



Előző posztunkban bemutattuk, miképp hatottak az új IT trendek és társadalomtudományi kutatások az újságírásra és alakult ki az adatvezérelt irányzat. Az internet elterjedésével a nyomtatott sajtónak is számolnia kellett, megjelentek a híroldalak és minden valamire való lap saját oldallal jelentkezett a világhálón. Ekkor jelentek meg az ún. MVC (model-view-controller, model-nézet-kontroller) keretrendszerek, amik nagyon népszerűek lettek a hír- és tartalomiparban. A megoldás lényege, hogy elkülönítik az adatok reprezentálását (modell) és megjelenítését (nézet). Így egy modellhez, akár több nézet is tartozhat, amit a két egység között közvetítő kontroller határoz meg. 2005-ben az Egyesült Államok egy kansasi kisvárosában Lawrence-ben a Lawrence Journal megengedte fejlesztőinek, hogy saját MVC keretrendszert fejlesszenek ki , ezzel született meg a Django webprogramozási keretrendszer, amit a Pinterest és a Mozilla mellett olyan nagy híroldalak is használnak, mint a The Washington Times és a Public Broadcasting Service.

A Django fejlesztői között akadt egy nagyon érdekes figura, Adrian Holovaty. Alig egy évvel a keretrendszer megalkotása után ő írta A fundamental way newspaper sites need to change (Ahogy a híroldalaknak alapvetően meg kell változniuk) című esszét, amit a modern adatújságírás manifesztumának tartanak. Az esszé lényegében a hírekre is kiterjeszti az MVC alapelvet. Mivel a narráció célja, hogy a tényadatokat (ki[k], mikor, hol és mit csináltak) kontextusba helyezze, érdemes külön is kigyűjteni az adatokat. Így pl. egy helyi lapnál minden egyes betörésről születhet egy cikk, de egyben bővül is az adatbázisa és az olvasók maguk is megnézhetik hol és mikor történtek betörések. Így lehetőség nyílik arra, hogy alaposabban megvizsgáljuk az adatokat és összevessük más tényezőkkel is azokat (pl. van-e rendőrőrs a betörések közelében, mekkora arrafelé a munkanélküliség, milyen más bűncselekmények történnek az adott környéken stb.) Holovaty alapított is egy startup-ot ötletére, az Everyblock-ot, amit sajnos új tulajdonosa hamarosan be fog zárni. Az esszé hatása azonban tovább él és sokakat inspirál (pl. a blogunkon nemrég bemutatott Circa is az esszé alapötletére épül).

2006-ban alapították lelkes aktivisták a WikiLeaks alapítványt és portált. A híres kiszivárogtatások nagy kihívás elé állították a szerkesztőségeket, hiszen a WikiLeaks első évében több mint 1.2 millió dokumentum került napvilágra különböző ügyekben. Ezek áttekintése és értelmezése szinte lehetetlen feladat lenne a modern technika vívmányai nélkül. A 2010-ben kiszivárogtatott Iraq War Logs (iraki hadi cselekmények jelentései) összefoglalója egy 92,201 soros táblázat, ami tartalmazza a harci cselekmény helyét, idejét és rövid leírását. Ennek egy része hagyományos módszerekkel is elemezhető, de a leírások áttekintéséhez be kellett vetni a nyelvtechnológiát is.
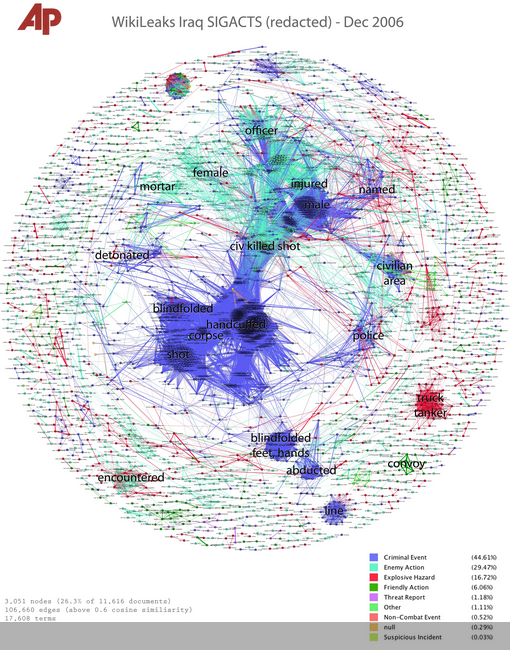
Jonathan Stray (adatújságíró és programozó) az Associated Press-nél vezette a szöveges megjegyzések feldolgozására irányuló munkát és felismerte, hogy egy általános problémával került szembe. Nem csak a kiszivárogtatások során özönlenek a dokumentumok a szerkesztőségekre. Az ún. FOIA (információs szabadság törvények által biztosított jog) keretében kikért információt a hatóságok gyakran szeretik átadni sok lényegtelen kísérő dokumentummal. A törvényes, ám cseppet sem etikus eljárás célja, hogy minél később akadjon az információt kérő a számára fontos adatokra. Ám maguk a szerkesztőségek is sok adatot halmoztak fel archívumaikban, melyek "cikkekbe" vannak zárva. A nyelvtechnológia segít abban, hogy kinyerhessük a szükséges információt és Holovaty elveinek megfelelően külön eltárolhassuk az adatokat. Stray a Knight Foundation támogatásával elindította az ilyen problémák megoldására alkotott The Overview Project-et (amit egy korábbi írásunkban már bemutattunk).
A technológia és az újságírás sikeresen egymásra talált a közelmúltban és sokan gondolták azt, hogy az adatok korában a társadalomtudományi ihletettségű ún. precíziós újságírás (precision journalism) pepecselős adatgyűjtése helyett, a nyílt és az ilyen-olyan módon megszerezhető adatok leveszik a kutatás terhét az újságírók válláról. A 2011-es angliai zavargások azonban rámutattak arra, hogy nem ilyen egyszerű a helyzet - sorozatunk következő részében erről számolunk be.
