egészen a számítástudomány hajnaláig, Neumann és Turing írásaihoz köthetők.
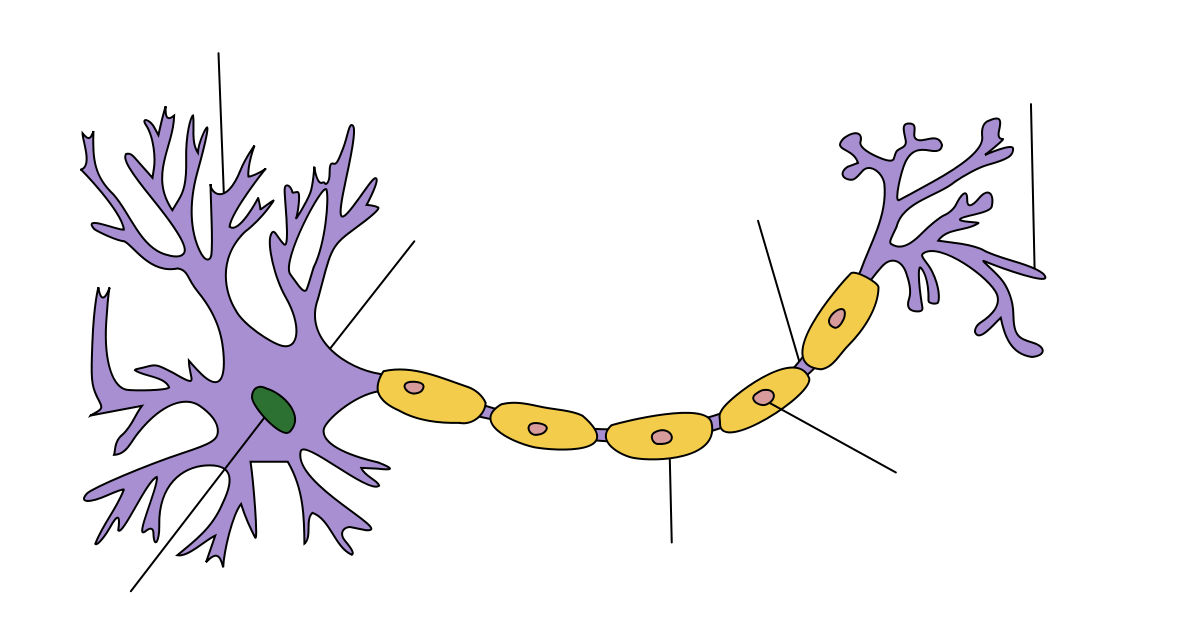
Neumann és a digitális számológépek
A első idealizált neuron modell McCulloch és Pitts írta le A logical calculus of the ideas immanent in nervous activity című dolgozatukban. Neumann eképpen foglalja össze ennek jelentőségét Az automaták általános és logikai elméletében:
McCulloch és Pitts elméletének fontos eredménye, hogy a fenti értelemben vett bármely olyan működés, amelyet véges számú "szó" segítségével logikailag szigorúan és egyértelműen egyáltalán definiálhatunk, ilyen formális neurális hálózattal meg is valósítható. [...] A McCulloch-Pitts-féle eredmény [...] bebizonyítja, hogy minden, amit kimerítően és egyértelműen szavakba lehet foglalni - alkalmas véges neuronhálózattal ipso facto realizálható is. Minthogy az állítás megfordítása nyilvánvaló, állíthatjuk, hogy bármely reális vagy elképzelt, teljesen és egyértelműen szavakba foglalható viselkedési mód leírásának a lehetőse és ugyanennek a véges formális neuronhálózattal való megvalósításának a lehetősége között nincs különbség. A két fogalom terjedelme egyenlő.
Neumann A számológép és az agy című írásában veti részletesebben össze a természetes és mesterséges automatákat, azaz az emberi agyat és a számítógépeket. A természetes automatákkal kapcsolatban külön kiemeli, hogy a mai szakzsargonnal élve meglepő módon jó hibatűrők, nem akasztja meg őket egy-egy "alkatrész" hiánya vagy a zavaros input. Megállapítja továbbá, hogy
[...] az adatok arra mutatnak, hogy természetes alkatelemekből felépített berendezések esetében nagyobb számú, bár lassúbb szerv alkalmazása részesíthető előnyben, míg mesterséges alkatelemekből felépített berendezések esetében előnyösebb, ha kevesebb, de gyorsabb szervet alkalmaznak. Így tehát azt várhatjuk, hogy egy hatékonyan megszervezett természetes automata (mint az emberi idegrendszer) minél több logikai (vagy információs) adat egyidejű felvételére és feldolgozására lesz berendezve, míg egy hatékonyan megszervezett nagy mesterséges automata (például egy nagy modern számológép) inkább egymás után látja majd el teendőit - egyszerre csak egy dologgal vagy legalábbis nem olyan sok dologgal foglalkozik. Röviden: a nagy és hatékony természetes automaták valószínűleg nagy mértékben párhuzamos működésűek, míg a nagy és hatékony mesterséges automaták inkább soros működésre rendezhetők be.
Neumann álma valóra válik a nyolcvanas években
A konnekcionizmus szülőapja Donald O. Hebb a múlt század negyvenes éveiben javasolta az idegrendszerhez hasonló modellek használatát először. Egy idealizált konnekcionista modellben az inputokat outputokhoz kötjük, az asszociáció erősségét is megadjuk (azaz mikor tüzel képzeletbeli neuronunk) és van egy nagyon egyszerű hálónk. Ezek közül a legegyszerűbbek pl. a AND, NAND és OR logikai függvényeket megvalósító hálózatok, mivel csupán két réteg (layer) mesterséges neuronnal megvalósíthatóak.
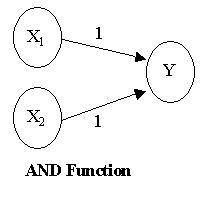
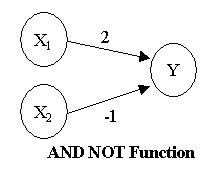
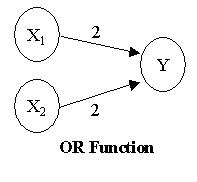
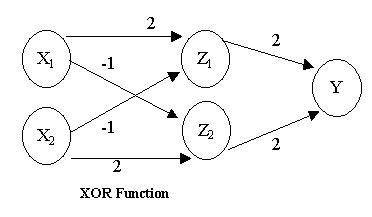
Kicsit bonyolultabb a XOR logikai kapu neurális megvalósítása, mivel ehhez már három rétegre van szükségünk. (Bővebben erről itt)
A nyolcvanas években Paul Smolensky (nyelvész olvasóinknak az optimalitáselméletből lehet ismerős a neve) köré kezdtek szerveződni a konnekcionisták, akik a kor színvonalához képest már nagyon jó számítógépes modellekkel dolgoztak. A kétrészes Parallel Distributed Processing tanulmánykötetben összegezték munkáikat 1987-ben, melyet még ma is szívesen hivatkoznak a terület kutatói. A PDP csoport alapvetően Neumann gondolatát vitte tovább a párhuzamos feldolgozást illetően. A gyakorlatban egy-egy ún. szubszimbolikus kognitív folyamatot modelleztek (pl. számjegyek felismerése, szófelismerés, a legbonyolultabb és egyben legismertebb magasabb szintű folyamatot modellező kísérlet a Rumelhart és McCelland On the learning of past tenses of English verbs tanulmányban leírt modell). Habár nagyon sikeres volt a csoport és figyelemre méltó eredményeket értek el, a kutatási irányzat a kilencvenes években kiesett az ipar látóköréből és megmaradt akadémiai hobbinak.
Hogyan reprezentál és tanul egy konnekcionista rendszer?
Már Neumann számára is felmerült ez a kérdés. Az automaták általános és logikai elméletében a Smolensky által javasolt megoldást előlegezte meg:
A logikai műveleteket [...] olyan eljárással kell tárgyalni, amelyek kicsi, de nem zérus valószínűséggel megengednek kivételeket (hibás működést. Mindez olyan elméletekhez fog vezetni, amelyek sokkal kevésbé mereven "minden vagy semmi" természetűek, mint a fomális logika a múltban és a jelenben. [...] Ez a termodinamika, elsősorban abban a formájában, amelyet Boltzman alkotott meg.
Smolensky On the proper teatment of connectionism (magyarul A konnekcionizmus helyes kezeléséről in. Pléh (szerk.): Kognitív tudomány) c. tanulmányában tesz kísérletet a PDP határainak és módszereinek kijelölésére. A Neumann által kifejtett következtetést Smolensky a Legjobb Illeszkedés Elvének hívja:
Egy adott bemenet esetén a szubszimbolikus rendszer kimenete egy következtetéshalmaz, amely mint egész a legjobb illeszkedést mutatja az inputhoz, abban a statisztikai értelemben, amelyet a rendszer kapcsolataiban tárolt statisztikai tudás határoz meg.
Ez nem más mint egy Boltzmann-gép, ami egy olyan H harmóniafüggvény, ami bemenethez illeszkedő kimeneteket rangsorolja az előállításukhoz szükséges komputációs "hőmérséklet" vagy energiaszint szerint. (Ezeket a Boltzmann-gépeket tökéletesítette kiszámíthatósági szempontból Geoffry Hinton, a deep learning alapítója) Képletek helyett nézzük meg inkább egy gyakorlati példán keresztül mit is jelent ez!
Rakéták és Cápák
Clark A megismerés építőköveiben McCelland, Rumelhart és Hinton(!) példáján keresztül nagyon szemléletesen mutatja meg, hogyan is reprezentálható tudás egy hálózatban és mit jelent a Legjobb Illeszkedés Elve szerint következtetni. Ehhez először nézzünk meg két New York utcáin tevékenykedő banda felépítését.

A táblázat hálózatban így néz ki.
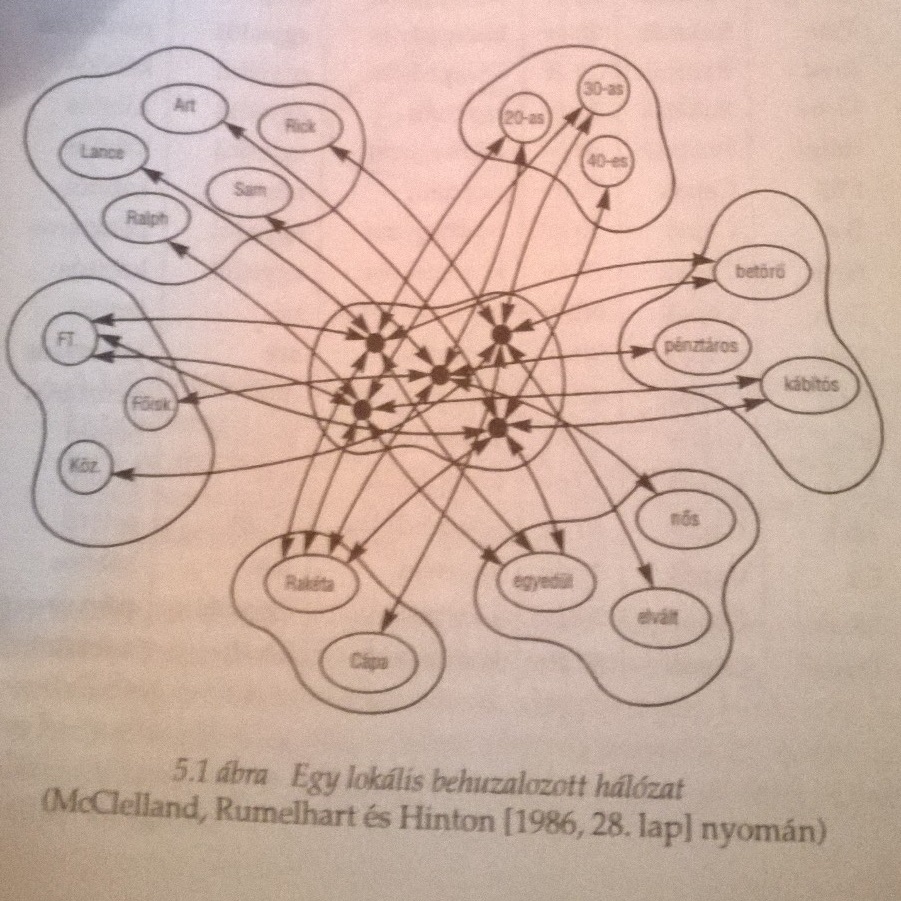
Tegyük fel, hogy meg akarjuk tudni milyen egy harmincas cápa. Ekkor a bemeneti aktivitások tovaterjednek és a legerősebb kapcsolatok irányában. Úgy tűnik, ezzel megkapjuk a prototipikus harmincas cápát, aki elvált, betörő és középiskolát végzett...
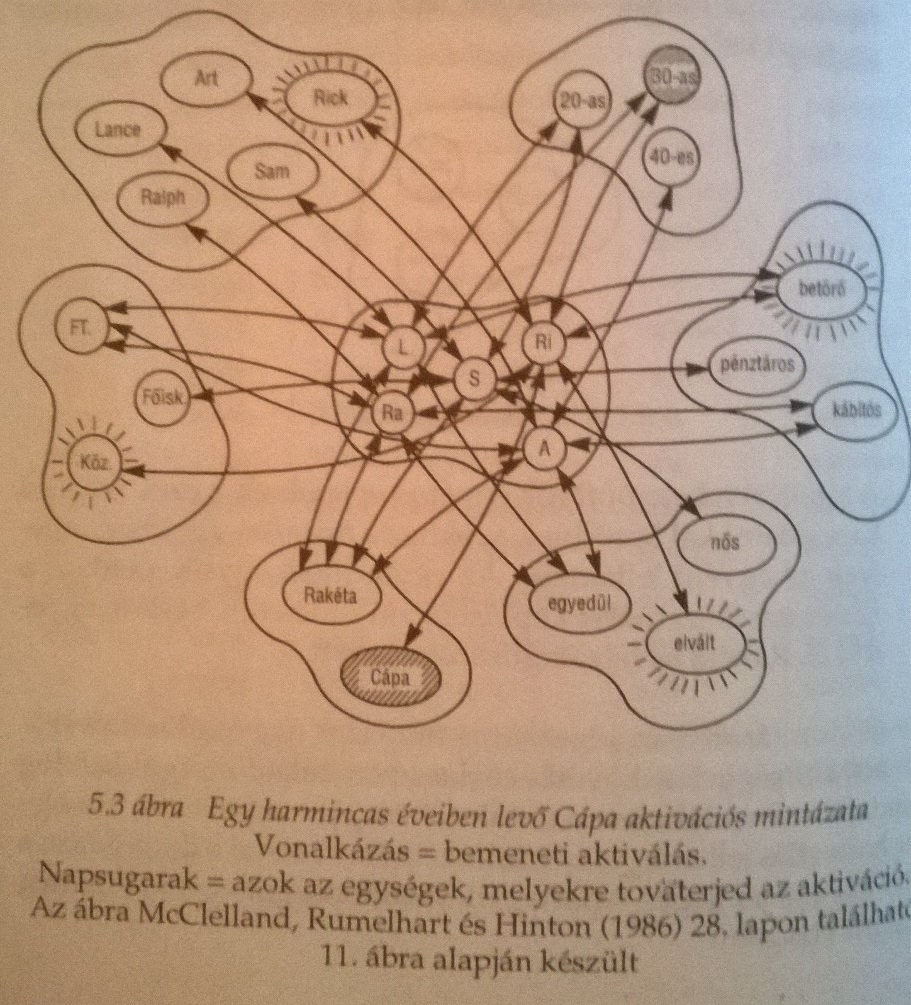
Jól látható, hogy a konnekcionista hálónk bizonyos mértékig tűri a hibákat. Ha valamiért pl. a családi állapotra vonatkozó információ nem elérhető, akkor is egész jól közelíti az optimumot az eredmény, hiszen a betörő és a középiskolai végzettség továbbra is aktív marad.
Geoffry Hinton és a deep learning
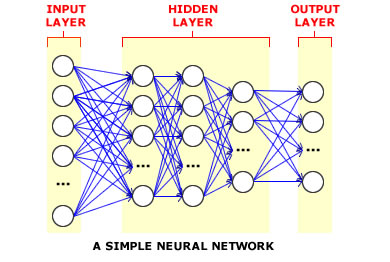
Hinton a pszichológia felől érkezett a mesterséges intelligenciába, érhető hogy a PDP csoportnál találta magát. Itt a Boltzmann-gépek tökéletesítése során érdeklődése a számítástudományi alkalmazások felé fordult és a kilencvenes években egy sor új eljárást dolgoztak ki a neurális hálókkal történő tanulásra. Mindeközben erős tudományszervező tevékenységet folytatott és Kanadát igazi neurális háló nagyhatalommá tette.
A deep learning neve onnét ered, hogy a XOR kapu három rétegénél jóval több ún. rejtett réteggel (hidden layer) dolgozik ez ilyen elven megvalósított rendszer. A mély rétegek többféle architektúrával dolgoznak (a deep learing szócikk a Wikipedia-n nagyon jó a témában!) és általános problémájuk hogy rendkívül számításigényesek és sok adattal adnak igazán jó eredményeket. Ezért sokkal inkább mérnöki bravúr egy deep learnign rendszer, mint kognitív modell! A deep learning kutatói általában GPGPU technológiával dolgoznak, nagyon gyakran olcsó, játékosoknak szánt GPU-kkal felszerelt gépeken. A Google kutatói által publikál Large Scale Distributed Deep Networks paper alaposan megkritizálta ezt a paradigmát s egyben körvonalazta, hogyan lehet big data infrastruktúrán megvalósítani egy deep learning rendszert. Napjainkban sorra indulnak a deep learning startupok - meglátjuk mire jutnak. Nem árt észben tartani, hogy a mesterséges intelligenciában két nagyobb ún. "AI winter"-t tartanak nyilván, számtalan kisebb mellett, melyeket hatalmas lelkesedés előzött meg és jókora csalódás követett!
A Kereső Világ a ![]() Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Miközben a magyar (és úgy általában a világ kevésbé eleresztett felén élő) tudósok kalózkodásra kényszerülnek, hogy képben legyenek a kurrens szakirodalommal, a nagy szaklapokban egyre több kétes tanulmány kerül be és egyre többen aggódnak a tudományos munka minősége miatt. Mindkét problémára megoldás a nyílt tudomány!
Mi a probléma?
Az áltudományos szövegek generálása lassan külön sporttá vált, s nem is olyan régen a Springer és az IEEE több mint 120 darab cikket vont vissza, mert bebizonyosodott hogy gépileg generált nonszensz a tartalmuk. Christopher Chabris és tsai az általános intelligencia genetikai hátterét vizsgáló kutatásokat elemezve arra jutottak, hogy a legtöbb feltételezett asszociáció valószínűleg hamis. A pszichológusok egyik kedvenc kísérleti eljárása az előfeszítés (priming), de az utóbbi időben az ilyen eljárást alkalmazó kutatások jelentős részéről bebizonyosodott hogy nem megismételhetőek.

Úgy tűnik, a tudományt remekül szolgáló peer review rendszer nem működik igazán. A fenti hibák nem jelentik azt, hogy a tudományos tudás leértékelődött, vagy hogy el kellene vetnünk. A megoldást sokan a nyílt adatokban, a kutatáshoz kapcsolódó workflow-k és szoftverek megosztásában és a beszámolók szabad közlésében látják.
Hol érdemes kezdeni?

A Mozilla Science Lab különböző tudományterületeknek készít szoftvereket, nagyon aktívak a tudásmegosztás terén. A tudományos programozással foglalkozók és/vagy pythonisták körében régóta népszerű Software Carpentry-vel kötött együttműködésüknek köszönhetően egyre több kutató tanulhatja meg, miképp lehet spagetti kód helyett rendes programokat írni.


A Center for Open Science ingyenes statisztikai konzultációt biztosít és több tudományterületen is reprodukciós programot indított. Az alapítvány fejleszti az Open Science Framework-öt, ami egy online, ingyenesen elérhető tudományos workflow és projekt menedzsment eszköz.
![]()
A rOpenSci az R statisztikai programozási nyelvhez nyújt könyvtárakat melyek megkönnyítik a reprodukálható kutatást, a nyílt adatokhoz való hozzáférést, az kutatási adatok publikálását és vizualizációját.

A DOAJ egy egyszerű és könnyen használható keresőfelületet nyújt a legtöbb minőségi nyílt hozzáférésű szaklaphoz.

A magyar opendata.hu célja, hogy kereshetővé tegye a magyar vonatkozású nyílt adatokat, beleértve ebbe a tudományos adatokat is. Az Open Knowledge Foundation által fejlesztett CKAN szoftver fut az oldalon, amit különféle kormányzati és civil szervezetek használnak adatok megosztására és elérhetővé tételére. Az oldalon lehetőség van az adatokat linkelni, vagy akár fel is tölteni.
Miért nem jó a régi bevált rendszer?
A tudomány szeretne meritokratikus lenni. De ha csak az fér hozzá a tudáshoz, akinek megfelelő az anyagi háttere, akkor félő, nem a legjobb, legokosabb emberek fognak tudásunk gyarapításán dolgozni. Egyre hosszabb időt kell tanulással tölteni ahhoz, hogy valaki a tudományos közösség tagjává válhasson, ami egyre drágább mulatság. A tudományos adatok és workflow-k megosztásával a legjobb eljárásokat ismerhetik meg a tanulók, nem kell adatokat gyűjteniük, vagy kis projektjeikkel beszállhatnak egy nagy kutatásba is.
Az ipar számára is egyre fontosabb a tudomány. Innováció csak a kutatói szféra és az ipar együttműködéséből születhet. Saját területünknél maradva, a nyílt forráskódú szoftverek nélkül rendkívül magas lenne belépési költsége egy-egy új cégnek. Nyílt adatok nélkül, mint pl. a UCI Machine Learning Repository, nem tudnánk kiértékelni az elkészült termékeinket, sőt gyakran tréning adatunk sem lenne. Az olyan nyílt hozzáférésű szaklapok, mint a Journal of Machine Learning Research vagy a Computational Linguistics, a kis és közepes vállalkozásoknál dolgozók nem férnének hozzá a terület legújabb eredményeihez.

A tudomány egyre nagyobb szerepet játszik a kormányzati döntéshozatalban is. Miközben szakértők döntik el, milyen új gyógyszereket engedélyeznek, hol épüljön atomerőmű, vagy éppen a szegénység felszámolását célzó randomizált kontrollált vizsgálatokat végeznek kormányzati szervek, a laikusok számára ezek egyre inkább érthetetlenek. A nyílt tudomány megteremti a társadalmi kontroll lehetőségét, az ismeretterjesztés alapja lehet és a különféle citizen science mozgalmak bevonhatják az érdeklődő laikusokat és hobbistákat a tudományos munkába.
A Kereső Világ a ![]() Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Alig pár hónapja ment át egy program a Turing-teszten, a mesterséges intelligencia kutatói már azon agyalnak, miként lehetne életszerűbbé tenni ezen teszteket. Habár a Turing-teszten jól szereplő programok (mint látni fogjuk) "tudása" nem éppen hatalmas, valahogy intuitíven jónak érezzük Turing alapötletét; egy intelligens ágens képes társalogni, kérdésekre válaszolni csak úgy mint a Jeopardy-t 2011-ben megnyerő Watson.
Kacsák és tesztek
Turing tesztjének több változata van, az alap helyzet háromszereplős imitációs játék. Ebben egy kérdező egy géppel és egy emberrel beszélget s a társalgás végén meg kell mondania melyik partnere humán. A gép akkor nyer, ha rá esik a kérdező választása.
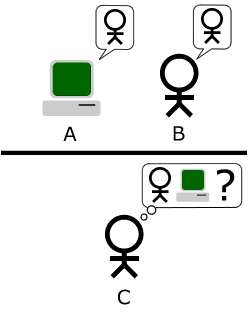
A bonyolultabb verzió szerint több kérdező vesz részt a játékban és akkor tekinthető intelligensnek a gép, ha a vizsgálatot végző személyek jelentős hányadát győzi meg arról, hogy "ő" ember.
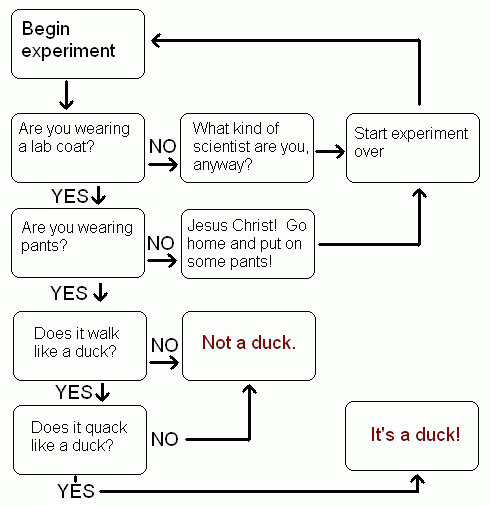
A Turing-teszt tkp. egy ún. duck test, hiszen annyit mond; ami úgy viselkedik mint egy ember, az intelligens és fordítva, ami intelligens, az úgy viselkedik mint egy ember.
Dennett szerint teljesen racionális, ha vélekedéseket, vágyakat, stb. tulajdonítunk valaminek, ami kellően komplex módon viselkedik. Ez nem jelenti azt, hogy ténylegesen intencionális, értelmes rendszerrel állunk szemben ilyenkor. Searle Az eleme, az agy és a programok világa című esszéjében a mesterséges intelligencia erős programjának nevezi azt az elképzelést, mely szerint egy megfelelően programozott számítógépre tekinthetünk úgy, mint egy elmére. Ez azzal jár, hogy elfogadjuk az agy és az elme kettősségét, hiszen a programok függetlenek az őket futtató gépektől. Searle szerint azonban az ilyen elme nem rendelkezhet intencionalitással, hiszen szimplán szimbólumokat manipulál. Hiába tűnik úgy, hogy intencionális a rendszer, ez csak a programozóinak köszönhető. Erről szól az előző posztunkban ismertetett kínai szoba gondolatkísérlet. De miről is szól Turing tesztje? Mit tesztel és miért? Hogyan lehet átmenni ezen a teszten, anélkül, hogy az intelligencia legkisebb jelét is mutassuk?
Mond gyorsan hogy Entscheidungsproblem!

Mindenki tudja, hogy Turingnak volt egy képzeletbeli gépe, a Turing-gép. Azután lett több nagyon konkrét gépe, melyekkel sikeresen törték fel Bletchley Parkban a német Enigma kódokat. Azt már kevesebben tudják, hogy Turing gépe a 19. század végén kezdődő matematikai és logikai válság lezárásának csodálatos pontja. A matematika megalapozásának programja a 19. században kezdődött, ennek terméke Frege munkássága, ami megalapozta a modern logikát (s egyben a számítástudományt). Sajnos Frege teljesen lemaradt arról, hogy learathassa a babérokat, mivel nagy összegző művében, Az aritmetika alaptörvényeiben Russel ellentmondást fedezett fel (Russel erről szóló levelét mellékletként leközölte Frege!) Innét elindult a hajsza a matematika megalapozása után. 1928-ban Hilbert fogalmazta meg, milyen követelményeket kell kielégítenie a szilárd alapoknak, ez a híres Entscheidungsproblem, vagy eldöntésprobléma. Ez tkp. azt követeli meg, hogy egy rendes algoritmusunk legyen, ami minden jólformált kijelentésre képes megadni hogy helyes-e, vagy másképp fogalmazva, levezethető-e rendszerünk axiómáiból. Gödel tétlei (mert kettő van neki) bebizonyították egy konzisztens rendszerben vannak igaz, de nem bizonyítható állítások s az ilyen rendszerek konzisztenciája nem bizonyítható a rendszeren belül. Gödel eredményei alig három évvel Hilbert problémájának ismertetése után jelentek meg. Turing egy kicsit tovább várt, mivel őt az izgatta, hogy mi "kiszámítható", azaz mit lehet levezetni, már ha érdeklődésünket a levezethető, bizonyítható állításokra korlátozzuk. Ez tulajdonképpen a matematikai tevékenység formalizálása, ami a híres Church-Turing tézishez vezetett. A Turing-gép nem más, mint annak formalizált leírása, hogy mit lehet bizonyítani, ezért lett az ezt bemutató tanulmány címe On Computable Numbers, with an Application to the Entscheidungsproblem. A Breaking the Code-ban a zseniális Derek Jacobi pár szóban így foglalja össze, mit is jelentett ez a kis dolgozat.
Gondolkodás, nyelv, más elmék
Turing, Church és Gödel tételei lényegében visszacsempészik a pszichologizmust a logikába. No nem abban az értelemben, hogy a modus ponens aktuális pszichikai állapotunk függvényében fog működni, hanem visszatért vele az intuíció. Wittgenstein előadásaira járva Turing elgondolkodhatott azon, hogy miért is kell formalizálni és stabilnak tudni a matematikai alapjait.
Wittgenstein:... Think of the case of the Liar. It is very queer in a way that this should have puzzled anyone — much more extraordinary than you might think... Because the thing works like this: if a man says 'I am lying' we say that it follows that he is not lying, from which it follows that he is lying and so on. Well, so what? You can go on like that until you are black in the face. Why not? It doesn't matter. ...it is just a useless language-game, and why should anyone be excited?
Turing: What puzzles one is that one usually uses a contradiction as a criterion for having done something wrong. But in this case one cannot find anything done wrong.
W: Yes — and more: nothing has been done wrong, ... where will the harm come?
T: The real harm will not come in unless there is an application, in which a bridge may fall down or something of that sort.
W: ... The question is: Why are people afraid of contradictions? It is easy to understand why they should be afraid of contradictions, etc., outside mathematics. The question is: Why should they be afraid of contradictions inside mathematics? Turing says, 'Because something may go wrong with the application.' But nothing need go wrong. And if something does go wrong — if the bridge breaks down — then your mistake was of the kind of using a wrong natural law. ...C. Diamond (ed.) Wittgenstein's Lectures on the Foundations of Mathematics
A fenti párbeszéd analógiája mondhatjuk, hogy akkor az ellentmondásmentesség egyben azt is jelenti, hogy működőképes is valami? Lehet olyan, hogy ellentmondásos, vagy eldönthetetlen és ennek ellenére működik valami? Elvileg igen, hiszen erről szólna (az eredeti kontextusától persze elszakítva) a Gödel-tétel. Ez lenne az intuíció, olyan igazságok megtalálása, melyek nem levezethetőek.

Az intuíció itt nem valami misztikus dolog, hanem valami, ami a Turing-gép keretein kívül van. De honnét tudjuk akkor, hogy valami többre képes mint egy Turing-gép? Hogyan állíthatjuk valakiről, hogy hozzánk hasonló intuícióval rendelkezik? Ezt nevezik a filozófusok a más elmék (other minds) problémájának. Wittgenstein privát nyelv argumentuma szerint ahhoz hogy feltételezzünk más elméket, szükség van a nyelvre.
"Mi lenne, ha az emberek nem nyilvánítanák meg fájdalmaikat (nem nyögnének, nem fintorítanák el az arcukat stb.)? Akkor egy gyereknek nem lehetne a 'fogfájás' szó használatát megtanítani." - Nos, tegyük fel, hogy a gyermek egy zseni, és maga talál ki egy szót arra, amit érez! - Ekkor persze ezzel a szóval nem tudná megértetni magát. - Szóval ő érti a nevet, de senkinek nem tudja jelentését megmagyarázni? - De mit is jelent, hogy 'megnevezte a fájdalmát'? - Hogy csinálta, hogy megnevezte a fájdalmat? ! És, akármit is tett - mi vele a célja? - Amikor azt mondják: "Nevet adott annak, amit érzett", akkor elfelejtik, hogy a nyelvben már sok mindennek készen kell állnia ahhoz, hogy a puszta megnevezésnek értelme legyen. És ha arról beszélünk, hogy valaki a fájdalomnak nevet ad, akkor itt a "fájdalom" szó grammatikája az, ami elő van készítve; jelzi azt a posztot, ahová majd az új szó kerül.
Wittgenstein: Filozófiai vizsgálódások
Habár lehetséges, hogy valaminek nyelvi megnyilvánulások nélkül intelligenciát tulajdonítsunk, az intencionalitás, miképp a Wittgenstein idézet rávilágít, társas és nyelvi természetű.
ELIZA, a legjobb beszélgetőpartner
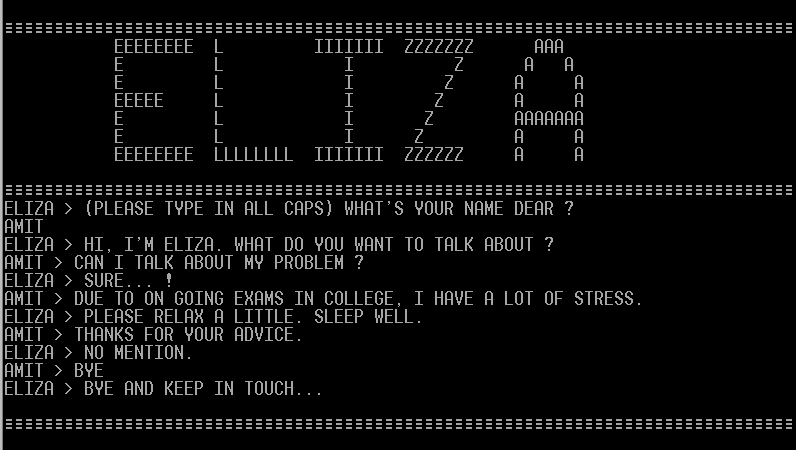
Joseph Weizenbaum ELIZA programja a Turing-tesztre készülő programok őse. Az ELIZA-t leíró klasszikus tanulmányából vett példa szerint kb. így néz ki egy beszélgetés vele (a nagybetűs mondatok a géptől származnak).
Men are all alike.
IN WHAT WAY?
They're always bugging us about something or other.
CAN YOU THINK OF A SPECIFIC EXAMPLE?
Well, my boyfriend made me come here.
YOUR BOYFRIEND MADE YOU COME HERE
He says I'm depressed much of the time.
I AM SORRY TO HEAR YOU ARE DEPRESSED
It's true. I am unhappy
DO YOU THINK COMING HERE WILL HELP YOU NOT TO BE UNHAPPY
I need some help, that much seems certain.
WHAT WOULD IT MEAN TO YOU IF YOU GOT SOME HELP
Perhaps I could learn to get along with my mother.
TELL ME MORE ABOUT YOUR FAMILY
My mother takes care of me.
WHO ELSE IN YOUR FAMILY TAKES CARE OF YOU
My father.
YOUR FATHER
You are like my father in some ways.
WHAT RESEMBLANCE DO YOU SEE
You are not very aggressive but I think you don't want me to notice that.
WHAT MAKES YOU THINK I AM NOT VERY AGGRESSIVE
You don't argue with me.
WHY DO YOU THINK I DON'T ARGUE WITH YOU
You are afraid of me.
DOES IT PLEASE YOU TO BELIEVE I AM AFRAID OF YOU
My father is afraid of everybody.
WHAT ELSE COMES TO YOUR MIND WHEN YOU THINK OF YOUR FATHER
Bullies.
DOES THAT HAVE ANYTHING TO DO WITH THE FACT THAT YOUR BOYFRIEND MADE YOU COME HERE
Persze egy idő után fárasztó tud lenni ELIZA és könnyen ki lehet ejteni a szerepéből, de nagyon sokáig el lehet vele játszani. "Tudása" és fantasztikus "együttérzése" ún mintaillesztő szabályoknak köszönhető, melyek az ún. rogeriánus pszichológia visszakérdező módszerét imitálják. Norvig Paradigms of Artificial Intelligence Programming c. könyvében egy ELIZA típusú programhoz a következő szabályokat adja meg.
Minden (((?* ?x) W (?* ?y)) egy helyettesítő szabályt ad meg, pl. a (((?* ?x) computer (?* ?y)) akkor lép életbe, ha a bemenet tartalmazza a 'computer' szót, ami aktiválja a
válaszok valamelyikét (pl. véletlenszerűen választva). Sokkal inkább tűnik ez trükknek, mint valódi intelligenciának!
Az ELIZA effect nevet kapta ezért az a jelenség, amikor gépeket emberi tulajdonsággal ruházunk fel pusztán viselkedésük alapján. Maga Weizenbaum is erre a jelenségre akarta felhívni a figyelmet programjával, ahogy tanulmányának bevezetőjében írja:
It is said that to explain is to explain away. This maxim is nowhere so well fulfilled as in the area of computer programming, especially in what is called heuristic programming and artificial intelligence. For in those realms machines are made to behave in wondrous ways, often sufficient to dazzle even the most experienced observer. But once a particular program is unmasked, once its inner workings are explained in language sufficiently plain to induice understanding, its magic crumbles away; it stands revealed as a mere collection of procedures, each quite comprehensible. The observer says to himself "I could have written that". With that thought he moves the program in question from the shelf marked "intelligent" to that reserved for curios, fit to be discussed only with people less enlightened that he. The object of this paper is to cause just such a reevaluation of the program about to be "explained". Few programs ever needed it more.
Annyi bizonyos, hogy a Turing a tesztet az intelligencia szükséges és elégséges feltételeinek tekintette, azaz ha valami intelligens, akkor átmegy a teszten, ha nem, akkor megbukik. Úgy tűnik, bővítenünk kell a feltételek körét!
A Kereső Világ a ![]() Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.