A közösségi médiában szeretünk ismerős és ismeretlen emberekkel csevegni, magvas és kevésbé magvas gondolatokat megosztani, vagy csak időtöltésből írogatni. De mit árulunk el magunkról eközben? Mivel a Twitter lehetővé teszi, hogy letöltsük saját adatainkat s így a szerző saját fiókját (@zoltanvarju a továbbiakban mint "alany" hivatkozunk rá) elemezve keresi erre a választ. Először megnézzük, milyen eredményekre vezet minket a legelemibb elemzés, majd kitérünk arra, hogy ez mennyire fedi a valóságot.
Saját csiripek beszerzése
A Twitter a személyes beállítások alatt teszi elérhetővé a csiripek archívumát. A "Request your archive" gombra kattintva kérhetjük ezek letöltését.
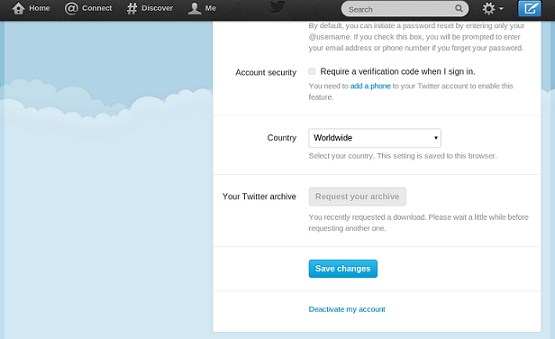
Miután rákattintottunk a gombra, a Twitter nyugtázza nekünk ezt. Változó, hogy kinek mennyi időt kell várnia (az azonnali letöltéstől a két órás várakozásig tartó intervallummal számoljunk).
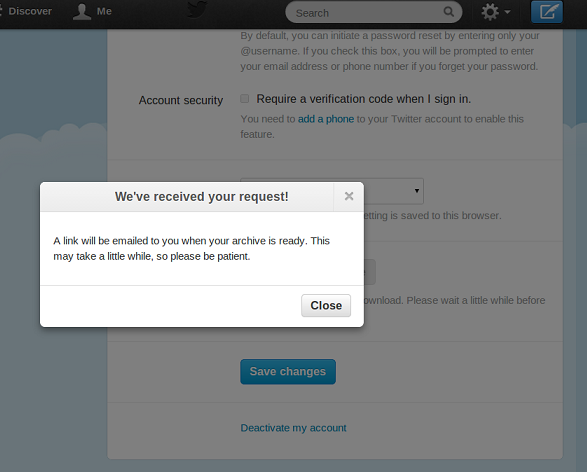
Az archívum elkészültéről e-mailben értesít minket a szolgáltató.
A letöltött archívum egy tömörített mappa, ami alapvetően egy html oldalt is tartalmaz, ezen böngészhetjük csiripjeinket. A "data" mappában találjuk a tweeteket tartalmazó JSON fájlokat év_hónap.js séma szerinti nevek alatt. Vizsgálatunkhoz az alany 2009 január és 2013 június között írt tweetjeit elemeztük az archívumból.
Lexikai elemzés
Automatikus nyelvfelismerés használatával azt találtuk, hogy az alany két nyelven, angolul és magyarul csiripel. Az angol nyelvű posztok aránya 77%, miután kiszűrtük a linkeket tartalmazó tartalmakat (azzal a feltételezéssel élve, hogy ezek nem saját tartalmak, hanem hírmegosztások) azt találtuk, hogy a tartalom kétharmada angol, a maradék pedig magyar nyelvű. Egy átlagos tweet 13.98 szóból áll, ami 15.88 az angol és 11.3 a magyar csiripek esetében.
A lexikai diverzitás egy olyan mérőszám, amivel egy adott szöveg választékossága jellemezhető. Ezt úgy kapjuk meg, hogy a szöveg összes szavának számát (token) elosztjuk az egyedi szavak számával (type). Pl. a híres "lenni vagy nem lenni" idézetben négy token található és három típus, így lexikai diverzitása 1.33. Azt találtuk, hogy mindkét nyelv esetében 107 feletti értéket mutatnak a vizsgált alany nyelvi megnyilatkozásai, amire a linket tartalmazó megosztások sincsenek hatással. Ez egy minimum középiskolai végzettséggel rendelkező felnőtt lexikai diverzitásának felel meg, ami alapján eddig arra jutottunk, hogy alanyunk átlagos nyelvhasználó.
Ezután egyszerű szógyakorisági vizsgálatot végeztünk. Ehhez a szöveget megtisztítottuk a linkektől és minden nem-betű karaktertől, majd minden karaktert kisbetűre alakítottunk, végül pedig mind az angol, mind a magyar stopszavakat kiszűrtük. Az alábbi ábrán a huszonöt leggyakrabban használt szó látható.
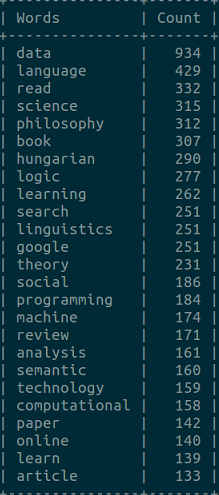
Érdekes, hogy habár a korpusz 23%-a magyar nyelvű, egy magyar szó sem került fel a listára.
Minimalista networkelemzés
Aki újra oszt egy adott tartalmat, arra valószínűleg valahogy hatott az. Nézzük meg alanyunk, mely felhasználók csiripeléseit szokta re-tweetelni.
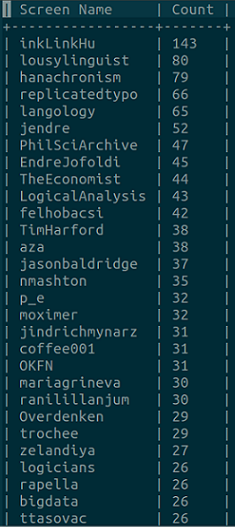
A fenti táblázathoz nagyon hasonlót kapnánk a @TheEconomist és @PhilSciArchive nélkül, ha azt vizsgálnánk kikkel beszélget a legtöbbet a felhasználó.
Pszichológiai profilozás
Találomra kiválasztottunk hat angol tweetet és az LIWC program online elérhető változatával elemeztük, ennek eredményét mutatja az alábbi ábra.
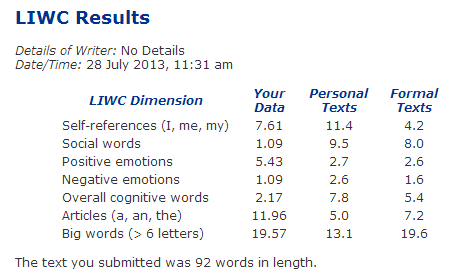
Az eredmények értelmezéséhez Pennebaker elméletéhez fordultunk (amiről bővebben Nekünk elmélet kell! és A tweet a lélek tükre című posztjainkban tudhat meg a kedves olvasó). Feltesszük, hogy a tweetek többsége személyes hangvételű (bővebben l. Milyen is az internet nyelve című írásunkat) ezért a "Personal Texts" oszloppal vetjük össze a kapott értékeket. Az önreferenciális (Self-references) szavak magas és a kognitív kifejezések (Overall cognitive words) alacsony aránya arra utal, hogy a szerző férfi. A nagy szavak (Big words) használata jelezheti az alábbiakat (egyiket vagy akár mindegyiket); felnőtt, iskolázott, magas státuszú. (Bővebben erről l. Pennebaker The Secret Life of Pronouns c. könyvét) A LIWC teljes változatát használva az összes angol tweet elemzésére is a fentihez nagyon hasonló eredményt kapunk, ami azt mutatja hogy viszonylag kis szövegrészleten is jól működik ez az elemzés.
Mit tudunk az alanyról
Az alany 31 éves férfi, aki logikát és matematikai nyelvészetet tanult, jelenleg a Precognox Kft. számítógépes nyelvésze. Az egyszerű szógyakoriság nagyon jól tükrözi érdeklődési köreit, a pszichológiai profilozás pedig megadja alapvető demográfiai jellemzőit is. Látható, pusztán szöveges tartalmak elemzésével az alanyról jó profilt tudtunk alkotni. Az alapvető networkelemzés is ezt támasztja alá, hiszen főleg logikával, számítógépes nyelvészettel, funkcionális programozással és gépi tanulással foglalkozó felhasználókat követ.
Szavakat számoltunk és arra jutottunk, hogy egész jó jellemzését tudjuk adni egy felhasználónak. Könnyű belátni, hogy további elemzésekkel egy teljes profilt is készíthetünk.