„the ultimate personalized search engine: the librarian” (Sergey Brin)
Amikor információt keresünk az interneten, interakcióba lépünk számítógépünk segítségével egy keresőmotorral. Az interakció kvázi-nyelvi, hiszen szöveges bevitellel keresünk szöveges információt (ez gyakran így van a nem-szöveges információ esetében is, hiszen ilyenkor a rendszer a tagek között keres). A keresést tanulnunk kell és gyakran körülményes, viszont rendelkezünk egy csodálatos képességgel; tudunk kérdezni. De mi is a különbség a kérdések és a keresés között? Hogyan tehetjük természetesebbé a keresés élményét? Erre adhat választ a pragmatika.
Mi is az a pragmatika?
A pragmatika a nyelvészet egy ága, amely a nyelvet használatának folyamatában vizsgálja. Kérdései (pl. mitől működik egy társalgás, mit jelent deklarálni valamit, mit jelent hazudni) sokak számára triviálisnak tűnhetnek, de hát a gravitáció is adott volt mindig, mégis Newton volt, aki meglátta a jelentőségét. Ennél persze sokkal több haszna is van a pragmatikának, a retorika művelőit érdekli, mitől lehet meggyőzőbb érvelésük, pszichológusok és pszichiáterek gyakran a társalgás szabályainak betartását (vagy be nem tartását) figyelik diagnosztikai elbeszélgetéseik során, a jogtudományok művelőit is érdekli egyrészt a meggyőző érvelés alakítása, másrészt minden egyes jogszabály egy speciális státuszú, ún. beszédaktus (nyelvi formában véghezvitt cselekvés).
Az ún. hétköznapi nyelv filozófiája az ötvenes évekig szinte egyeduralkodó logikai megközelítéssel szemben, Wittgenstein nyomdokain haladva a hétköznapi nyelvhasználat felé fordult. J.L. Austin a beszédaktusok természetét körüljáró Tetten ért szavak c. könyvében rámutatott arra, hogy bizonyos nyelvi megnyilatkozások értelmezhetők cselekvésként, ezek a fent már említett beszédaktusok, pl egy deklaráció („mától férj és feleség vagytok”) vagy egy hajó keresztelés („mostantól a neved Fóka”). H. P. Grice a modern pragmatika atyja, ezt gondolta tovább, hiszen minden megnyilatkozás értelmezhető cselekvésként is. Ha csupán társalgunk valakivel, nem csak mondatokat formálunk, valami más is történik, ami nem feltétlenül tartozik a nyelvhez, de mindenképpen hatással van rá. Ezeket vizsgálva Grice ún társalgási maximákat talált.
Társalgási maximák
Röviden tekintsük át ezeket a maximákat:
- Mennyiség
- legyen a kívánt mértékben informatív
- ne legyen túl informatív (ez idővesztés)
- Minőség
- ne mondj olyat, amiről azt hiszed, hogy hamis
- ne mondj olyat, amire nézve nincs megfelelő evidenciád
- Viszony/Kapcsolat (relevancia)
- légy releváns (a relevancia maximája)
- Mód/Modor (Érthetőség)
- kerüld a homályos kifejezést
- kerüld a kétértelműséget
- légy tömör
- légy rendezett
Ezek a maximák nem előírások, nincsenek kőbe vésve, sokkal inkább iránymutatók, melyek elősegítik az eredményes társalgást. Egy társalgás során általában információt cserél két, vagy több ember. Ha tudni szeretnénk valamit, vagy megkérdeznek tőlünk valamit, általában tudatlanul is követjük ezeket a maximákat. Ez természetes számunkra, hiszen minden (egészséges) ember rendelkezik nyelvi képességgel (azaz az anyanyelv elsajátításának és használatának képességével) és szocializációnk során a fenti elvek is belénk ívódnak. Vegyünk fel még egy szempontot a relevancia kapcsán, ha információt szeretnénk szerezni, megpróbáljuk az ésszerű kereteken belül a legmegbízhatóbb forrást elérni és az, hogy milyen forrást sikerült találnunk hatással van arra, hogy mennyire fogadjuk el a kapott választ.
Keresés és relevancia
Keresni kulcsszavakkal szoktunk, nem kérdéseket teszünk fel. Habár így a tömörség és rendezettség módját maximálisan követjük, nem biztos, hogy releváns kérdést teszünk fel. Ha a piros zoknik ára vagy Mátyás király születési helye érdekel minket, kulcsszavak alapján nem lehetünk elég relevánsak. Zokniból (akárcsak csokiból) többféle van, ahogyan pirosból is, Mátyás király pedig nem csak egy volt (habár mindenki az elsőre asszociál a szókapcsolat hallatán). Mi okoz itt gondot? Hiszen sok esetben a keresés simán megadja a releváns találatokat. Ha például új 15 colos monitort szeretnék venni és érdekelnek az árak, a „15'' monitor ár” keresés eredményei kielégítőek. A keresés nem társalgás, de nem is nyelvi tevékenység. Habár a honlapok nyelvi információval vannak tele, ez a kereső motorok számára irreleváns. Őket az érdekli, hogy a keresett kifejezések előfordulnak-e egy adott oldalon vagy nem. A találatokat nem mi rendezzük megbízhatóságuk szerint (erről nincs is elég tudásunk), hanem a kereső algoritmusa (pl aszerint hogy hány más oldal hivatkozik rá). Így tulajdonképpen a kereső bízik abban, hogy a „tömegek” kiválasztják a releváns oldalakat és hivatkoznak azokra.
Ha valamit tényleg tudnod kell; fordulj a könyvtároshoz
Beszélgetéseink hatékonyságához nem árt követni a Grice-i maximákat, de szükségünk van nyelven kívüli tudásra is, azaz hogy kit kérdezzünk. Az hogy kinek a válaszát fogadjuk el több dologtól is függ, például mennyire ismerjük az illetőt, milyen a válaszadó társadalmi helyzete, iskolai végzettsége stb. Ezek a faktorok nem százszázalékosak, vannak rendkívül művelt mozdonyvezetők, akik szeretik a történelmet és vannak többdiplomás kóklerek is, találunk szegény közgazdászokat és dúsgazdag iskolakerülőket, de nagy általánosságban azért útbaigazítanak ezek minket. Brin pont ezért ajánlja a könyvtárost, mint személyre szabott keresőmotort. A könyvtárosok feladata az információ rendszerezése és kereshetővé tétele és egyszerű természetes nyelvi interfésszel érintkezhetünk velük (beszélhetünk velük) és tényleg releváns információhoz jutunk segítségükkel (lektorált folyóiratok, könyvek, enciklopédiák).
Mi ennek a tanulsága?
A keresés legkézenfekvőbb analógiája a kérdezés. De nem szabad elfelejtenünk, hogy a két dolog, hasonlóságaik ellenére különbözik. Az emberek számára a keresőmotor fekete doboz, nem látnak bele és ezért egy naiv elméletet dolgoznak ki, ami magyarázatul szolgálhat nekik annak működéséről (a naiv teóriák nem tudatosak, egyfajta természetes viselkedés hogy minden dologról kialakítunk egy ilyen elméletet, erről többet Donald Norman The Design of Everyday Things című könyvében tudhat meg az érdeklődő olvasó). Mivel nyelvi adatokat (vagy nyelvileg is kódolt adatokat) keres a felhasználó egy nyelvi interfész segítségével, kézenfekvő hogy a kérdések terén felhalmozott tudására alapozza naiv elméletét a kereső működéséről. A hagyományos keresők azonban összeütköznek a megszokott maximákkal mivel 1) túl sok adatot tartalmaz a találati lista 2) nem egyértelmű a találatok értelmezése, hiszen ahogy fent már tárgyaltuk maga a keresés sem felel meg az egyértelműség maximájának. A relevancia fogalma más a két területen, erre nézve szükség lenne a nyelvi adatok (mind a keresés, mind a potenciális találatok terén) mélyebb megértésére, ami még gyerekcipőben jár, s ezért ennek elemzésétől most eltekintünk.
Az említett hiányosságokon azonban segíthetünk, és segítenünk is kell, hiszen egyre több és egyre változatosabb hátterű ember kapcsolódik a világhálóhoz és szabad információ hozzáféréshez való joguk gyakorlását biztosítanunk kell, nem mellesleg ezzel új piaci lehetőségek is megnyílhatnak. Ezek egy része inkább a dizájn és információ tervezés (information architecture) területéről jönnek. Megfelelően tervezett, átlátható, automatikus kiegészítéssel és filterekkel ellátott keresők segíthetnek egyértelműsíteni a keresett kifejezést, azonban ezek tervezése rendkívüli körültekintést igényel. (Az érdeklődő olvasó figyelmébe ajánlom Peter Morville és Jeffery Callender Search Patterns könyvét)
Egy másik lehetséges megoldás a Mozilla Labs Ubiquity projektjében alkalmazott technika, ami megpróbálja a bevitelt értelmezni annak szemantikai szerkezete szerint. A Ubiquity tulajdonképpen egy természetes nyelvi parancssori interfész a Firefox böngészőhöz. A felhasználó segítségével nem csupán a honlapok között tud szörfölni, hanem össze tud kapcsolni különféle internetes szoláltatásokat. Pl. a „translate this to French” és „send it to John” parancsok végrehajtása után a kijelölt oldal francia fordítását beszúrja a rendszer egy John-nak címzett levélbe. Ehhez a Ubiquity egyszerű, természetes nyelvi parancsokat használ melyeket egy elmés ötlettel könnyen lokalizálhatunk is hiszen a szintaktikai elemzője abból indul ki hogy csak bizonyos típusú parancsok kerülnek bevitelre az ember-gép interakció során (utasítások felszólító módban) és bizonyos szerkezetek nem (például a tagadás). Ezek a nyelvi szerkezetek az elvek és paraméterek nyelvészeti kutatási program szerint mély szerkezetükben minden nyelvben azonosak (ezt nevezik elveknek), a felszíni eltérések csupán bizonyos megjósolható különbségekből adódnak (paraméterek). A lokalizáció során nem kell minden egyes parancsot újra írni, csupán be kell állítani a paramétereket, azaz a „email this to John” és a „ezt küld el Janinak” közötti eltéréseket kell leírnunk (szórend, esetjelölés, stb). A parancsok tkp igék, egy igének pedig vannak argumentumai, az hogy milyen argumentumai lehetnek egy igének pedig meghatározza annak szemantikai keretét. Ez a keret lehetővé teszi, hogy az ige begépelése után ajánlásokat tehessen a rendszer a felhasználónak a lehetséges argumentumokra nézve. Ez egyrészt időmegtakarítást jelent, másrészt lehetővé teszi, hogy a felhasználó más lehetséges argumentumokra is gondolhasson, de növeli a pontosságot is. Ha több nyelven állnak rendelkezésünkre ezek a szemantikai keretek, lehetőségünk nyílik arra hogy felhasználjuk az argumentum-előre (ilyen pl a japán nyelv, de magyarul is helyezhetjük előre az argumentumokat pl „ezt Janinak küld el”) típusú nyelveket a rendszer tökéletesítésére. Az argumentumok bevitele során a lehetséges igékre is ajánlásokat tehetünk. (A Ubiquity mögött meghúzódó elvekről bővebben Michael Erlewine “Ubiquity: Designing a Multilingual Natural Language Interface.” és Aza Raskin The Linguistics Command Line cikkeit ajánlom).
Egy, a Ubiquity interfészéhez hasonló rendszerrel a keresést közelíthetjük a természetes nyelvi interakcióhoz. Ma csak szimpla kulcsszavakat írunk be, leggyakrabban főneveket és hozzáértjük, hogy keress. Amikor arra vagyunk kíváncsiak hol született Mátyás király, nem egy kérdést teszünk fel, hanem egy parancsot adunk a keresőnek; „Keresd meg hol született Mátyás király” és a rendszer ezt egyáltalán nem így értelmezi (habár ezzel nincs semmi baj). Azt viszont hogy pontosan mire kíváncsi a felhasználó, valószínűleg pont az eredeti kérdés mondaná meg. A kérdőszavak (és esetleg a kérdéshez kapcsolódó igék) kijelölik a lehetséges argumentumokat, és ahogy fent már láttuk az argumentumok is kijelölhetik az igét, ez pedig egyértelműsíti a kérdést és maga a kérdés átfordítható kulcsszavakká a kereső számára.
Varjú Zoltán a Számítógépes nyelvészet című blog szerzője



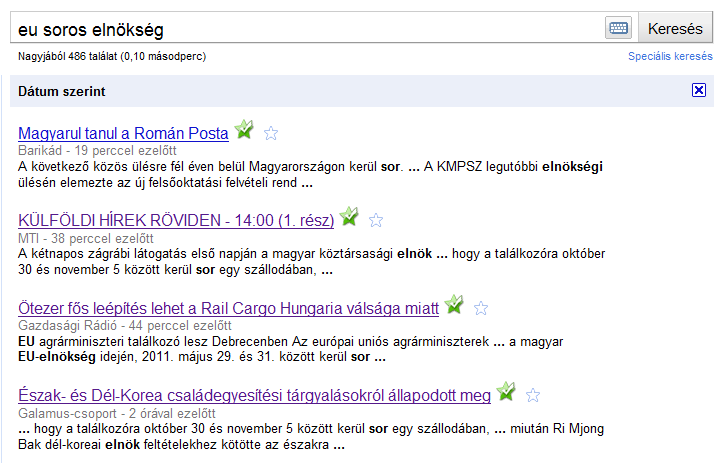
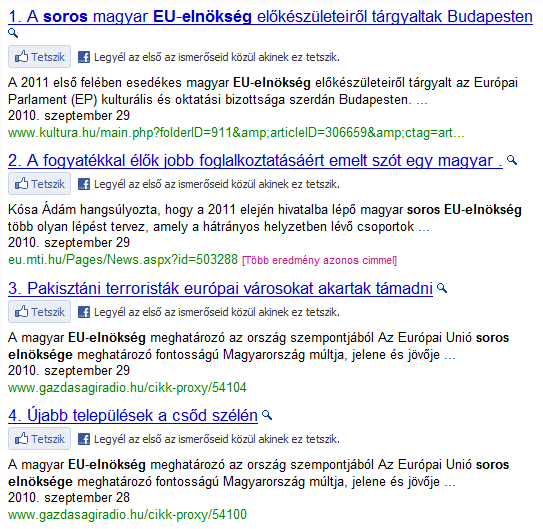
 A webes keresőgépek (
A webes keresőgépek ( A web hatalmas mérete és bonyolultsága miatt minden keresőgép csak egy részét (gyakran csak egy kis töredékét) tudja begyűjteni az elérhető fájloknak, és nagy különbségek vannak az egyes keresők között a kiterjedésben (a web melyik és mekkora részét járja be a crawler?) és frissességben (milyen gyakran és milyen szisztéma szerint látogatja újra az oldalakat a robot?), ami jelentősen befolyásolja a használhatóságukat. A nagy keresők által nem látott terület a
A web hatalmas mérete és bonyolultsága miatt minden keresőgép csak egy részét (gyakran csak egy kis töredékét) tudja begyűjteni az elérhető fájloknak, és nagy különbségek vannak az egyes keresők között a kiterjedésben (a web melyik és mekkora részét járja be a crawler?) és frissességben (milyen gyakran és milyen szisztéma szerint látogatja újra az oldalakat a robot?), ami jelentősen befolyásolja a használhatóságukat. A nagy keresők által nem látott terület a 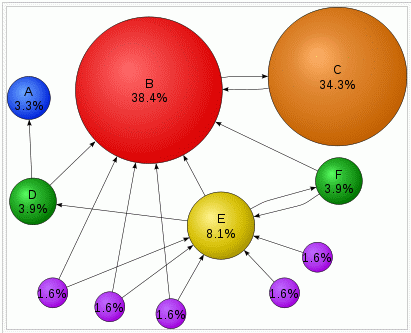 Fontos az is, hogy egy oldalra hány link mutat és mely oldalakról hivatkoznak rá, továbbá hogy ezekre az oldalakra hányan és honnan linkelnek és így tovább... Mivel minden link egy "szavazat" az adott weblap fontossága/népszerűsége mellett, ezért a linkek számából és forrásából számított PageRank érték jól használható a találati listák relevancia szerinti rendezésénél.
Fontos az is, hogy egy oldalra hány link mutat és mely oldalakról hivatkoznak rá, továbbá hogy ezekre az oldalakra hányan és honnan linkelnek és így tovább... Mivel minden link egy "szavazat" az adott weblap fontossága/népszerűsége mellett, ezért a linkek számából és forrásából számított PageRank érték jól használható a találati listák relevancia szerinti rendezésénél.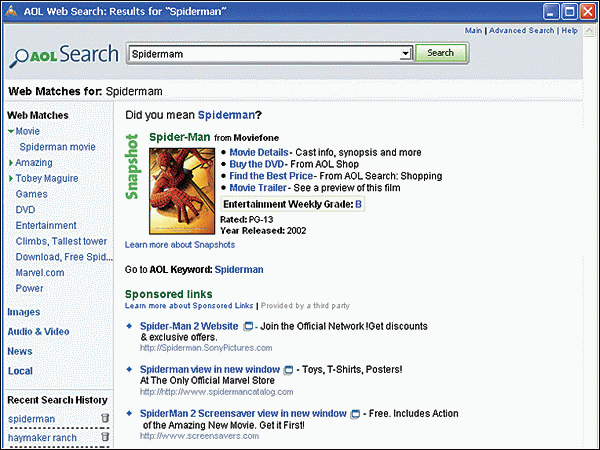 A PageRank mellett számít az is, hogy mennyire ritka egy keresett szó, hányszor fordul elő egy oldalon, milyen hosszú szövegben szerepel és milyen helyen (pl. címben, linkben, egyéb kiemelt pozícióban). Fontos emellett a keresőnyelv fejlettsége ill. az összetett keresőűrlap opciói: csonkolás/maszkolás/ékezetkezelés/pontatlanul írt (fuzzy) szavak javítása/automatikus kiegészítés, logikai műveletek, közelségi/helyzeti operátorok, prefixek (pl. title:, site:, link:) szűrők (pl. domain, formátum, nyelv, dátum, jogok), természetes nyelvű keresés, gépelési hibák javítása, szinonimák és ragozott alakok, hasonló oldalak keresése.
A PageRank mellett számít az is, hogy mennyire ritka egy keresett szó, hányszor fordul elő egy oldalon, milyen hosszú szövegben szerepel és milyen helyen (pl. címben, linkben, egyéb kiemelt pozícióban). Fontos emellett a keresőnyelv fejlettsége ill. az összetett keresőűrlap opciói: csonkolás/maszkolás/ékezetkezelés/pontatlanul írt (fuzzy) szavak javítása/automatikus kiegészítés, logikai műveletek, közelségi/helyzeti operátorok, prefixek (pl. title:, site:, link:) szűrők (pl. domain, formátum, nyelv, dátum, jogok), természetes nyelvű keresés, gépelési hibák javítása, szinonimák és ragozott alakok, hasonló oldalak keresése.") Már egy ideje lemondtam róla, hogy a Kereső Világ hírblogként üzemeljen, hiszen a hírek megírását nem bírtam idővel. A mai, origo által megírt hír - miszerint a
Már egy ideje lemondtam róla, hogy a Kereső Világ hírblogként üzemeljen, hiszen a hírek megírását nem bírtam idővel. A mai, origo által megírt hír - miszerint a 
.gif)
 Teljes szövegű keresés
Teljes szövegű keresés Lycos
Lycos Megindul a verseny
Megindul a verseny
 Bing és Yahoo
Bing és Yahoo Magyar keresők
Magyar keresők