A blog készítői a Precognox Kft. keretein belül fejlesztenek intelligens, nyelvészeti alapokra épülő keresési, szövegbányászati, big data és gépi tanulás alapú megoldásokat.
Az alábbi keresődobozsegítségével a Precognox által kezelt blogok tartalmában tudsz keresni. A kifejezés megadása után a Keresés gombra kattintva megjelenik vállalati keresőmegoldásunk, ahol további összetett keresések indíthatóak. A találatokra kattintva pedig elérhetőek az eredeti blogbejegyzések.
Ha a blogon olvasható tartalmak kapcsán, vagy témáink alapján úgy gondolod megoldással tudunk szolgálni szöveganalitikai problémádra, lépj velünk kapcsolatba a keresovilag@precognox.com címen.
Precognox Blogkereső
Document
opendata.hu
Az opendata.hu egy ingyenes és nyilvános magyar adatkatalógus. Az oldalt önkéntesek és civil szervezetek hozták létre azzal a céllal, hogy megteremtsék az első magyar nyílt adatokat, adatbázisokat gyűjtő weblapot. Az oldalra szabadon feltölthetőek, rendszerezhetőek szerzői jogvédelem alatt nem álló, nyilvános, illetve közérdekű adatok.
A long time ago, in a galaxy far, far away data analysts were talking about the upcoming new Star Wars movie. One of them has never seen any eposide of the two trilogies before, so they decided to make the movie more accessible to this poor fellow. See more...
A Kereső Világ blogon közölt tartalmak a Precognox Kft. tulajdonát képezik. A tartalom újraközléséhez, amennyiben nem kereskedelmi céllal történik, külön engedély nem szükséges, ha linkeled az eredeti tartalmat és feltünteted a tulajdonos nevét is (valahogy így: Ez az írás a Precognox Kft.Kereső Világ blogján jelent meg). Minden más esetben fordulj hozzánk, a zoltan.varju(kukac)precognox.com címre írt levéllel.
Cégünk az Interstack-kel kötött megállapodás keretein belül megjelent az Egyesült Államok piacán is. Persze eddig is jelen voltunk a legfontosabb IT piacon, ahogyan referenciáink is mutatják, de az együttműködés keretében további lehetőségek nyíltak meg előttünk.
A seattle-i székhelyű Interstack felhőalapú analitikai szolgáltatásokat kínál ügyfeleinek.
A cég filozófiája, hogy az ügyfeleket maximálisan kiszolgálja és ne gátolja a modern technológia. A Filelytics nevű termékük lehetővé teszi a közösségi média monitorozását és szentimentelemzését, mindeközben nem igényel különösebb előképzettséget használata és könnyen beállítható az igények szerint. A Loyal Channel és a Share Your Experience alkalmazások pedig az egyes termékekkel és szolgáltatásokkal kapcsolatos fogyasztói visszajelzések begyűjtését és elemzését könnyítik meg.
Büszkék vagyunk arra, hogy az Interstack partnere lehetünk és ügyfeleink igényeit még jobban kiszolgálhatjuk! Megállapodásunkról a Figyelő és a HVG.hu alábbi cikkeiből tudhat meg többet a kedves olvasó:
A Kereső Világ a Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Minden szülő fontosnak tartja, hogy gyermeke számára megtalálja a legmegfelelőbb nevet, de persze közben egyetértünk Júliával abban, hogy nem a név fontos egy ember megítélésében:
Mi is a név? Mit rózsának hívunk mi,
Bárhogy nevezzük, éppoly illatos.
Így, hogyha nem hívnának Romeónak,
E cím híján se volna csorba híred.
De tényleg így van ez? Hiszen nevünk az esetek többségében jelzi nemünket, a változó névadási szokások utalhatnak korunkra, de társadalmi és vagyoni helyzetünkre is - a vezetéknevekről ne is beszéljünk.
Mostanában szinte minden ismerősöm szülő lett és azt vettem észre, hogy a legtöbb baba az Eszter, Anna, Jázmin, Hanna és Bence, Máté, Levente neveket kapta, melyek az utóbbi évek legnépszerűbb keresztnevei. Elkezdtem hát figyelni, milyen gyerekneveket hallok a környezetemben és a Dzsenifer, Dzsesszika, Vivien nyert a lányoknál, a Kevin, Krisztofer és Martin a fiúknál. Ismerőseim és barátaim a középosztály tagjai, általában magasan képzettek és nagyvárosokban laknak. Én viszont egy olyan kistérségben lakok, ahol a munkanélküliség és a roma lakosság aránya egyaránt kb. 20%. Talán önmagában az, hogy valakit Kevinnek hívnak nem árulkodik arról, milyen szociokulturális közegből érkezik, de mi a helyzet Szabó Kevinnel és Lakatos Kevinnel? Lehet, nevünk nem csak nemünket, de korunkat és társadalmi hátterünket is elárulja?
A nevek gazdaságtana
Hazánkban különböző okok miatt nem gyűjtenek nemzetiségre vonatkozó adatokat az újszülöttekről és szüleik hátteréről. Azonban Roland G. Fryer Jr. és Steven D. Levitt a kaliforniai születési statisztikákat használva érdekes eredményeket tártak fel a nevekkel kapcsolatban. A két kutató a szülők lakhelyét használva következtetett etnikai hovatartozásukra és a kórházi számla kiegyenlítésének módjából pedig anyagi helyzetükre. További hasznos fogódzót jelentett nekik, hogy Kaliforniában rögzítik az anya családi állapotát, korát és iskolai végzettségét is. Ezen adatok birtokában már empirikusan is bizonyítható volt az, amit sokan sejtettek; a feketék névadási szokásai jelentősen eltérnek a többségi társadalométól, ahogy az alábbi táblázat is mutatja (forrás Freakonomics):
A “legfehérebb” lánynevek
A “legfeketébb” lánynevek
A “legfehérebb” fiúnevek
A “legfeketébb” fiúnevek
1.
Molly
Imani
Jake
DeShawn
2.
Amy
Ebony
Connor
DeAndre
3.
Claire
Shanice
Tanner
Marquis
4.
Emily
Aaliyah
Wyatt
Darnell
5.
Katie
Precious
Cody
Terrell
6.
Madeline
Nia
Dustin
Malik
7.
Katelyn
Deja
Luke
Trevon
8.
Emma
Diamond
Jack
Tyrone
9.
Abigail
Asia
Scott
Willie
10.
Carly
Aliyah
Logan
Dominique
11.
Jenna
Jada
Cole
Demetrius
12.
Heather
Tierra
Lucas
Reginald
13.
Katherine
Tiara
Bradley
Jamal
14.
Caitlin
Kiara
Jacob
Maurice
15.
Kaitlin
Jazmine
Garrett
Jalen
16.
Holly
Jasmin
Dylan
Darius
17.
Allison
Jazmin
Maxwell
Xavier
18.
Kaitlyn
Jasmine
Hunter
Terrance
19.
Hannah
Alexus
Brett
Andre
20.
Kathryn
Raven
Colin
Darryl
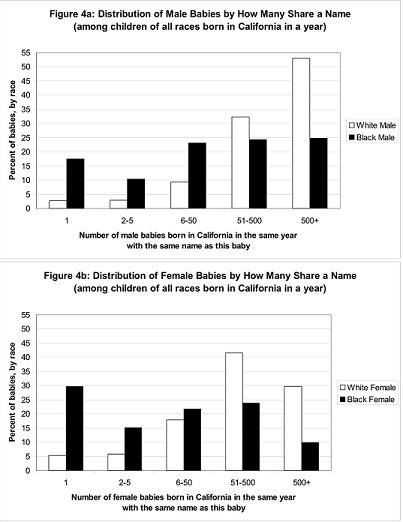
Szintén különös fejlemény, hogy a fekete közösségen belül egyre kevesebb gyerek kapja ugyanazt a nevet, ahogy az alábbi ábra is mutatja.
Ezáltal önmagában az a tény, hogy valakinek különleges neve van egyre jobban jelzi, hogy nem a többségi társadalom tagja. Hogy ez jó vagy rossz? Attól függ milyen a társadalmi környezet, önmagában a név nem okozója a különbségeknek, sokkal inkább oka.
Ugyanakkor érdemes odafigyelni Sendhill Mullainathan és tsai vizsgálataira is, mely bebizonyította, a név igen komoly akadály lehet a munkaerőpiacon. Mullainathan nagyon egyszerű és ötletes kísérlettel állt elő: két ugyan olyan képzettséggel és előélettel rendelkező fiktív személy önéletrajzát írták meg és küldték el álláshirdetésekre, a két pályázó közötti egyedüli eltérés a nevük volt; egyikük szép hagyományos fehér nevet kapott, míg a másik igazi afro-amerikait. Az eredmények szerint harmad annyi esélye van a fekete névvel rendelkező személyeknek arra, hogy felhívják őket, mint a fehéreknek...
Név = nem, kor, jövedelem
De kanyarodjunk vissza a szegmentáció kérdéséhez! Ha van megfelelő adatunk, úgy tűnik pusztán keresztnév alapján is sokat megtudhatunk egy emberről. Tyler Schnoebelen egyik tavalyi meetupunkon elmondta, hogy vizsgálódásaik során a férfi- ill. nő nevek listáival határozták meg vizsgálati alanyok nevét és a névadási statisztikákat használva nagy hatékonysággal tippelték meg korukat is!
Fryer és Levitt nagyon sok változót megvizsgált, ezek közül szemezgetve az egyik legkirívóbb, az anya iskolázottsága és a gyermek neve közötti kapcsolat. A fehér lánynevek közül az alábbiak jelzik a leginkább az anyuka iskolázottságát években megadva.
A húsz leggyakoribb alacsony iskolázottságot jelző fehér lánynév (forrás Freakonomics)
(Zárójelben az anya iskolázottsága években kifejezve)
1. Angel (11.38)
2. Heaven (11.46)
3. Misty (11.61)
4. Destiny (11.66)
5. Brenda (11.71)
6. Tabatha (11.81)
7. Bobbie (11.87)
8. Brandy (11.89)
9. Destinee (11.91)
10. Cindy (11.92)
11. Jazmine (11.94)
12. Shyanne (11.96)
13. Britany (12.05)
14. Mercedes (12.06)
15. Tiffanie (12.08)
16. Ashly (12.11)
17. Tonya (12.13)
18. Crystal (12.15)
19. Brandie (12.16)
20. Brandi (12.17)
A szülők, különösen az anya, iskolázottsága az egyik legmeghatározóbb faktora a gyermek jövőbeli iskolázottságának és jövedelmének. Az eddig bemutatott adatok a kilencvenes évekre vonatkoznak, de Steven D. Levitt és Stephen J. Dubner Freakonomics című könyvükben kitértek a névadási divatokra is. Ha megnézzük a kétezres években az alacsony és a közepes jövedelmű családok névadási szokásait, akkor jelentős átfedéseket látunk a két csoport között - vessünk egy pillantást a lánynevekre (forrás Freakonomics)
kis jövedelmű családok népszerű lánynevei
közepes jövedelmű családok népszerű lánynevei
1.
Ashley
Sarah
2.
Jessica
Emily
3.
Amanda
Jessica
4.
Samantha
Lauren
5.
Brittany
Ashley
6.
Sarah
Amanda
7.
Kayla
Megan
8.
Amber
Samantha
9.
Megan
Hannah
10.
Taylor
Rachel
11.
Emily
Nicole
12.
Nicole
Taylor
13.
Elizabeth
Elizabeth
14.
Heather
Katherine
15.
Alyssa
Madison
16.
Stephanie
Jennifer
17.
Jennifer
Alexandra
18.
Hannah
Brittany
19.
Courtney
Danielle
20.
Rebecca
Rebecca
Az adatokat megvizsgálva arra jutott a szerzőpáros, hogy a kis jövedelmű családok névadási szokásai pár év késéssel követik a felsőbb osztályokét, ez okozza a jelentős átfedést.
Vezetéknevek
Sajnos hasonló magyar vonatkozású adatokról nincs tudomásunk - ha valakinek van, kérjük írjon nekünk! A vezetéknevekkel most nem foglalkoztunk, de nem állunk talán messze az igazságtól, ha feltesszük, bizonyos esetekben jól jelzik az etnikai hovatartozást (az afro-amerikaiak körében az adatok szerint ez így van).
A gyakorlatban
A nevek önmagukban nem érdekesek, ez ellen csak a névtannal foglalkozó szakembereknek lehet kifogása. Viszont, ha sok adat mellett rendelkezünk a vizsgált alanyok nevével is, akkor jelentősen megkönnyíthetik a felhasználók szegmentálását nem, kor és akár iskolázottság/jövedelem szerint is. Pl. a Neticle újdonsága a nemek szerinti szegmentálás, így már nem csak a a populáció egészére adnak véleményárfolyamot, hanem férfi-női bontásban is. További felhasználási terület lehet, a más módszerekkel nyert eredmények validálása is - de persze csak akkor, ha van megfelelő minőségű és mennyiségű adat!
A Kereső Világ a Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Hamarosan tőzsdére megy a Twitter, ami annyira magával ragadta a befektetőket, hogy október 4-én egy a csőd szélén álló elektronikai cikkeket árusító cég, a Tweeter részvényei 1800%-ot növekedtek, hála annak, hogy a kereskedési rendszerben TWTRQ kód alatt futnak. A történet jól mutatja, mennyire várják a csiripelős cég TWTR kód alatti bevezetését, de tényleg bomba üzlet lesz? Honnét vannak és a mi még fontosabb, honnét lesznek bevételei a "legöregebb startupnak"?
Minden elemző a Twitter felhasználók számát, a penetráció bővülésének gyorsaságát vagy éppen lassulását szereti megemlíteni, no meg azt, milyen hatással vannak a kis 140 karakteres üzenetek hírfogyasztási szokásainkra (persze nem hazánkban, hanem a világ azon részén, ahol a Facebookon kívül ismernek más közösségi oldalakat is). Ez alól a Bloomberg szakértői sem kivételek:
Sokak szerint a Twitter a tartalomipar felé is kacsingat, hiszen immár saját adatszerkesztőjük is van Simon Rogers, a Guardian Datablog alapítójának személyében. Az arab tavasz, a török és brazil tiltakozási hullámok mind-mind arra utalnak, hogy a csiripek megváltoztatták a híreket. Habár biztosak vagyunk abban, hogy a Rogers és társai nagyon izgalmas projektekkel fognak jelentkezni hamarosan, mi inkább arra szeretnénk felhívni a figyelmet, hogy a Twitter adatai köré egy komplett ökoszisztéma épült fel, amiből eddig a cég még nem sokat profitált!
Aki dolgozott már a Twitter API-val, az szembekerülhetett a historikus adatok hiányával. Persze lehetne archiválni magunknak a csiripeket, de egyrészt nem teljesen konform a felhasználási feltételekkel, másrészt kifejezetten tilos a nyers adatokat tovább adni. Ezzel nincs is semmi baj, amíg nem akarunk komolyabb elemzéseket végezni, amihez nem árt, ha idősoros adataink vannak. Ilyen pl. a Cayman Atlantic esete, ami befektetési elemzéseket végez. A Twitter Certified Products néven külön biztosít hozzáférést analitikai partnereinek és az adatok viszonteladóinak.
A Facebook nagyon korlátozottan teszi elérhetővé adatait a szélesebb felhasználói közösségnek és egyedi alapon csak a kiválasztottak láthatnak bele mélyebben az adatbázisaiba. A Twitter jellegénél fogva sokkal nyíltabb, ennek köszönhetően rengeteg alkalmazás épült már ki köré, ezek jelentős része függ az elérhető adatoktól. Itt nem a barátok csoportosítását végző applikációkra gondolunk, hanem a Cayman Atlantic-re vagy éppen a Bloomberg Terminal-ra, melyekhez jelenleg viszonteladóktól veszik meg a szükséges adatokat.
A Twitter jövőjét szerintünk két dolog határozza meg alapvetően; 1) sikerül-e fenntartani a felhasználók érdeklődését, azaz továbbra is népszerű hírmegosztó oldal tud-e maradni a Twitter 2) milyen gyorsan sikerül átültetni a gyakorlatba az olyan úttörő kutatási eredményeket mint pl. Bollen és társainak választási előrejelzése vagy nyelvi viselkedés alapján felállított pszichológiai profilozás. Így a Twitter jövőjét nem a marketing megoldások jelentik (ezzel nem mondjuk azt, hogy ezek nem hozhatnak szép bevételt!), hanem az adatok gondozása és továbbadása üzleti felhasználók számára.
A Kereső Világ a Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Az egyik legnagyobb nyelvészlegenda, George Lakoff a CEU-n tart előadást 2013. október 16-án 11 órától. Az IARPA Metaphor projektje kapcsán minden rendes nyelvtechnológiai szakember is minimum hallott a mesterről, most élőben is lehet őt csodálni!
Date: October 16, 2013 - 11:00 - 12:30
Building: Frankel Leó út 30-34.
Room: 101
A general overview of a theory of embodied cognition under development by myself and Srini Narayanan. It will begin with basic cognitive linguistics: Embodied Schemas, Frames, Conceptual Metaphor and Metonymy, Blends, Constructions, and the basic experiments, and will present in general form a theory of the neural circuitry needed to characterize these phenomena in detail. The presentation will be informal and for a nontechnical audience. It will flesh out the presentation on Neural Politics given the previous day. (Bővebb információ)
A Kereső Világ a Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Itt a big data, Hal Varian is megmondta, hogy a 21. század legszexibb foglalkozása lesz a statisztikus, de elveszettnek érzi magát a kedves olvasó az adatok tengerében és zavartan bólogat miközben adatújságírásról, Pearson korrelációról vagy éppen Kendall tauról beszélnek hipszter ismerősei? Megnyugtatjuk, nagyon kevesen értik miről is szól az adatok kora, még kevesebben vannak azok, akiknek volt kb. 60. 000 USD a zsebükben egy a UC Berkeley data science mesterképzéséhez hasonló diploma megszerzéséhez. Jó hírünk is van, ha szorgalmas a kedves olvasó, akkor a józan paraszti ész mellé csak egy laptopra és internethozzáférésre van szüksége ahhoz, hogy megértse a nagy szavakat és saját maga is vizsgálhassa az adatokat - nem mellesleg saját tapasztalatunk szerint ezzel már többet fog tudni, mint a legtöbb önjelölt szakember.
Az Open Knowledge Foundation School of Data programja remek alapozó kurzust kínál, amit tényleg bárki elkezdhet, aki tud egy kicsit angolul és rendelkezik megbízható IT felhasználói alapismeretekkel (pl. tudja hol keresse a táblázatkezelő szoftvert a gépén, képes telepíteni önállóan egy programot). Az alapozó kurzust érdemes végigcsinálni, a leckék nem túl rövidek és nem emészthetetlenül hosszúak. Haladóknak érdemes egy Data Expedition-höz, azaz adatfelfedező akcióhoz csatlakozni. A School of Data annak ellenére, hogy alig egy éves, máris rengeteg használható anyagot tartalmaz. Egyetlen hátránya, hogy az alapozó kurzus és az expedíciók szintje között nincs anyag, sokak számára nehéz lehet az egyszerű feladatok után hirtelen éles bevetésre menni, de állítólag a csapatok segítőkészek és nem szólják le a zöldfülűeket.
"Az adatokkal történeteket kell mesélni" mondat minden rendes big data könyvben, cikkben és beszélgetésben előjön. A kérdés az, hogy hogyan csináljuk ezt! Ehhez ad tippeket az ingyenesen hozzáférhető Data Journalism Handbook.
A nyílt adatokról sokat hallunk manapság, de mit is jelent az, ha egy adathalmaz nyílt? Az Open Knowledge Foundation Open Data Handbook-ja ebben segít eligazodni. Kezdőknek elsőre a függeléket ajánljuk, ami gyorsan eligazít mindenkit a leggyakrabban használt fájlformátumok és licencek világában.
A statisztika nem kerülhető meg, ha valaki adatokkal foglalkozik. A Coursera, az edX és a Udacity is ajánl remek bevezető kurzusokat, érdemes a linkeket követni és szétnézni az oldalakon. Mi most a CMU Open Learning Initiative ajánlatára hívjuk fel a figyelmet. Ezek minőségükben messze a többi felett állnak és sokkal kezdőbarátabbak is, az pedig csak hab a tortán, hogy bármikor el lehet kezdeni őket és mindenki a saját tempójában haladhat az anyaggal. A Statistical Reasoning kurzus inkább "filozófiai" és igyekszik a valószínűségi és statisztikai gondolkodás hátterét megvilágítani, a Probability and Statistics pedig gyakorlatiasabb (érdemes mindkettőt elvégezni!)
A Kereső Világ a Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.