A napokban jelentette be a Google, hogy a keresőmotor jelentős átalakuláson megy (és már ment) keresztül. Az új motor a Hummingbird kódnevet kapta és a bejelentés szerint sokkal jobban ki tudja szolgálni a manapság egyre népszerűbb beszédvezérelt válaszkeresést. A Guardian érthetően és röviden összefoglalta a lényeget, a Webisztán pedig rámutatott arra, hogy ezzel egyben lassan el is köszönhetünk a kulcsszavaktól, mi pedig megvilágítjuk miért válnak egyre lényegtelenebbé a kulcsszavak, miért kell jobban koncentrálni a tartalomra és mi köze van ennek a Knowledge Graph-hoz.

Bye-bye keywords, hello topics!
Már 2010-ben sokan gyanakodtak arra, hogy a Google valamilyen formában használja a látens dirichlet allokáció (latent dirichlet allocation, vagy röviden LDA) módszerét a találatok rangsorolására. Egy gyors keresés a Google Research oldalon megerősít minket abban, hogy az eljárás nagyon foglalkoztatja a keresőóriás kutatóit.
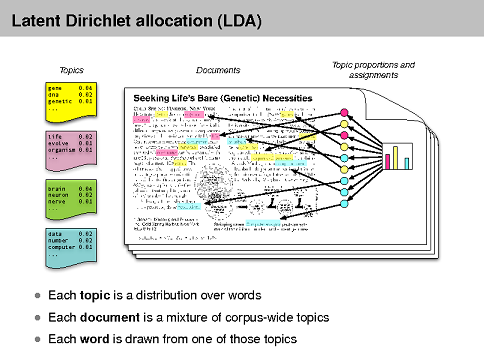
Az LDA módszert tekinthetjük egy klasszifikációs eljárásnak, abból a szempontból, hogy az egyes dokumentumokhoz ún. topikszavakat rendel. Vegyünk egy konkrét példát, amiben az alábbi mondatokhoz hasonló rövid szövegek szerepelnek:
- Szeretek banánt és almát enni.
- Répát és körtét eszek minden este vacsorára.
- A kutyák és a macskák aranyos háziállatok.
- A testvérem tegnap örökbefogadott egy macskát a menhelyről.
- Nézd azt a nyuszit, milyen aranyosan majszolja az almát!
Az LDA elemzés során két topikot keresünk. 1) és 2) mondatokat egy topikhoz, nevezzük A-nak, sorolná az algoritmus. 3) és 4) szintén egy topikhoz tartozik, legyen ez most B. 5) esetében azt mondhatjuk, 50%-ban A, 50%-ban pedig B topikhoz tartozik. A többi mondathoz A és B arányát 0 és 100% között adja meg, végül listázza az A (pl. banán, alma, répa, körte, dinnye, uborka, zsemle, kenyér, vaj, reggeli, ebéd, vacsora stb.) és B (kutya, macska, aranyhal, nyuszi, egér, hörcsög stb.) topikszavakat.
Általánosságban az LDA algoritmusnak megadjuk hány topikot szeretnénk azonosítani. Ezután az egyes dokumentumokban szereplő szavak eloszlása alapján kapjuk meg a topikszavakat. Hogy miért jó ez nekünk? Hagyományosan az információkinyerő és kereső alkalmazások a dokumentumhalmazban előforduló szavak gyakoriságán alapuló eljárásokat alkalmaznak klasszifikációra és az egyes dokumentumok közötti hasonlósági metrikák megállapítására. Habár ezek sok feladatra kiválóan megfelelnek, az LDA eredményei konzisztensek és természetesek (ez alatt azt értjük, hogy ha "nevet adunk" egy-egy topik listának, az általában megfelel egy humán erőforrásokkal azonosított topiknak, továbbá gyakran olyan szavakat is tartalmaz, amire az ember nem is gondolná, hogy jó megkülönböztető jegye lehet egy topiknak):
Az nTopic a webes tartalmak elemzése révén állapítja meg, hogy milyen topikszavak tartoznak egy adott tartalomhoz, s ez alapján tesz ajánlásokat a SEO szakembereknek a megfelelő kulcsszavak kiválasztásához. Érdemes ugyanakkor megjegyezni, hogy egy topikszavakból álló lista eltér a hagyományos keresési kulcsszavaktól, hiszen ez tkp. egy ajánlás arra nézve, hogy tartalmunkban milyen terminológiát alkalmazzunk.
Minden gráf!
A híres PageRank algoritmus a honlapok közötti linkek alapján felépített gráf struktúrán keresi és rangsorolja egy adott keresés találatait.
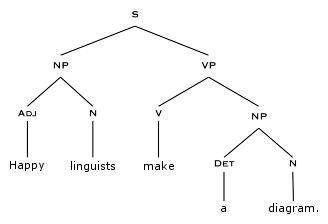
Egy mondat szintaktikai elemzése is egy fát eredményez.
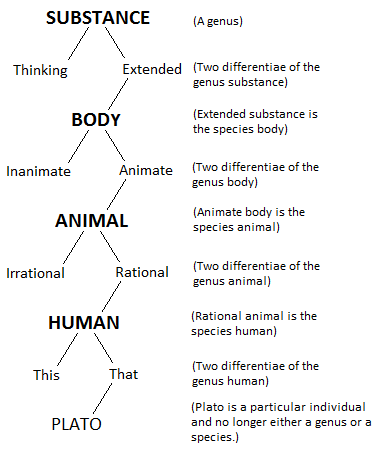
És az emberi tudást reprezentáló szimbolikus rendszerek is szeretik a gráfokat. Porfüriosz fája egy Arisztotelész kategóriái nyomán készült egyszerű "döntésfa", ami segít rendszerezni minden élő és élettelen létezőt.
A linked data is az arisztotelészi hagyományt viszi tovább. A Freebase, melyet a Google által felvásárolt Metaweb alkotott meg 2006-ban, is egy linkelt adathalmaz, amit a felhasználók szerkesztenek.

A Google Knowledge Graph a Freebase adataira épül, de kiegészítették automatikusan generálható tudáselemekkel (a Wikipedia és egyéb wikik ilyen felhasználása ma már bevett gyakorlat) és szabadon felhasználható linked data adatokkal.
Szemantikus keresés és SEO
Minden hipochonder álma egy orvos ismerős, de ha jogi gondunk akad szeretnénk gyorsan találni egy ismerős ügyvédet és kedvenc hentesünk véleményét kérjük ki, hogy jó steaknek való húst szerezzünk be. A szakértők sajátos szótárat használnak és ismerik a szakszavak közötti hierarchiát. A keresőtől egyre inkább azt várjuk el, hogy ilyen szakértő tanácsadó legyen. A topikokat megfeleltethetjük a szakzsargonnak, a topikszavak közötti hierarchiát pedig a Knowledge Graph-nak. A legegyszerűbb keresőoptimalizálási trükk ebben a paradigmában az, ha minőségi tartalmat készít számunkra egy szakértő, vagy keresünk valakit, aki képes rövid időn belül otthonosan mozogni egy területen és jó tartalmat készíteni (ezt nevezzük újságírónak). Jól jöhet még egy nTopic-hoz hasonló eszköz a terminológia megválasztásához, ennek hiányában érdemes szövegergonómiai szakértőhöz fordulni.