A webes keresőgépek (search engines) három munkafázisból állnak össze: 1. begyűjtés, 2. indexelés, 3. keresés. Ezek a folyamatok nagy teljesítményű elosztott számítógépes rendszereken futnak, folyamatosan és párhuzamosan. A Google például becslések szerint már több mint 1 millió szervert üzemeltet és azt is kiszámolták, hogy egy keresés megválaszolása kb. 1 kJ energiát igényel, ami nagyjából annyi, amennyit az emberi szervezet 10 másodperc alatt éget el.
A webes keresőgépek (search engines) három munkafázisból állnak össze: 1. begyűjtés, 2. indexelés, 3. keresés. Ezek a folyamatok nagy teljesítményű elosztott számítógépes rendszereken futnak, folyamatosan és párhuzamosan. A Google például becslések szerint már több mint 1 millió szervert üzemeltet és azt is kiszámolták, hogy egy keresés megválaszolása kb. 1 kJ energiát igényel, ami nagyjából annyi, amennyit az emberi szervezet 10 másodperc alatt éget el.
1. Begyűjtés
A dokumentumok begyűjtését crawler (más néven: spider vagy bot, magyarul: robot vagy pók) programok végzik. Ezek egy összeválogatott URL címlistából indulnak el, ezután ezeket az oldalakat bejárva begyűjtik az azokban található további URL címeket (linkeket), majd ezeket is végigjárják és így tovább... Az így összegyűjtött URL címeket a crawler control modul, az ezekről letöltött fájlokat pedig a page repository veszi át. Előbbi irányítja a crawlert, hogy mely címeket látogassa meg a továbbiakban (mert például újak, vagy mert a legutóbbi begyűjtés óta változott a tartalmuk), utóbbi pedig az indexelő és esetleg a kereső modul számára szolgáltatja az eltárolt dokumentumokat.
A crawler engedelmeskedik a Robots Exclusion szabályzatnak, vagyis a robots.txt fájlban megadott engedélyek vagy tiltások alapján dönti el, hogy egy adott szerveren mely weblapokat gyűjt be, illetve melyekről követi tovább a linkeket. A webmesterek mellett a keresőgép üzemeltetője is szabályozhatja a crawler működését: beállíthatja például, hogy egy site-on belül milyen mélységig (link-szintig) menjen le a robot, milyen formátumú dokumentumokat gyűjtsön be és milyen mérethatárig, milyen gyakran térjen vissza egy oldalra (ez lehet egy fix időhatár: pl. havonta; vagy kikalkulálható a korábbi látogatások során észlelt változások mennyiségéből: a gyakran és jelentősen változó oldalakra érdemes sűrűbben visszalátogatni).
 A web hatalmas mérete és bonyolultsága miatt minden keresőgép csak egy részét (gyakran csak egy kis töredékét) tudja begyűjteni az elérhető fájloknak, és nagy különbségek vannak az egyes keresők között a kiterjedésben (a web melyik és mekkora részét járja be a crawler?) és frissességben (milyen gyakran és milyen szisztéma szerint látogatja újra az oldalakat a robot?), ami jelentősen befolyásolja a használhatóságukat. A nagy keresők által nem látott terület a deep web (vagyis a "mélyweb" vagy "rejtett/láthatatlan web"), amelynek mérete egyes becslések szerint több százszorosa a surface (vagyis a népszerű keresőgépekkel "látható") webnek. A deep web tartalmához a crawler több okból nem fér hozzá: vagy tiltja a robots.txt, vagy az oldalak dinamikusan generálódnak egy adatbázisból a felhasználó kérésére (pl. egy könyvtári OPAC esetében), vagy csak regisztrált felhasználók tudnak belépni az adott területre, vagy olyan speciális formátumban van (pl. Flash vagy videó) a tartalom, amit a robot nem tud értelmezni, vagy egyszerűen elszigetelt a site (nem mutat rá külső link).
A web hatalmas mérete és bonyolultsága miatt minden keresőgép csak egy részét (gyakran csak egy kis töredékét) tudja begyűjteni az elérhető fájloknak, és nagy különbségek vannak az egyes keresők között a kiterjedésben (a web melyik és mekkora részét járja be a crawler?) és frissességben (milyen gyakran és milyen szisztéma szerint látogatja újra az oldalakat a robot?), ami jelentősen befolyásolja a használhatóságukat. A nagy keresők által nem látott terület a deep web (vagyis a "mélyweb" vagy "rejtett/láthatatlan web"), amelynek mérete egyes becslések szerint több százszorosa a surface (vagyis a népszerű keresőgépekkel "látható") webnek. A deep web tartalmához a crawler több okból nem fér hozzá: vagy tiltja a robots.txt, vagy az oldalak dinamikusan generálódnak egy adatbázisból a felhasználó kérésére (pl. egy könyvtári OPAC esetében), vagy csak regisztrált felhasználók tudnak belépni az adott területre, vagy olyan speciális formátumban van (pl. Flash vagy videó) a tartalom, amit a robot nem tud értelmezni, vagy egyszerűen elszigetelt a site (nem mutat rá külső link).
2. Indexelés
A begyűjtött "nyersanyagból" a keresőgép többféle indexet készít és ezeket adatbázisokban tárolja. A link index (szerkezeti index) például azt rögzíti egy gráf formájában, hogy mely weblapról mely további oldalakra mutatnak linkek. Mivel a hasonló tartalmú/jellegű oldalak gyakran hivatkoznak egymásra, ezt az információt a keresőrendszer felhasználja a találatok listájában, amikor további hasonló weblapokat ajánl a felhasználónak.
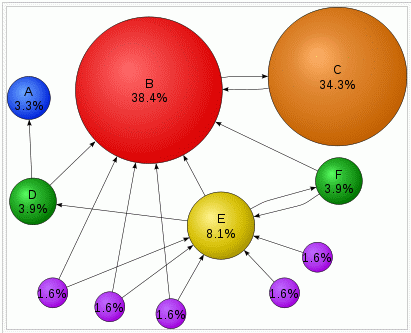 Fontos az is, hogy egy oldalra hány link mutat és mely oldalakról hivatkoznak rá, továbbá hogy ezekre az oldalakra hányan és honnan linkelnek és így tovább... Mivel minden link egy "szavazat" az adott weblap fontossága/népszerűsége mellett, ezért a linkek számából és forrásából számított PageRank érték jól használható a találati listák relevancia szerinti rendezésénél.
Fontos az is, hogy egy oldalra hány link mutat és mely oldalakról hivatkoznak rá, továbbá hogy ezekre az oldalakra hányan és honnan linkelnek és így tovább... Mivel minden link egy "szavazat" az adott weblap fontossága/népszerűsége mellett, ezért a linkek számából és forrásából számított PageRank érték jól használható a találati listák relevancia szerinti rendezésénél.
A text index (szöveg index) pedig a begyűjtött oldalakon található szavakból és egyéb karaktercsoportokból (pl. számok, speciális jelek, tag-ek) készül, de esetleg kihagynak belőle bizonyos szavakat (stopwords), pl. a névelőket. Ez egy ún. invertált index, amelyben minden szóhoz hozzákapcsolják minden olyan oldal azonosítóját (doc_id), ahol az adott szó előfordul, továbbá egy mutatót, amely a szó pontos helyét jelöli az oldalon belül és esetleg egyéb információkat is (pl. hogy a szó milyen tag-ek között található, vagy valamilyen link ill. kép közelében fordul-e elő?).
Az indexek felépítése a legnehezebb műszaki feladat, maga a keresés már egyszerűbb és kevesebb erőforrást igényel. Az indexelés sebessége azért is fontos, mert ettől függ, hogy milyen gyorsan válik megtalálhatóvá a begyűjtött friss tartalom. Ezért a real-time search az utóbbi években - a közösségi oldalak, a blogok és mikroblogok (pl. Twitter) elterjedése miatt - egyre fontosabb, új kutatási területté vált.
3. Keresés
A felhasználó által beírt keresőszavakat a keresőprogram a text index adatbázisából gyűjti ki, rangsorolja őket valamilyen (meglehetősen komplex) algoritmus szerint, majd kikeresi az előfordulási helyükhöz tartozó metaadatokat (a dokumentum címe, URL-je, formátuma, mérete, a begyűjtés dátuma, stb.), továbbá többnyire összeállít egy szövegkörnyezetet (a keresett szavakat előfordulási helyéről), majd megjeleníti őket valamilyen formában (jellemzően egy lapozható listaként). Az, hogy egy keresőgép milyen algoritmus szerint rendez, nagyban meghatározza a hasznosságát és népszerűségét (ezért általában üzleti titokként kezelik, egyben a spamdexing ellen is védekezve).
 A PageRank mellett számít az is, hogy mennyire ritka egy keresett szó, hányszor fordul elő egy oldalon, milyen hosszú szövegben szerepel és milyen helyen (pl. címben, linkben, egyéb kiemelt pozícióban). Fontos emellett a keresőnyelv fejlettsége ill. az összetett keresőűrlap opciói: csonkolás/maszkolás/ékezetkezelés/pontatlanul írt (fuzzy) szavak javítása/automatikus kiegészítés, logikai műveletek, közelségi/helyzeti operátorok, prefixek (pl. title:, site:, link:) szűrők (pl. domain, formátum, nyelv, dátum, jogok), természetes nyelvű keresés, gépelési hibák javítása, szinonimák és ragozott alakok, hasonló oldalak keresése.
A PageRank mellett számít az is, hogy mennyire ritka egy keresett szó, hányszor fordul elő egy oldalon, milyen hosszú szövegben szerepel és milyen helyen (pl. címben, linkben, egyéb kiemelt pozícióban). Fontos emellett a keresőnyelv fejlettsége ill. az összetett keresőűrlap opciói: csonkolás/maszkolás/ékezetkezelés/pontatlanul írt (fuzzy) szavak javítása/automatikus kiegészítés, logikai műveletek, közelségi/helyzeti operátorok, prefixek (pl. title:, site:, link:) szűrők (pl. domain, formátum, nyelv, dátum, jogok), természetes nyelvű keresés, gépelési hibák javítása, szinonimák és ragozott alakok, hasonló oldalak keresése.
Továbbá a találatok megjelenítésének sebessége és módja is lényeges szempont: egyszerű listás vagy kéthasábos, szövegkörnyezet, címkefelhő, gyorsnézet, klaszterezés, grafikus, statisztikai adatok, relevancia érték, stb.; valamint a kiegészítő szolgáltatások: pl. formátumkonvertálás, automatikus fordítás, cache (tárolt változat); és persze az is, hogy mennyi és milyen reklámot tesz a kereső a találatok mellé vagy közé (az első néhány tétel ma már rendszerint "szponzorált" link).
Összeállította: Drótos László Magyar Elektronikus Könyvtár