Google
A legnépszerűbb általános kereső a 2006-os adatok szerint 25 milliárd weboldalt, és 1,3 milliárd képet gyűjtött be és indexelt le. A jelenlegi mérete már közel járhat a 100 milliárdhoz, és 2008 közepén jelentették be a fejlesztők blogjában, hogy a link-index mérete elérte az 1 billiót, ami 1012, de ezek persze nem mind vezetnek egyedi weboldalakhoz. (A kereső a nevét egyébként a googol szóról kapta 1998 szeptemberében, ami a 10 századik hatványát jelenti a matematikai szakzsargonban.)
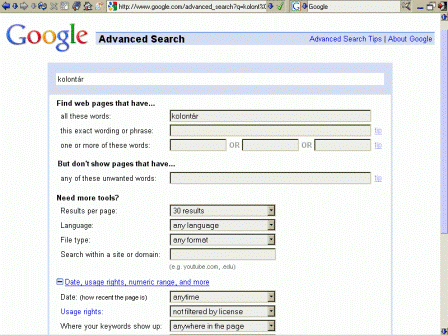 Ekkora adatbázisban való kereséshez már nagyon kifinomult keresőnyelv és felület kell, de tekintve hogy a felhasználók többsége nem képzett információkereső, ezeket - amennyire lehet - elrejti előlük a Google és sok mindent automatikusan, a keresett szavakat "értelmezve" és a keresőkérdést átszerkesztve végez el a háttérben. Az egysoros keresőmező a Google sikerének egyik fontos eleme volt, és a szolgáltatás ismertetője szerint még a gyakorlott használói is csak az esetek 5%-ban veszik igénybe az Advanced Search űrlap által kínált plusz funkciókat. A keresőfelület kevésbé ismert lehetőségeiről ugyanitt az Advanced Search Tips alatt tájékozódhatunk, de egy jó összefoglaló van az angol Wikipédiában is.
Ekkora adatbázisban való kereséshez már nagyon kifinomult keresőnyelv és felület kell, de tekintve hogy a felhasználók többsége nem képzett információkereső, ezeket - amennyire lehet - elrejti előlük a Google és sok mindent automatikusan, a keresett szavakat "értelmezve" és a keresőkérdést átszerkesztve végez el a háttérben. Az egysoros keresőmező a Google sikerének egyik fontos eleme volt, és a szolgáltatás ismertetője szerint még a gyakorlott használói is csak az esetek 5%-ban veszik igénybe az Advanced Search űrlap által kínált plusz funkciókat. A keresőfelület kevésbé ismert lehetőségeiről ugyanitt az Advanced Search Tips alatt tájékozódhatunk, de egy jó összefoglaló van az angol Wikipédiában is.
Érdemes magát a Google felületet is magyarról angolra váltani a Keresési beállítások alatt, mert az eredeti google.com oldalon általában több lehetőség áll rendelkezésre, mint az egyes nyelvi változatoknál, és sokszor csak itt jelennek meg a kísérleti fázisban levő fejlesztések. Például nagyon hasznos az angol űrlapnál, hogy miközben beírjuk az egyes sorokba a szavakat és beállítjuk a megfelelő menüpontokat, a felső sorban azonnal megjelennek az ezeknek megfelelő operátorok és prefixek, így könnyen megtanulhatjuk őket. Két operátor viszont nem látszik ezen az űrlapon sem: a + jel, amivel kényszeríthetjük a Google keresőjét, hogy az utána írt szó mindenképpen és pontosan a beírt formában szerepeljen a találatként visszaadott oldalakon (így olyan stopword-ökre is tudunk keresni, amiket amúgy figyelmen kívül hagyna, valamint megakadályozhatjuk a hasonló szóalakok automatikus kereséséből adódó érdektelen találatokat: pl. "koros emberek", "+kóros emberek", "+koros emberek"); valamint a * karakter, amellyel szavakat helyettesíthetünk (pl. az allintitle:Google * keresésnél elsőként a Google különböző szolgáltatásai jelennek meg).
Ezek egy része a kereséshez kapcsolódik, így érdemes megismerni őket: a Google Suggest a mások által beírt keresőkérdések és (amennyiben be vagyunk jelentkezve és a Web History funkciót engedélyeztük) a saját korábbi kereséseink alapján ajánl fel javaslatokat az egysoros keresőmező vagy a toolbar használatakor, így egyrészt gyorsíthatjuk a kérdés bevitelét, mert elég csak néhány karaktert begépelni, majd választani a listából, másrészt időnként hasznos alternatívákat fedezhetünk így fel. Persze a "gépi intelligencia" mulatságos javaslatokat is produkál néha, például az élet nagy kérdéseire.
A találati listát személyre szabhatjuk a SearchWiki és a Subscribed Links segítségével (ezt a Search settings alatt állíthatjuk be), amennyiben van Google fiókunk és be vagyunk rá éppen jelentkezve. Előbbivel a nekünk fontos találatokat csillagokkal jelölhetjük meg (korábban akár át is rendezhettük a találati listát), utóbbival pedig egyes nagyobb referenszforrásokat emelhetünk a találati listánkba (ezek a 4. helyen jelennek meg, amennyiben van onnan találat). A GoogleAlert szolgáltatással automatikus "témafigyelést" kérhetünk: a beírt keresőkérdésnek megfelelő új hírek, blogbejegyzések, weblapok, videók címeit a rendszer naponta vagy hetente elküldi az e-mail címünkre.
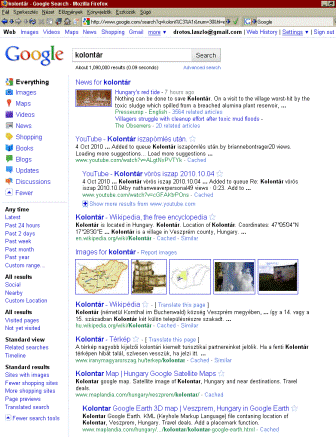 A Google találati listája már alapesetben is sok lehetőséget kínál (pl. automatikus fordítás, gyorsnézet vagy HTML nézet, tárolt változat (cache), hasonló oldalak), de további beállításokat is kérhetünk (Show options...), és itt a szűrők (típus, dátum, megnézett/még nem látott oldalak) mellett a lista megjelenését is módosíthatjuk (Timeline, Page previews) és egyéb segítségek is megjelennek (Related searches, Translated search). A találati lista tetején megjelenő About ... results szám egy nagyon közelítő érték (a gyorsabb válasz kedvéért a keresőszavak indexbeli gyakorisága alapján becsli meg a rendszer, vagyis nem azt számolja meg, hogy ténylegesen hány weblapon fordulnak elő), és valójában csak a legjobbnak ítélt 1000 tételt keresi ki, majd ezekből a nagyon hasonlókat törli, továbbá egy site-ról csak néhány találatot ad vissza, így a végső, végiglapozható eredménylista mindig ezer alatt van.
A Google találati listája már alapesetben is sok lehetőséget kínál (pl. automatikus fordítás, gyorsnézet vagy HTML nézet, tárolt változat (cache), hasonló oldalak), de további beállításokat is kérhetünk (Show options...), és itt a szűrők (típus, dátum, megnézett/még nem látott oldalak) mellett a lista megjelenését is módosíthatjuk (Timeline, Page previews) és egyéb segítségek is megjelennek (Related searches, Translated search). A találati lista tetején megjelenő About ... results szám egy nagyon közelítő érték (a gyorsabb válasz kedvéért a keresőszavak indexbeli gyakorisága alapján becsli meg a rendszer, vagyis nem azt számolja meg, hogy ténylegesen hány weblapon fordulnak elő), és valójában csak a legjobbnak ítélt 1000 tételt keresi ki, majd ezekből a nagyon hasonlókat törli, továbbá egy site-ról csak néhány találatot ad vissza, így a végső, végiglapozható eredménylista mindig ezer alatt van.
A központi kereső mellett a Google-t "honosíthatjuk" is: a Google Custom Search oldalon egy olyan keresődobozt állíthatunk be, amely csak az általunk megadott site-okon keres, a Google Desktop programot telepítve pedig a saját gépünkön is ugyanúgy - és csaknem olyan gyorsan - tudunk megtalálni bármit, mint a weben. Érdemes még a Google Toolbar-t is kipróbálni, mert egyéb kényelmi szolgáltatások mellett olyan keresést segítő funkciókat is tartalmaz, mint a Sidewiki vagy a Custom Buttons.
Yippy Search és Polymeta
Az eredetileg pittsburgh-i székhelyű és Clusty névre hallgató metakereső 2004-ben indult a Vivísimo cég technológiájára alapozva; majd a szolgáltatást 2010 májusában felvásárolta a floridai Yippy Inc. vállalat. A Yippy Search több webes keresőgépet (pl. Bing) és információforrást (pl. New York Times) kérdez le és az eredményeket - a duplumok kiszűrése után - összefésüli és csoportosítja, vagyis klaszterezi. Ezek a csoportok azután további alcsoportokra oszlanak (a kék + gombokra kattintva) és ezekből válogatva a felhasználó egyre relevánsabb eredményeket kap. Egyszerre csak néhány száz tételt mutat meg a rendszer, vagyis megkíméli a felhasználót a tízezres vagy milliós találati listák által okozott frusztrációtól - aki amúgy sem szokott 2-3 találati oldalnál többet megnézni. Hogy az éppen kiválasztott klaszter mely forrásokból és mennyi találatot tartalmaz, azt a details feliratra illetve a sources fülre kattintva tudjuk megnézni; a sites fül alatt pedig domain nevek szerint böngészhetjük az eredményhalmazt.
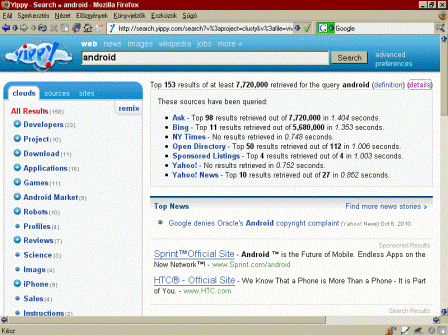 Minden találat mellett három szürke ikon van: az első új ablakban/fülön nyitja meg az adott weblapot; a második (kis nagyító képe) ugyanezt a találati listán belül teszi meg, egyfajta "gyorsnézetet" nyújtva így; a harmadikkal pedig megnézhetjük, hogy az adott találat mely klaszter(ek)ben fordul elő - ezeket ugyanis átszínezi a bal oldali hasábban.
Minden találat mellett három szürke ikon van: az első új ablakban/fülön nyitja meg az adott weblapot; a második (kis nagyító képe) ugyanezt a találati listán belül teszi meg, egyfajta "gyorsnézetet" nyújtva így; a harmadikkal pedig megnézhetjük, hogy az adott találat mely klaszter(ek)ben fordul elő - ezeket ugyanis átszínezi a bal oldali hasábban.
A Yippy-vel nemcsak weblapokat, hanem híreket, képeket, blogokat, állásajánlatokat, termékeket stb. is kereshetünk, erre külön szűrők szolgálnak az oldal tetején - sőt a preferences alatt magunk is összeállíthatunk továbbiakat (természetesen csak a rendszer által lekérdezett forrásokból). A Google-szerű, mindent egyben láttató találati listákhoz képest a klaszter-technológia lényegesen hatékonyabb olyankor, amikor nem egy konkrét információt keresünk, hanem egy témában szeretnénk elmélyedni és megtalálni az azzal kapcsolatos néhány tucat igazán fontos forrást.
A Yippy keresője eszköztárként is beépíthető a böngészőnkbe, néhány ügyes funkcióval (pl. mini-módban a Google mellett másodlagos keresőként használhatjuk). Érdekes még a kísérleti állapotú fejlesztések közt a Yippy Cloud Creator, mellyel címkefelhőt készíthetünk egy általunk megadott keresőkérdés klasztereiből, és bemásolhatjuk azt a weboldalunkba vagy blogunkba. Így "előregyártott" kereséseket kínálhatunk fel különféle felhasználói csoportoknak, akik az őket érdeklő címkére kattintva megkapják a klaszterbe tartozó találatok aktuális listáját a Yippy-től.
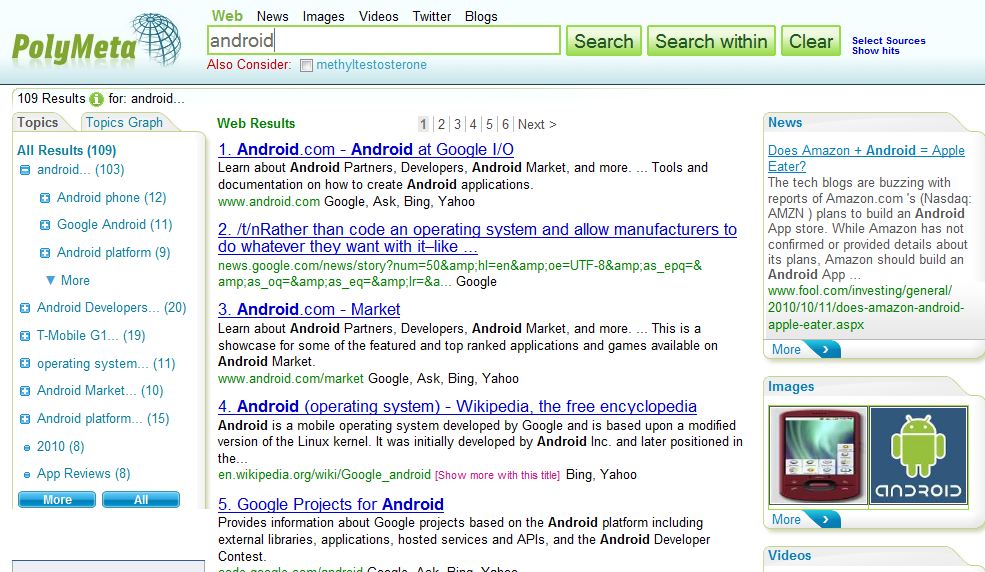 Hasonlóan működik a magyar WebLib által fejlesztett polymeta.com kereső is. Az eredmények itt is dinamikusan létrejövő klaszterekben jelennek meg, melyek által az eredmények tövább szűkíthetők, illetve megjelenik a különböző eredmények csoportosított találati listája is (képek, hírek, stb). A polymeta.hu pedig kifejezetten magyar nyelvi feldolgozásra és magyar nyelvű találatok megjelenítésére optimalizált.
Hasonlóan működik a magyar WebLib által fejlesztett polymeta.com kereső is. Az eredmények itt is dinamikusan létrejövő klaszterekben jelennek meg, melyek által az eredmények tövább szűkíthetők, illetve megjelenik a különböző eredmények csoportosított találati listája is (képek, hírek, stb). A polymeta.hu pedig kifejezetten magyar nyelvi feldolgozásra és magyar nyelvű találatok megjelenítésére optimalizált.
Picsearch
A 2000-ben alapított svéd vállalkozás a világ egyik legnagyobb képkeresőjét működteti az interneten. Jelenleg már több mint 3 milliárd kép adatait gyűjtötték be a webről és tették visszakereshetővé. Ebben számban a nagy képmegosztó (pl. Flickr) és más közösségi oldalak (pl. Facebook) képanyaga nincs is benne, mert a Picsearch ezeket nem indexeli le.
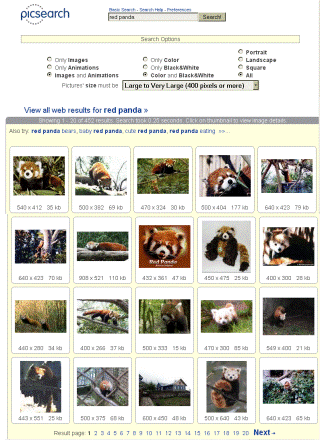 Ugyan maga a felület nem sok opciót kínál és a keresőnyelv szintaxisa is kimerül a + (kötelező szó) és a - (kizárandó szó) jelek használatában, de az alkalmazott - és titokban tartott - technológiának köszönhetően a találatok többnyire relevánsak, mert szigorúbban szűr a Google képkeresőjénél. A bélyegképek gyorsan megjelennek, és ha valamelyikre rákattintunk, akkor egy osztott képernyőn egyszerre látjuk a kép adatait és az eredeti weblapot, ahonnan származik. Az Advanced Search menüpont alatt néhány szűrővel tovább szűkíthetjük a találati halmazt (állóképek vagy animációk, színes vagy fekete-fehér képek, álló/fekvő téglalap- vagy négyzet-alakúak, illetve különféle méretűek). A találatokat tartalmazó táblázat tetején további kifejezéseket is ajánl a rendszer a keresés pontosításához, sőt azt is lehetővé teszi, hogy a keresőkérdésünket a leindexelt weblapok szövegében is lefuttassuk. Hasznos, bár az oldal alján eléggé eldugott, az Image Directory, ahol több ezer témakörből válogathatunk. A Picsearch keresőjét is beépíthetjük eszköztárként a böngészőnkbe.
Ugyan maga a felület nem sok opciót kínál és a keresőnyelv szintaxisa is kimerül a + (kötelező szó) és a - (kizárandó szó) jelek használatában, de az alkalmazott - és titokban tartott - technológiának köszönhetően a találatok többnyire relevánsak, mert szigorúbban szűr a Google képkeresőjénél. A bélyegképek gyorsan megjelennek, és ha valamelyikre rákattintunk, akkor egy osztott képernyőn egyszerre látjuk a kép adatait és az eredeti weblapot, ahonnan származik. Az Advanced Search menüpont alatt néhány szűrővel tovább szűkíthetjük a találati halmazt (állóképek vagy animációk, színes vagy fekete-fehér képek, álló/fekvő téglalap- vagy négyzet-alakúak, illetve különféle méretűek). A találatokat tartalmazó táblázat tetején további kifejezéseket is ajánl a rendszer a keresés pontosításához, sőt azt is lehetővé teszi, hogy a keresőkérdésünket a leindexelt weblapok szövegében is lefuttassuk. Hasznos, bár az oldal alján eléggé eldugott, az Image Directory, ahol több ezer témakörből válogathatunk. A Picsearch keresőjét is beépíthetjük eszköztárként a böngészőnkbe.
Összeállította: Drótos László, Magyar Elektronikus Könyvtár



 Napjainkban az Internetes keresés egyik legnagyobb rákfenéje a spamek megnövekedett száma. Szinte kategóriától függetlenül vezethetik a keresőszoftverek a gyanútlanabb felhasználókat olyan oldalakra, melyek valójában csak csaliként használják a keresett terminusokat, hogy saját magukat reklámozzák, még akkor is ha egyébként semmi közük a keresés céljához, pusztán előfordul a kifejezés az adott oldalon.
Napjainkban az Internetes keresés egyik legnagyobb rákfenéje a spamek megnövekedett száma. Szinte kategóriától függetlenül vezethetik a keresőszoftverek a gyanútlanabb felhasználókat olyan oldalakra, melyek valójában csak csaliként használják a keresett terminusokat, hogy saját magukat reklámozzák, még akkor is ha egyébként semmi közük a keresés céljához, pusztán előfordul a kifejezés az adott oldalon. vertikális dimenziót. A szimpla horizontális keresés útján pusztán a szavakra koncentrálunk, annak használatától, szövegkörnyezetétől függetlenül. Olyan ez, mintha elmennénk viharos időben vadászni, és mindenre lőnénk ami mozog. A Blekko az új dimenzió, a slashtagek hozzáadásával olyan, mintha vadászkutyát is vinnénk magunkkal. Megtalálja a vadra / találati oldalra jellemző nyomokat / slashtageket, így vadászatunk / keresésünk lényegesen hatékonyabb lesz.
vertikális dimenziót. A szimpla horizontális keresés útján pusztán a szavakra koncentrálunk, annak használatától, szövegkörnyezetétől függetlenül. Olyan ez, mintha elmennénk viharos időben vadászni, és mindenre lőnénk ami mozog. A Blekko az új dimenzió, a slashtagek hozzáadásával olyan, mintha vadászkutyát is vinnénk magunkkal. Megtalálja a vadra / találati oldalra jellemző nyomokat / slashtageket, így vadászatunk / keresésünk lényegesen hatékonyabb lesz.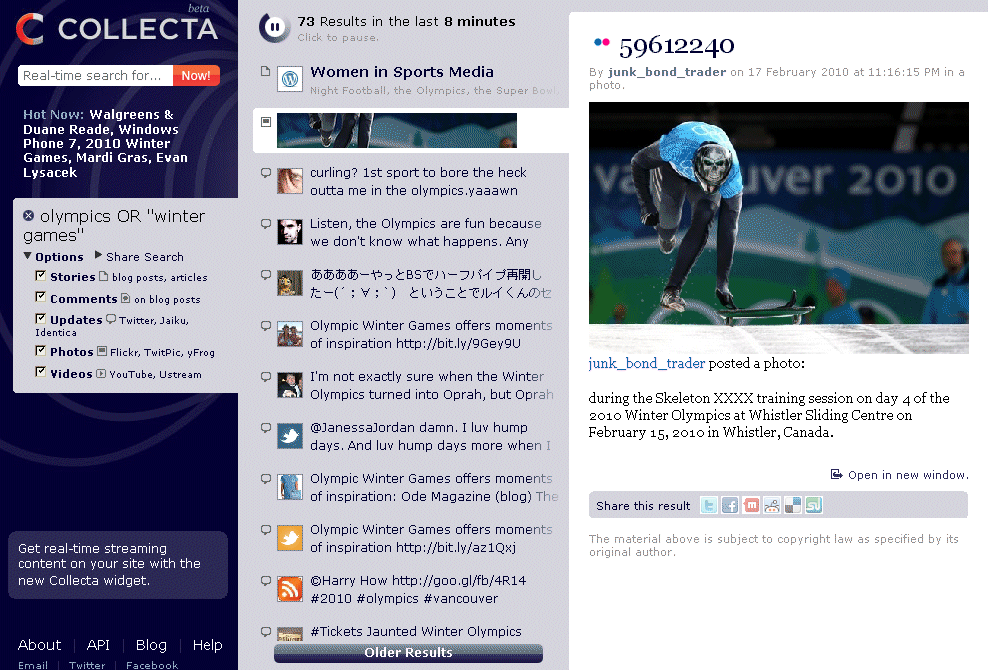 A kezdőlapon az aktuálisan legnépszerűbb témák közül válogathatunk, vagy beírhatjuk a keresőkérdésünket. (A korábbi kérdéseink megmaradnak a keresősor alatt, így később is előhívhatók.) A keresés elindítása után a bal oldali panelen kapcsolhatjuk ki és be, hogy milyen típusú forrásokra vagyunk kíváncsiak, a középső oszlopban pedig elkezdenek sorjázni a találatok. Ha túl gyorsan jönnek, akkor a pause gombbal megállíthatók, majd újraindíthatók és visszagörgetésre is van lehetőség az Older Results gombbal. A jobb szélső hasábban pedig magát az üzenetet, blogbejegyzést, vagy képet láthatjuk, amennyiben rákattintunk valamelyik találatra. Ezt azután egy-két kattintással meg is oszthatjuk másokkal a legnépszerűbb közösségi site-okon (pl. Facebook, Delicious).
A kezdőlapon az aktuálisan legnépszerűbb témák közül válogathatunk, vagy beírhatjuk a keresőkérdésünket. (A korábbi kérdéseink megmaradnak a keresősor alatt, így később is előhívhatók.) A keresés elindítása után a bal oldali panelen kapcsolhatjuk ki és be, hogy milyen típusú forrásokra vagyunk kíváncsiak, a középső oszlopban pedig elkezdenek sorjázni a találatok. Ha túl gyorsan jönnek, akkor a pause gombbal megállíthatók, majd újraindíthatók és visszagörgetésre is van lehetőség az Older Results gombbal. A jobb szélső hasábban pedig magát az üzenetet, blogbejegyzést, vagy képet láthatjuk, amennyiben rákattintunk valamelyik találatra. Ezt azután egy-két kattintással meg is oszthatjuk másokkal a legnépszerűbb közösségi site-okon (pl. Facebook, Delicious).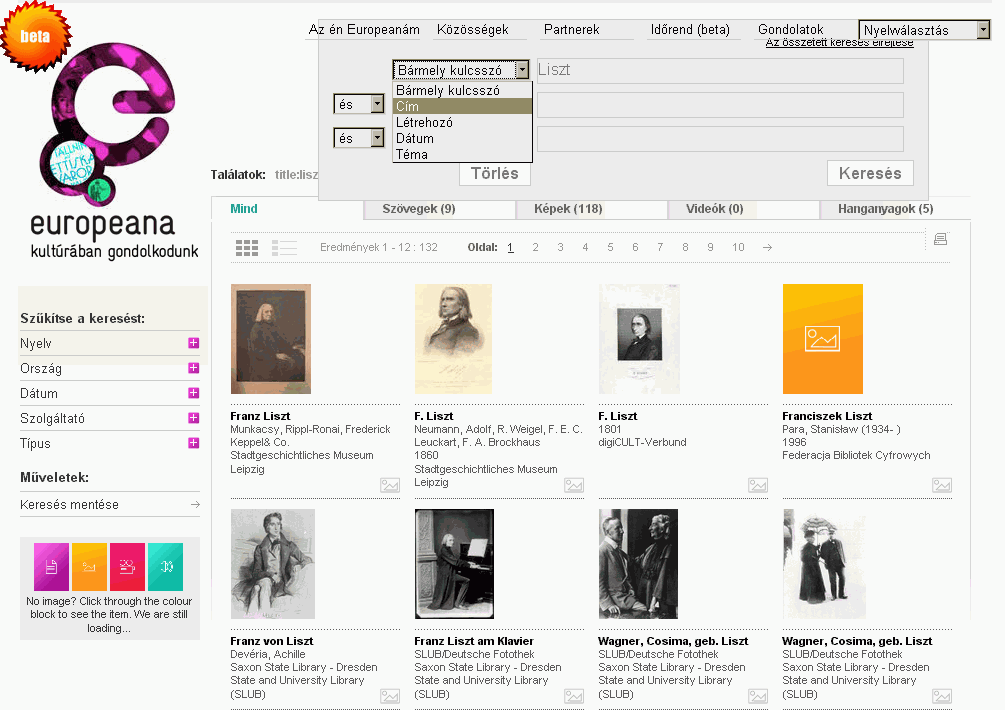 Az "Európai Digitális Könyvtár" néven is emlegetett szolgáltatás 2008. november 20-án nyílt meg, azzal a céllal, hogy egy helyen tegye elérhetővé az európai uniós országok kulturális és tudományos jellegű digitális dokumentumainak minél nagyobb részét.
Az "Európai Digitális Könyvtár" néven is emlegetett szolgáltatás 2008. november 20-án nyílt meg, azzal a céllal, hogy egy helyen tegye elérhetővé az európai uniós országok kulturális és tudományos jellegű digitális dokumentumainak minél nagyobb részét.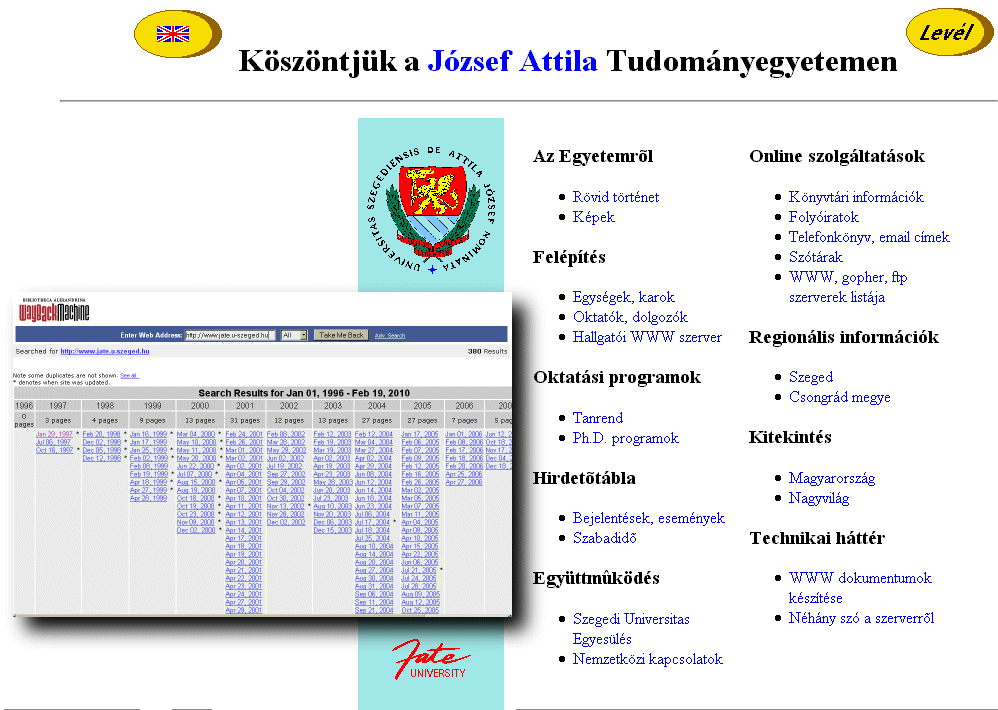 Az 1996-ban San Francisco-ban alapított non-profit szervezet a weblapok tartalmának indexelése vagy a digitális dokumentumok metaadatainak összeszedése helyett a weboldalak és dokumentumok tényleges begyűjtését és archiválását választotta céljának, hogy egy "Internet Library"-t építsen belőlük. A web aratását az
Az 1996-ban San Francisco-ban alapított non-profit szervezet a weblapok tartalmának indexelése vagy a digitális dokumentumok metaadatainak összeszedése helyett a weboldalak és dokumentumok tényleges begyűjtését és archiválását választotta céljának, hogy egy "Internet Library"-t építsen belőlük. A web aratását az 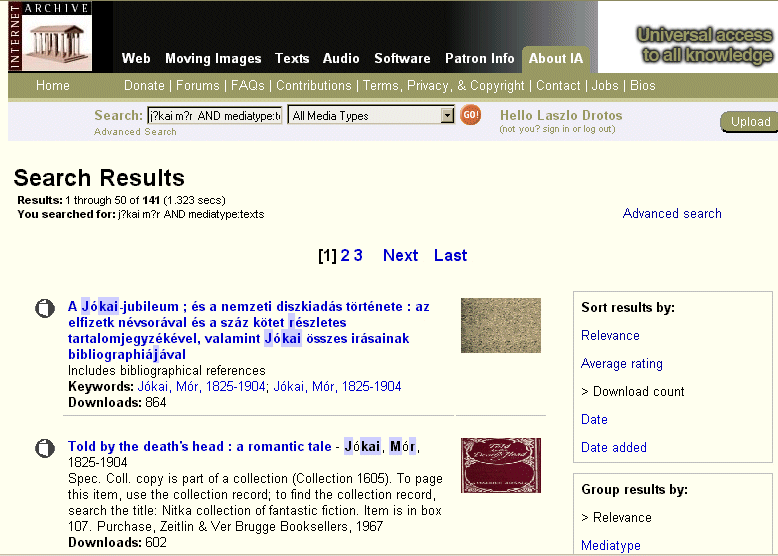 A találati listákat többféle módon szűrhetjük és csoportosíthatjuk, és néhány további opció is megjelenik a képernyő jobb szélén (célszerű például a Turn off thumbnails-re kattintva kikapcsolni a kis animált képek megjelenítését, mert ezek eléggé lelassítják a nagyobb listák böngészését). Ha kiválasztunk egy tételt, akkor megnyithatjuk (Read Online menüpont) vagy letölthetjük azt, a részletes leíró adataitól balra eső sávban felsorolt formátumokban: rendszerint PDF és DjVu, valamint különféle e-book formátumok, illetve egyszerű OCR-es text (ez utóbbit a Google le szokta indexelni, úgyhogy a
A találati listákat többféle módon szűrhetjük és csoportosíthatjuk, és néhány további opció is megjelenik a képernyő jobb szélén (célszerű például a Turn off thumbnails-re kattintva kikapcsolni a kis animált képek megjelenítését, mert ezek eléggé lelassítják a nagyobb listák böngészését). Ha kiválasztunk egy tételt, akkor megnyithatjuk (Read Online menüpont) vagy letölthetjük azt, a részletes leíró adataitól balra eső sávban felsorolt formátumokban: rendszerint PDF és DjVu, valamint különféle e-book formátumok, illetve egyszerű OCR-es text (ez utóbbit a Google le szokta indexelni, úgyhogy a 
 Talán ez még odébb van, de a kereséseink és a jövőbeli események meghatározása közötti összefüggés már a valóság. A
Talán ez még odébb van, de a kereséseink és a jövőbeli események meghatározása közötti összefüggés már a valóság. A