A Recession/R-indexet az 1990-es évek elején találták ki a The Economistnál azzal a céllal, hogy az USA gazdasági helyzetét, kiváltképp a válság időszakokat egy egyszerű mérőszámmal tudják előrejelezni. Ez az általuk kitalált index azt méri, hogy a „recession” - azaz „válság” vagy „recesszió” - szó hányszor jelenik meg negyedévente két befolyásos amerikai napilapban, a New York Timesban és a Washington Postban. Az index segítségével jelezni tudták az 1981-es, az 1990-es és a 2001-es válság kezdetét is. Azonban arra is volt példa, hogy tévedett a mutató, ugyanis az 1990-es évek eleji válság vége után még egy évvel is recessziót jeleztek vele. A The Economist próbálkozásán túl mások is megkíséreltek összehozni egy működő R-indexet. A sikeresek közé sorolhatjuk például Iselin és Siliverstovs svájci, illetve Maticek és Mayr német R-indexét. Utóbbiakon felbuzdulva úgy döntöttünk, mi is megpróbálunk létrehozni egy magyar R-indexet.
Az utóbbi évtizedben egyre többen használják az online elérhető szövegeket és a közösségi médiában található tartalmakat arra a célra, hogy gazdasági trendeket elemezzenek és jelezzenek előre. Egy társadalmi, gazdasági jelenség médiabeli megjelenése egyrészt az érdeklődésre és a közönséghangulatra reflektál, másrészt a médiabeli megjelenés is befolyásolja az emberek véleményét, fogalmi kereteiket és fókuszálja figyelmüket. Ez az oda-visszaható folyamat megfelelő mérőszámokat eredményezhet adott társadalmi, gazdasági jelenség médiabeli lecsapódása során. Emellett az információs technológiák megengedik, hogy valós időben kövessük a társadalmi, gazdasági történéseket az interneten, például a digitalizált újságokban, valamint hogy magunk is lenyomatot hagyjunk, például a keresések során. Tehát a különböző webes tartalmak olyan információknak a forrásai lehetnek, amelyeket hatékonyan és gyorsan lehet előrejelzési célokra használni. A társadalmi, de főleg gazdasági folyamatok online szöveges tartalmakkal történő elemzése során az utóbbi időben két csapásirány jellemző. Az egyik a digitalizált folyóiratokban található tartalmak használatára terjed ki, a másik pedig a Google Trendsről leszedett keresési adatokat próbálja előrejelző modellekbe belegyúrni.
Mi mindkét csapásiránnyal megpróbálkozunk a magyar R-index előállításakor. A befolyásos, sokak által olvasott online folyóiratként az Indexet választottuk ki, emellett a Google Trendsről is letöltöttük a kiválasztott kulcsszavak keresési idősorát.
ADATOK
Egy ország gazdaságának állapotáról adott ország GDP-jének segítségével kaphatunk általános képet, amely a gazdasági termelés mértékének meghatározására használt mérőszám. Mivel ennek mozgását szeretnénk előrejelezni, a GDP termelés volumenindexével dolgoztunk, amelyet az előző év azonos időszakához képest határoztak meg. Ennek idősorát a KSH honlapján értük el.
Az egyik féle R-indexhez az Index online hírportált használtuk, melynek saját keresője megengedi, hogy beállítsuk a keresőszót, a keresési időszakot, valamint a megfelelő rovatot. A dolog szépsége, hogy az idei évtől megváltozott az Index keresője annyiban, hogy már nem lehet a töredékszavas találatokat kiszűrni az összes találat közül. Így vannak a még 2014. III. negyedévében leszedett adataink, amelyek 2006. I. negyedévétől 2014. II. negyedévéig tartanak. Ezekből, mivel volt lehetőségünk, kiszűrtük a töredékszavas találatokat, mert úgy gondoltuk, ezek relevánsabb találatokat tartalmaznak. Emellett rendelkezésünkre állnak a 2015. januárban leszedett adatok, amelyek 2006. I. negyedévétől 2014. IV. negyedévéig tartanak és a töredékszavas találatokat is tartalmazzák, mivel már nincs opció ezek kiszűrésére. A következő kulcsszavakra kapott gyakorisági idősorokat használtuk fel az elemzéshez negyedéves bontásban:
Régi keresés szerint (töredékszavak nélkül):
- „válság”, minden rovatban
- „válság”, Gazdaság rovatban
- „válság”, Belföld rovatban
- „recesszió”, minden rovatban
- „recesszió”, Gazdaság rovatban
- „recesszió”, Belföld rovatban
- „csőd”, minden rovatban
- „árfolyam”, minden rovatban
- „részvény”, minden rovatban
Új keresés szerint (töredékszavakkal):
- „recesszió”, minden rovatban
- „recesszió”, Gazdaság rovatban
A másik féle R-indexhez a Google Trendsről töltöttük le az adott kulcsszavakhoz tartozó Magyarországra beállított idősorokat. Ezekből nem szedtünk le frisset, az idősorok 2006. I. negyedévétől 2014. II. negyedévéig tartanak. Mivel az idősorokat heti vagy havi bontásban lehet lekérni, az idősorokat negyedévesre aggregáltuk. A következő kulcsszavakra kapott standardizált gyakorisági idősorokat használtuk fel az elemzéshez negyedéves bontásban:
- „válság”
- „válság magyarország”
- „recesszió”
- „csőd”
- „árfolyam”
- „részvény”
A GDP negyedéves értékét a KSH az adott negyedév utáni 3. hónap elején közli. Ezzel szemben az Indexes , valamint a Google Trendses R-indexet akár már az adott negyedév utáni első napon is elérhetjük. Így ha sikerülne létrehozni egy megfelelő R-indexet, a KSH-val szemben 2 hónapos előnnyel tudnánk megfelelő becslést adni a GDP adott negyedéves értékére.
MÓDSZERTAN
Az elemzés során követett módszertanban nagy segítséget jelentett David Iselin és Boriss Siliverstovs két tanulmánya, a The R-Word Index in Switzerland, valamint a Using Newspapers for Tracking the Business Cycle: A comparative study for Germany and Switzerland.
Elméleti modellként hozzájuk hasonlóan az autoregresszív osztott késleltetésű modellt (autoregressive distributed lag model, ARDL) használtuk (2. képlet), ezekbe ágyaztuk be az R-indexeket. A benchmark modellünk pedig az autoregresszív modell (1. képlet) volt.
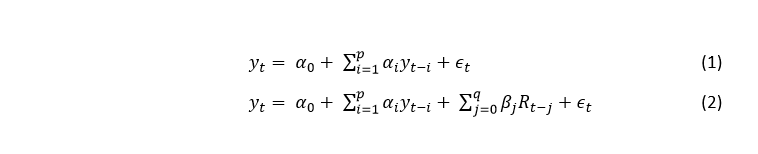
Az yt függő változó a GDP volumenváltozása az előző év azonos negyedévéhez képest. A t futóindex jelöli a GDP megfigyelési időpontjait, azaz t = 2006Q1, 2006Q2, …, 2014Q3. A magyarázó változók egyrészt a GDP idősorának időben késleltetett értékei, amelyeket az yt-i jelöl, ahol i = 1, 2, …, p. A függő változó időben eltolt értékeit az AR és ARDL modell is tartalmazza magyarázó változóként. Ezeket hívjuk autoregresszív tagoknak, ugyanis ezek jelzik, hogy a függő változó melyik múltbeli értékeivel korrelál. Az ARDL modell ezenkívül tartalmaz még egy tagot, amely helyére az előállított R-indexek jelenbeli vagy múltbeli értékei kerülhetnek (j = 0, 1, …, q). Ez a tag lehet azonos idejű a függő változóval vagy lehetnek időben eltoltak is, míg az autoregresszív tagok csak időben késleltetettek lehetnek, ezért hívják a modellt osztott késleltetésűnek.
Az adatok vizsgálata során úgy találtuk, hogy az AR(2)-es modell lesz a megfelelő benchmark modell (3. képlet) és az ARDL(2,0) volt az alkalmazási feltételeknek eleget tevő, az adatokra legjobban illeszkedő modell (4. képlet).
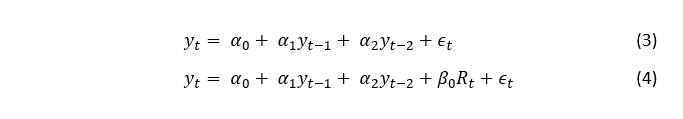
ELEMZÉS
A régebbi idősorok összesen 34 megfigyelésből állnak 2006. I. negyedévtől 2014. II. negyedévig, a hosszabb idősorok 36 megfigyelést tartalmaznak 2014. IV. negyedévéig. A GDP Idősora 2006. I. negyedévtől tart 2014. III. negyedévig (1. ábra).
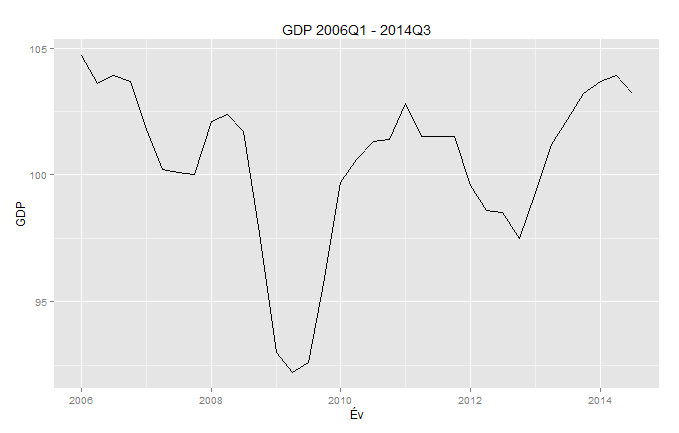
Ábra 1. A GDP volumenértékei az előző év azonos időszakához képest, 2006 I. negyedév- 2014. III. negyedév
A függő változó és a magyarázó változók korrelációjának vizsgálata során a következő változókat ítéltük a legjobbnak a modellalkotásra:
- „válság”, Index, minden rovatban, régi keresés szerint
- „recesszió”, Index, minden rovatban, régi keresés szerint
- „recesszió”, Index, Gazdaság rovatban, régi keresés szerint
- „recesszió”, Index, minden rovatban, új keresés szerint
- „recesszió”, Index, Gazdaság rovatban, új keresés szerint
- „válság”, Google Trends
Az ARDL(2, 0) rendű modellek építésekor a 2. és 3. modellt ki kellett ejtenünk, ugyanis erős multikollinearitást jeleztek az egyes magyarázó változókhoz tartozó VIF értékek. A modellek többségénél szemmel úgy láttuk, gond lehet a reziduálisok normalitásával, noha a Shapiro-Wilk teszt alapján egyik esetben sem volt elvethető a nullhipotézis, miszerint a reziduálisok normális eloszlásúak. Ezért megnéztük, hogyan lehetne bootstrappelni az idősorokat. Egyrészt mivel szerettük volna megtartani az épített modelleket az újramintavételezés során, másrészt mivel a használt idősorok mindegyike autoregresszív és ezért nem használhattunk naiv bootstrapet, úgy döntöttünk, az egyes modellekben kapott standardizált reziduálisokat fogjuk bootstrappelni. Először elmentettük a modellek illesztett értékeit, valamint a reziduálisokat, majd a reziduálisokat 999-szer újramintavételeztük visszatevéssel. Ezután az illesztett értékeket és a reziduálisokat összeadtuk, és minden így kapott új idősorra újraillesztettük az ARDL(2,0) modellt.
Az összes Index rovatbeli, új keresés szerinti „recesszió” keresőszó gyakoriságával épített bootstrappelt modellek például a következőképp néztek ki (a fekete vonal az eredeti modell):
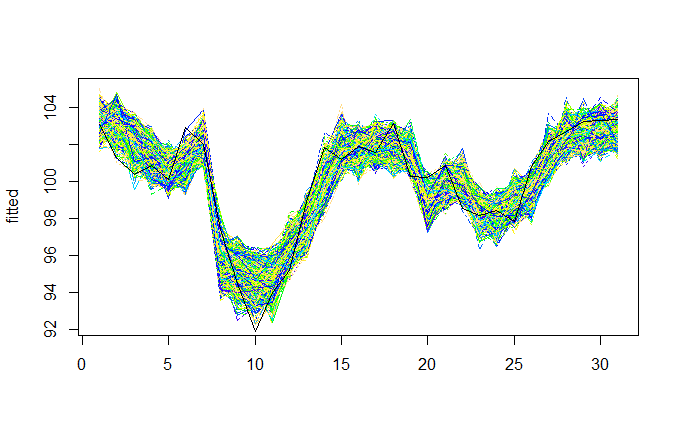
Ábra 2. Bootstrappelt idősorok - „recesszió” Index, összes rovat modell
A bootstrappelt minták alapján konfidenciaintervallumokat állítottunk a különböző statisztikákra, és nem találtunk az alkalmazási feltételeknek nem megfelelő modellt.
Végül a 3 legjobban illeszkedő modellt tartottuk meg, amelyek a következő R indexeket tartalmazzák:
- „válság”, Index, minden rovatban, régi keresés szerint
- „recesszió”, Index, minden rovatban, új keresés szerint
- „válság”, Google Trends
A modellek előrejelzési pontosságát és a robusztusságát úgy vizsgáltuk, hogy kiválasztottunk egy rövidebb becslőablakot 2006 I. negyedévétől 2010. IV. negyedévéig, előrejeleztünk a következő időszakra, majd minden egyes lépésben bővítettük a becslőablakot egy negyedévvel és úgy jeleztünk előre. Ezt mind a három modell esetében megtettük 2014. II. negyedévig, valamint az AR(2) modell esetében is. Az előrejelzések a következő táblázat szerint alakultak:
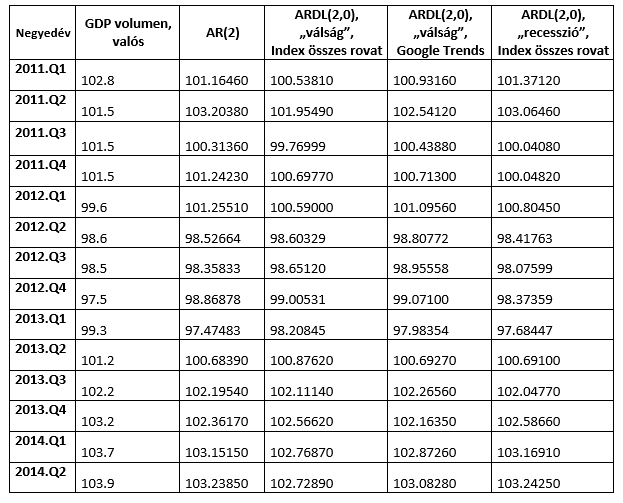
Táblázat 1. A modellek előrejelzései
Az előrejelzések pontosságát az átlagos hiba (ME), az átlagos négyzetes hiba négyzetgyöke (RMSE), az átlagos abszolút hiba (MAE), az átlagos százalékos hiba (MPE) és az átlagos abszolút százalékos hiba (MAPE) mérőszámokkal mértük, valamint a Diebold-Mariano teszttel vizsgáltuk meg, hogy szignifikánsan jobbnak bizonyul-e valamelyik modell előrejelzése az AR(2) modellénél. (Táblázat 2.)
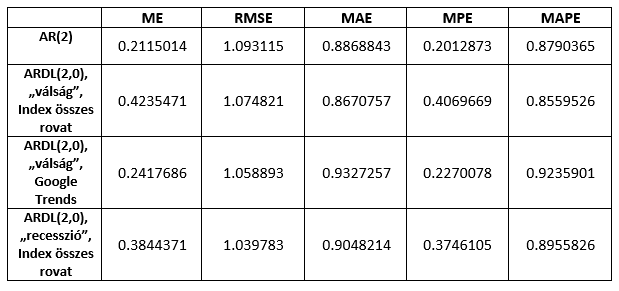
Táblázat 2. A modellek előrejelzésének pontossága
Az előrejelzés pontosságában csak az átlagos négyzetes hiba négyzetgyöke alapján láthatunk egyöntetű javulást a 2-es rendű autoregresszív modellhez képest. Ez a mérőszám jobban bünteti a nagyobb eltéréseket, tehát az AR(2) modell bár abszolút értékben átlagosan nagyjából ugyanannyit tévedett, mint a többi modell, de egyes esetekben viszonylag jobban eltért az előrejelzés értéke a valós értéktől, mint a többi modellnél. A Diebold-Mariano teszt alapján azonban nem utasíthatjuk el a nullhipotézist, miszerint a modellek becslési pontossága ugyanolyan. Így hát szomorúan konstatáltuk, hogy a szimpla szógyakorisági indexekkel nem sikerült statisztikailag jobb modellt összehoznunk.
EREDMÉNYEK
Az elemzés során három ARDL(2,0) modellt építettünk háromféle R-index modellbe foglalásával. A benchmark modellünk az AR(2) modell volt, amelynél nem sikerült a GDP volumenértékét becslő statisztikailag sikeresebb modellt építenünk. Emellett egyik modell sem bizonyult megfelelőnek a 2012. I. negyedévében bekövetkező kisebb válságidőszak előrejelzésére, noha az Indexről származó R-indexekkel bővített két modell is stagnálást jelzett. Összefoglalásképp tehát egyik modellt sem tartjuk célnak megfelelőnek. Annyi pozitívumot azonban megemlíthetünk, hogy 2014. IV. negyedévében az AR(2) és az Indexes "recesszió" kulcsszóval bővített ARDL(2, 0) modell szerint is nőtt a GDP, előbbi 102.1231, utóbbi 102.5951 volumenértéket jósol.
Na de azért nem adjuk fel! A szógyakorisági idősorok mellett ugyanis egyes kulcsszavakhoz a cikkeket is letöltöttük. Így a cikkek szentiment- illetve emócióértékeivel is futni fogunk még egy kört...