A Named entity recognition (NER) vagy Named entity extraction, amelyet magyarul névelem-felismerésként szoktunk emlegetni, egy viszonylag alapvető feldolgozó lépés az automatikus tartalomelemző feladatoknál. Ennek ellenére sokaknak talán nem egyértelmű, hogy pontosan miért is bír ilyen nagy jelentőséggel az ún. névelemek automatikus kinyerése. A jelen posztot e megfontolásból a névelem-felismerésnek szentelem, és igyekszem megmutatni e részfeladat célját és hasznát.
Röviden a tartalomelemzésről
A tartalomelemzés vagy információkinyerés (Information extraction, IE) által bizonyos szemantikai információkat akarunk automatikus megoldásokkal kinyerni a szövegekből. Ennek során a szövegekben foglalt strukturálatlan információból strukturált adatot hozunk létre. Miután az adat formalizálttá válik, képesek leszünk számos elemző eszközzel kezelni azokat.
De hogyan kapcsolódnak ehhez a névelemek?
A legtöbb információkinyerési feladatban értelemszerűen nagyon fontos, hogy a számunkra releváns tartalom mely névelemhez kapcsolódik. Így például, a szentiment- vagy az emócióelemzésben nagy jelentőséggel bír, hogy az adott értékítéletet (pl. jó, íztelen, förtelmes) vagy érzelmet (pl. csak bosszúságot okoz, ennyire még nem örültem semminek, attól félek, hogy...) a szöveg szerzője mely entitás vonatkozásában fogalmazza meg, tehát például mely termék vagy közszereplő vonatkozásában fejezi ki, vagy éppen melyik helyhez, időponthoz vagy politikai eseményhez kapcsolható. A különböző szövegek tartalmi elemzésének tehát egyik fontos első lépése a névelemek detektálása és osztályozása, a névelemek az információkinyerés mintegy alapegységeinek is tekinthetőek.
Az információkinyerés ma már jelentős szerepet játszik olyan egyéb, hasznos nyelvtechnológiai alkalmazásokban is, mint például a kérdés-válasz-rendszerekben vagy chatbotokban, amelyek a felhasználó igényei szerint törekednek a leghatékonyabb automatikus feladatvégzésre (pl. jegyfoglalásra) vagy legrelevánsabb információk megadására (pl. utazási időpontokkal kapcsolatban).

És nem csak az információkinyerésben fontosak...
...hanem például a gépi fordításban is. Ahhoz ugyanis, hogy az alábbi típusú fordítási hibákat elkerülhessük, tudnunk kell, hogy névelemekkel van dolgunk:
Nagy Péter - Great Peter, Salt Lake City - Sóstó város, Joy (magazin) - öröm
A fenti megoldások nyilvánvalóan nem szerencsések az automatikus fordításban.
Na de mik is azok a névelemek?
Fontos, hogy a nyelvtechnológiában névelemekként emlegetett kifejezések csoportja egy az egyben nem azonosítható a nyelvészetben tulajdonnevekként emlegetett kifejezések csoportjával. Ennek az az alapvető oka, hogy a nyelvtechnológiai alkalmazások oldalán a névelemek keresésekor legtöbbször nem csupán a klasszikus tulajdonnevek érdekelnek mindket, hanem több és más egyedített jelölőt is meg kell találnunk. Így például, nem csak egy személynév vagy egy szervezet elnevezése lehet releváns, de esetenként fontos információként kell kezelnünk egy telefonszámot, egy e-mail-címet, kémiai tárgyú szövegekben a különböző képleteket vagy orvosi szövegekben a betegségek elnevezéseit is.
Ugyanakkor azt is fontos megemlítenünk, hogy az alkalmazásaink szempontjából a nyelvészeti definíciók megbízható alapot sem adnak a munkához. A Magyar Helyesírási kézikönyv szerint például tulajdonnévnek tekintendő a Magyar Nemzeti Bank, köznévnek pedig például az asztal, az alma vagy a bank. Általánosságban azt mondhatjuk, hogy a meghatározások a tulajdonnevek nagy kezdőbetűs írásmódjával operálnak.

 Ebből kiindulva azonban nem tudni, hogy például a Botond étterem esetében a teljes kifejezés a tulajdonnév, vagy annak csupán az első eleme az. Az étterem ugyanis éppolyan köznévnek tűnik az írásmódját tekintve, mint amelyet a fentebbi köznévi példákban láttunk, ugyanakkor egyértelmű, hogy e nélkül az elem nélkül a Botond, önmagában, nem képes ugyanazt az entitást jelölni.
Ebből kiindulva azonban nem tudni, hogy például a Botond étterem esetében a teljes kifejezés a tulajdonnév, vagy annak csupán az első eleme az. Az étterem ugyanis éppolyan köznévnek tűnik az írásmódját tekintve, mint amelyet a fentebbi köznévi példákban láttunk, ugyanakkor egyértelmű, hogy e nélkül az elem nélkül a Botond, önmagában, nem képes ugyanazt az entitást jelölni.
Nem kevésbé elgondolkodtatóak azok a kifejezések sem, amelyeket a különböző nyelvekben eltérő kezdőbetűvel írunk. Angol szövegekben például a Bluetooth névelemet rendre nagy kezdőbetűvel írják, míg a magyar nyelvben mind a kicsi, mind a nagy kezdőbetűs írásmód gyakori (Bluetooth és bluetooth). Az oroszban még kacifántosabb a helyzet. Mondhatni, ott aztán minden van: Bluetooth, bluetooth, Блютуз, блютуз, Блютус, блютус. Az pedig mégiscsak furcsa, hogy ugyanazt az entitást megnevező jelölő az egyik nép számára tulajdonnév, a másik számára pedig köznév, az írásmód alapján...
Nem véletlen, hogy a nyelvtechnológiai alkalmazások ezekbe az elméleti fejtegetésekbe nem is szoktak túlságosan belebonyolódni, inkább keresnek egy olyan megoldást, amely az adott célra a legmegfelelőbb. A jelen probléma esetében tehát nem az a kérdés, hogy mi a tulajdonnév és meddig terjed a szövegben a tulajdonnév határa, hanem az, hogy melyik az az egy vagy több tagból álló nyelvi elem a szövegben, amely a konkrét alkalmazás szempontjából releváns egyedet jelöl, arra unikusan, azaz egyedi módon referál.
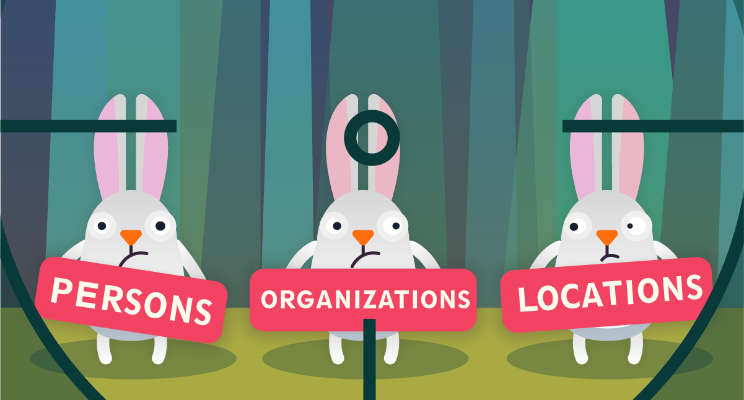
Az elmondottakkal összefüggésben a NER-feladatban, bár legtöbbször a már klasszikusnak is nevezhető névelem-kategóriába sorolható kifejezéseket keressük (személy-, hely- és szervezetnév), az aktuális projekt céljainak megfelelően gyakorta olyan névelem-típusokat is keresünk, amelyek bizonyosan nem férnének bele a klasszikus tulajdonnév-fogalomba. Ilyenek például a temporális (pl. dátum, nap neve stb.) és a numerikus (pl. vminek a mennyisége) kifejezések.
A névelem-detektálás és osztályozás nehézségei
A névelemek automatikus megtalálása még a feladat egy viszonylag egyszerűbb részének tekinthető. Egyértelműsíteni azonban már jóval nehezebb őket. De mit is jelent a névelemek egyértelműsítése? A névelemek feldolgozásánál két típusú egyértelműsítést kell elvégeznünk:
Egyrészt, az adott névelem referálhat egyazon kategória különböző elemeire. Például a Kennedy jelölő mind az apa, mind a fia esetében személynév típusú elem, azonban tartalomelemzési szempontból ez az információ számunkra valószínűleg nem lesz elegendő. Ahhoz, hogy a szöveg információtartalmát a megfelelő entitáshoz tudjuk kapcsolni, azt is tudnunk kell, hogy az aktuális helyzetben mire vonatkozik a megtalált jelölő. Ez pedig korántsem triviális feladat.
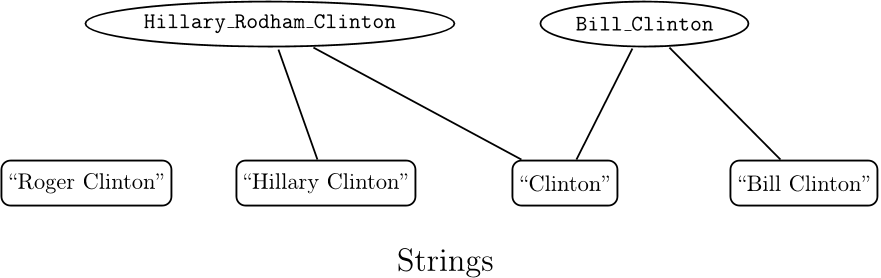
Másrészt, egy adott névelem referálhat két vagy több különböző kategória elemére is. A Washington kifejezés például személy-, hely- és szervezetnév egyaránt lehet. Ez utóbbi akkor, ha a sportcsapatra referálunk.
A szövegkörnyezetből - ideális esetben - az ember számára könnyen kiderül, hogy a fentebbiekhez hasonló esetekben éppen melyik jelölt az aktuális. A gép számára azonban ez egy igen nehéz feladat. Mondhatni, szintaktikai információkból kell szemantikai és pragmatikai szintű döntéseket meghoznia.

Az egyértelműsítéshez hasonló részfeladat az is, hogy a szövegfeldolgozás során megtalált különböző alakú, ám azonos jelölettel rendelkező jelölőket össze kell tudnunk kapcsolni. Egy hírszövegben például könnyen előfordulhat, hogy a szerzője ugyanarra az entitásra először a Példa Péter vagy a P. Péter, majd a 37 éves férfi vagy éppen a gyilkos megnevezésekkel utal.
Milyen módszereket alkalmazunk a NER-feladatokban?
A két alapvető NER-módszer a szótáras megoldás és a gépi tanítás. Lássuk ezeket a módszereket kicsit részletesebben is!
Röviden a szótárakról
A szótáras módszer esetében az ún. egyértelmű szavakat szótárak formájába rendezik a készítők, majd ezek alapján, ún. szótárillesztéses megoldással dolgoznak. A szólisták elkészíthetőek például egy tanuló adatbázis segítségével is, amelyből kigyűjtjük a megfelelő elemeket (pl. a betegségek neveit). Vannak családi név és keresztnév listák, továbbá vállalatnév- és terméknév-listák is. A helynevek listáját gazetteerek-nek nevezzük.
A szólisták azonban a NER-feladat megoldására csupán korlátozott mértékben képesek, és alkalmazásuk egyébként is problémás lehet. Egyrészt, ezeket a listákat nehéz és költséges elkészíteni. Emellett a hatékonyságuk is névelem-osztályonként változik. A gazetteerek például jól működnek, míg a szervezet- és személynevek nem annyira. Ráadásul, mivel a névelemek a nyelvben nyílt halmazt képeznek, nem fedhetőek le teljes mértékben szótárakkal, és a listák folyamatos frissítést igényelnek. A szótáras megoldás előnye viszont, hogy - a gépi tanuló megoldással ellentéteben - nem igényel nagy méretű adatbázist.
A szótáralapú elemző rendszerek gyakran ún. prediktív szavak listáit is alkalmazzák. Ezek olyan nyelvi elemek, amelyek a kontextusban elő tudják jelezni a névelemek egy bizonyos csoportját. Például, a titulusok jó prediktív elemei a tulajdonnévi entitásoknak. Ellentétben az előzőleg tárgyalt listákkal, ezek a szótárak relatíve rövidek és időben jelentősen stabilabbak, tehát könnyebben elkészíthetőek és karban is tarthatóak.
A nyelvtechnológia trigger-szótáraknak nevezi azokat a listákat, amelyek nem egyedi entitások elnevezéseit tartalmazzák, hanem egyéb olyan elemeket vagy névelem-részeket, amelyeket alkalmazni lehet az elemzésben.
Röviden a gépi tanulásról
Mivel minden NER-feladat az aktuális projekttől függően más és más, a szótárak, és az azokra építő szabályalapú rendszerek előállítása igen költséges vállalkozás. Megoldást jelenthet, ha gépi tanító adatbázisokat építünk, és ezek alapján megtanítjuk az algoritmusnak felismerni és kezelni a névelemeket a nyers szövegekben.
A feladat standard megközelítése az angolul word-by-word sequence labeling task-nak nevezett módszer, amelyet magyarra szavankénti szekvenciajelölés-ként fordíthatnánk. Ez tulajdonképpen egy statisztikai alapú megoldás, hasonló ahhoz, mint amelyet a szófaji egyértelműsítésben (POS-tagging) vagy a szintaktikai alapú fráziselemzésben (chunkolás) alkalmazunk. Az osztályozót arra tréneljük, hogy megtalálja és bejelölje a szövegben a megfelelő tokeneket. A rendszer az ún. IOB-jelölési megoldáson alapul, amelyben a kódok a következő információkat rejtik: I=inside a chunk, O=outside any chunk, B=beginning of a chunk.
Amikor névelemek automatikus felismertetése céljából tanító adatbázist hozunk létre, a fentebbi megoldás szerint a korpusz minden eleme az IOB-jelölések valamelyikét, valamint a megfelelő névelem-kategória jelét kaphatja meg: I / O / B + ORG, LOC, PER, vagy bármely, az adott nyelvechnológiai célnak megfelelő kategória tagét:

No de mielőtt elkészül az adatbázisunk a megfelelő tagekkel, tudnunk kell, hogy melyek azok a sajátságok, amely jó prediktorok lehetnek a későbbi tréneléshez. Ez alapján el kell készíteni a tanító adatbázist.
Miket kódolhatunk a tréning adatbázisban?
Egyrészt az adott névelemre vonatkozó ortográfiai jellemzőket: kezdőbetű típusa, szóhossz, tartalmaz-e számot vagy speciális írásjelet, a szám, amelyet esetlegesen tartalmaz, arab vagy római szám-e. Bár ezek a sajátságok pl. a POS-taggelésnél és a szintaktikai elemzésnél is előjönnek, egyesek különösen fontosan a NER-ben. Ilyen pl. a központozás, valamint a kis- és nagybetűk szokatlan variációja (pl. Yahoo!, eBay). Vannak olyan osztályok, amelyek egyszerű szabályokkal (általában reguláris kifejezésekkel) leírhatóak, például az e-mail címek.
Másrészt szövegkörnyezeti információkat: uni- / bi- / trigramok, mondatpozíciós és dokumentum-pozíciós sajátságok, milyenek a megelőző tokenek címkéi stb. Olyan sajátosságokat kell találni, amely az egyes input példákra jellemző és jó prediktorként működhet. A kontextusra vonatkozóan igen hasznosak lehetnek a POS, a bag-of-words vagy N-gram információk. Ilyenkor a környezetre vonatkozó információkat is felvesszük az adott token jellemzői közé.
Ha ezeknek a sajátságoknak kialakítjuk egy adekvát listáját, utána bekerülhetnek a tréning korpuszba a szekvencia-osztályozón alapuló gépi tanításhoz megfelelő formában. Minden elem tehát a tréning adatbázisban az a kategória tagén és az IOB-n kívül ezekkel az információkkal is rendelkezhet.
Az elkészült tréning korpuszon azután mehet a gépi tanulás, ami által egy a nyers szövegek elemzésére alkalmaz nyelvfeldolgozó eszközt kapunk.
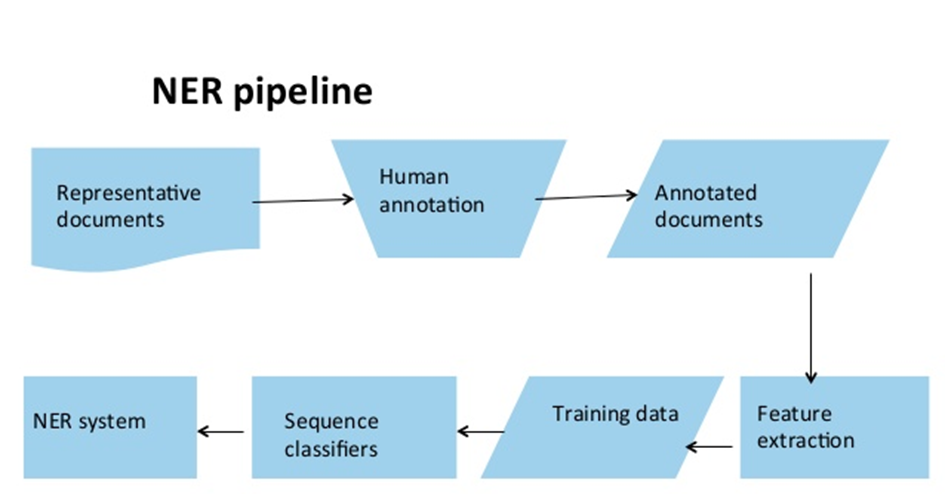
A fentebb tárgyalt megoldások (egyenként vagy kombinálva) eredményessége természetesen függ az adott applikációtól, a szövegműfajtól, a nyelvtől és a szövegkódolástól is. Így például az íráskép nem sokat segít hangzóból leiratozott vagy twitter-szövegnél.
Irodalom
- Jurafsky, Dan, Martin, James H. 2009. Speech and language processing. A Simon & Schuster Company,
Englewood Cliffs, New Jersey. 759-768. - Simon Eszter 2013. A magyar nyelvű tulajdonnév-felismerés módszerei. Tézisfüzet. Budapest
- Vincze Veronika, Farkas Richárd 2012: Tulajdonnevek a számítógépes nyelvészetben. Általános Nyelvészeti Tanulmányok XXIV. 97-119.