


Sokak fejében élő sztereotípia a tarisznyás bölcsész, aki a könyvtárban (és/vagy a büfében) tölti élete nagy részét, világmegváltó dolgokról elmélkedve, de üres zsebbel, az információ technológia világától távol érthetetlen (haszontalan) dolgokkal foglalkozva. Viszont a közhiedelemmel ellentétben a bölcsészettudományok művelőit sem kerülte el az IT forradalom, mégpedig annyira nem hogy mára kialakult az ún. digitális bölcsészet irányzat, amit angol neve (digital humanities) után gyakran csak DH-nak hívunk. Ez a terület a források digitalizálásával és kereshetővé tételével foglalkozik.
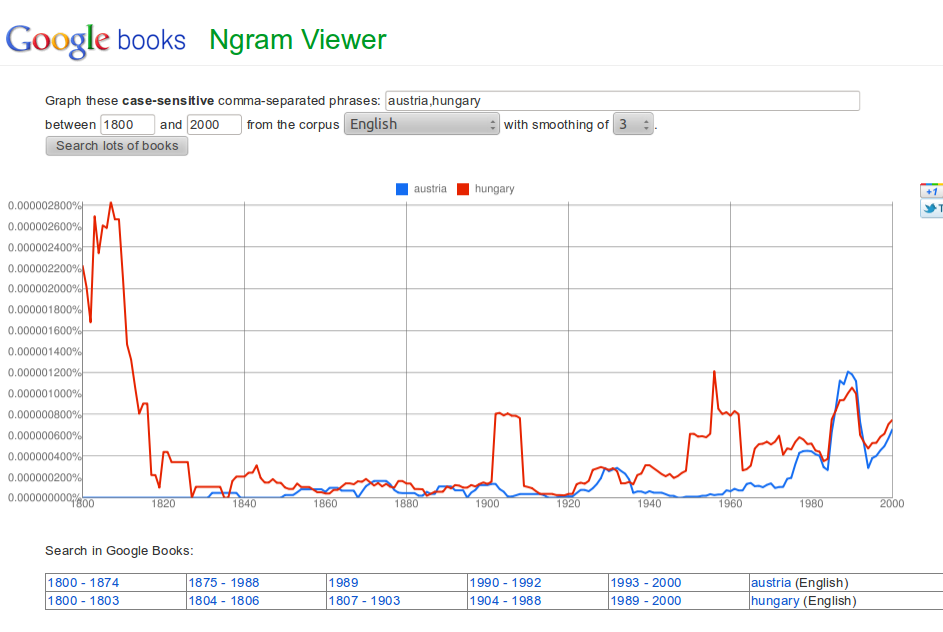
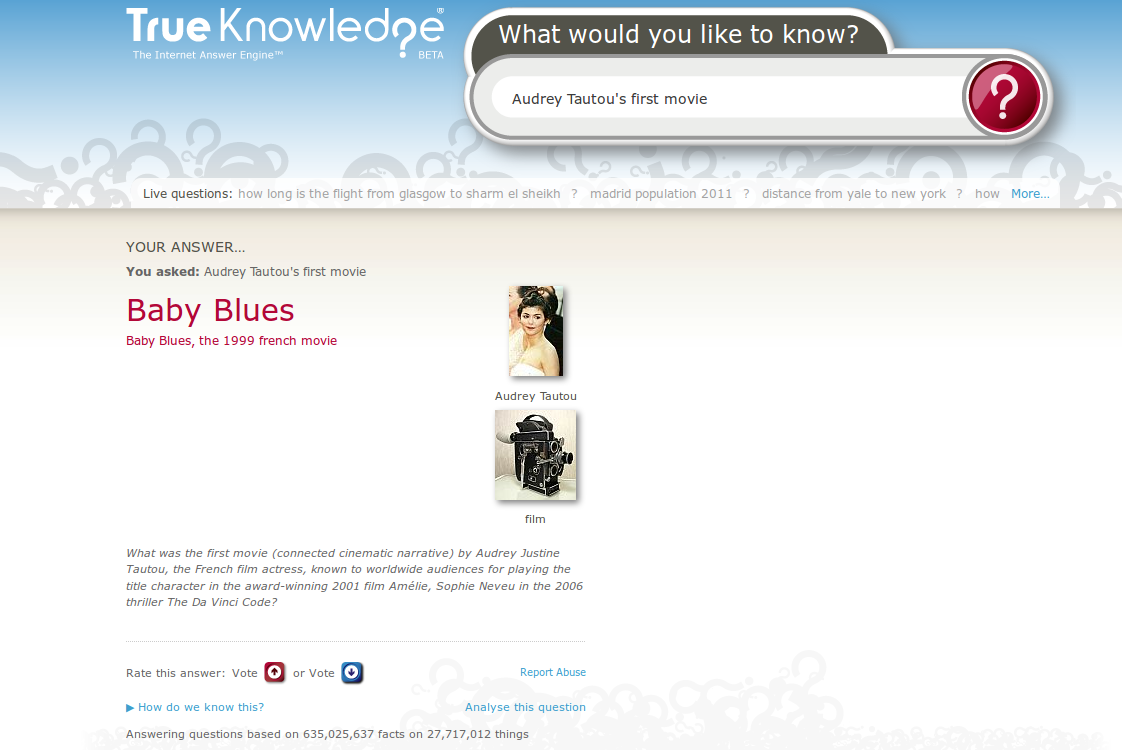
A tavaly elindult Google Ngram Viewer talán a legismertebb DH projekt. A Google könyvdigitalizálási projektjének “melléktermékeként” egy olyan többnyelvű szöveghalmaz (más néven korpusz) jött létre ami lehetővé teszi hogy bizonyos trendeket nyomon kövessünk. Maga az adathalmaz úgynevezett bag of words modellen alapul, azaz nem a konkrét műveket hanem a bennük előforduló szavakat (gyakoriságukkal együtt) tartalmazza, így megkerülve a szerzői jog kérdéseit is. Hogy mennyire lehet releváns következtetéseket levonni egy ilyen eszközre alapozva az kérdéses (az eszköz köré szerveződött Culturomics kutatócsoport szerint sok dologra releváns választ kaphatunk), annyi azonban biztos hogy bizonyos trendeket nagyon jól ki lehet venni. Pl. ábránkon jól látható hogy az “austria” és “hungary” szavak gyakorisága a szabadságharc idején nagyon eltérő tendenciát mutat, ahogy a kiegyezés, úgy az első világháború körüli időben is többször említik hazánkat. A két világháború közötti időben ismét összetartanak a trendek, majd az ötvenes években megint hatalmas ugrás következik. Érdekes hogy a rendszerváltás és az azt követő időszak során tulajdonképpen hasonló gyakorisággal fordul elő a két ország neve.
A Stanford University The Human Experience – Digital Humanities projektje sok, izgalmas kezdeményezést fog össze a DH területén. A legizgalmasabb a “Mapping the Republic of Letters” kezdeményezés, ami a felvilágosodás korának kiterjedt levelezését mutatja be vizuálisan. Habár eddig is tudtuk hogy ebben a korban kiterjedt levelezést folytattak a tudós elmék, térképre vetítve a közöttük fennálló kapcsolatokat megdöbbentő hogy mennyire nyüzsgő és milyen sok kapcsolatból álló hálók rajzolódnak ki.
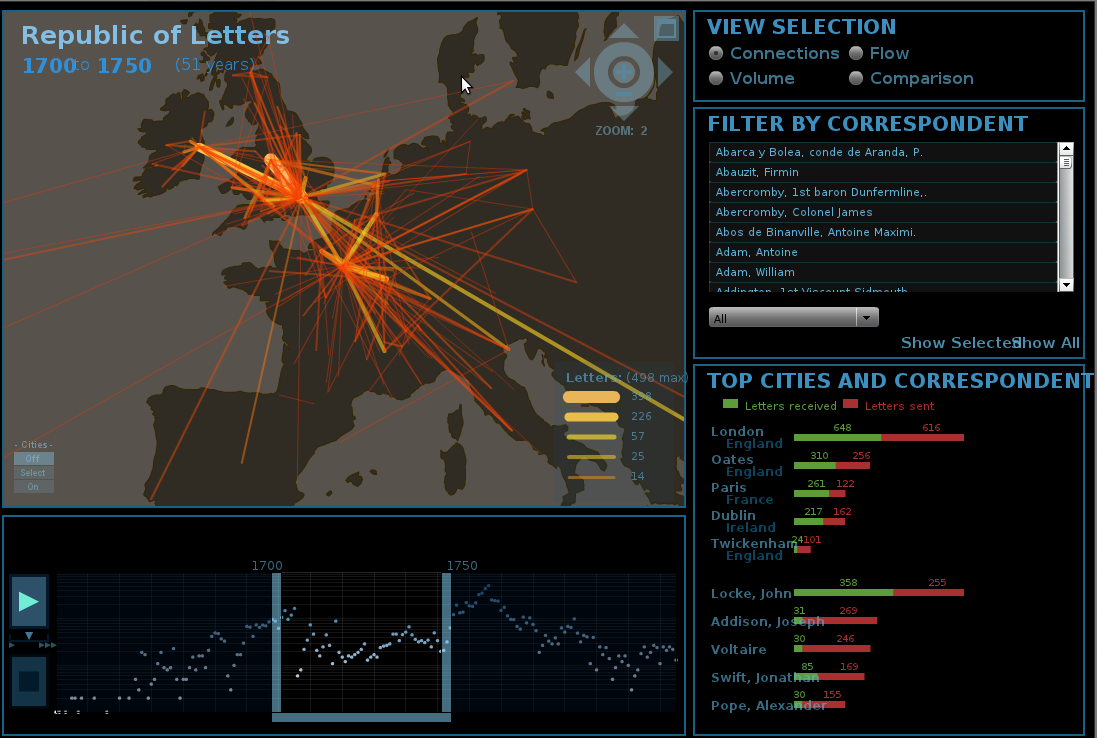
Ahhoz hogy ilyen szép vizualizációkat jelenítsünk meg, szükségünk van a levelek digitalizált változataira és az automatikus feldolgozására (pl. a szerző és a címzett kinyerésére, a keletkezési hely és a dátum megtalálása stb.) amihez elengedhetetlen a modern szövegbányászati és keresési eszközök használata. Ezek az eszközök sokkal inkább szemléltetik azt amit eddig is tudtunk, ez önmagában is eredmény, de mit tud nyújtani a keresés az elmélyültebb kutatói munkának?
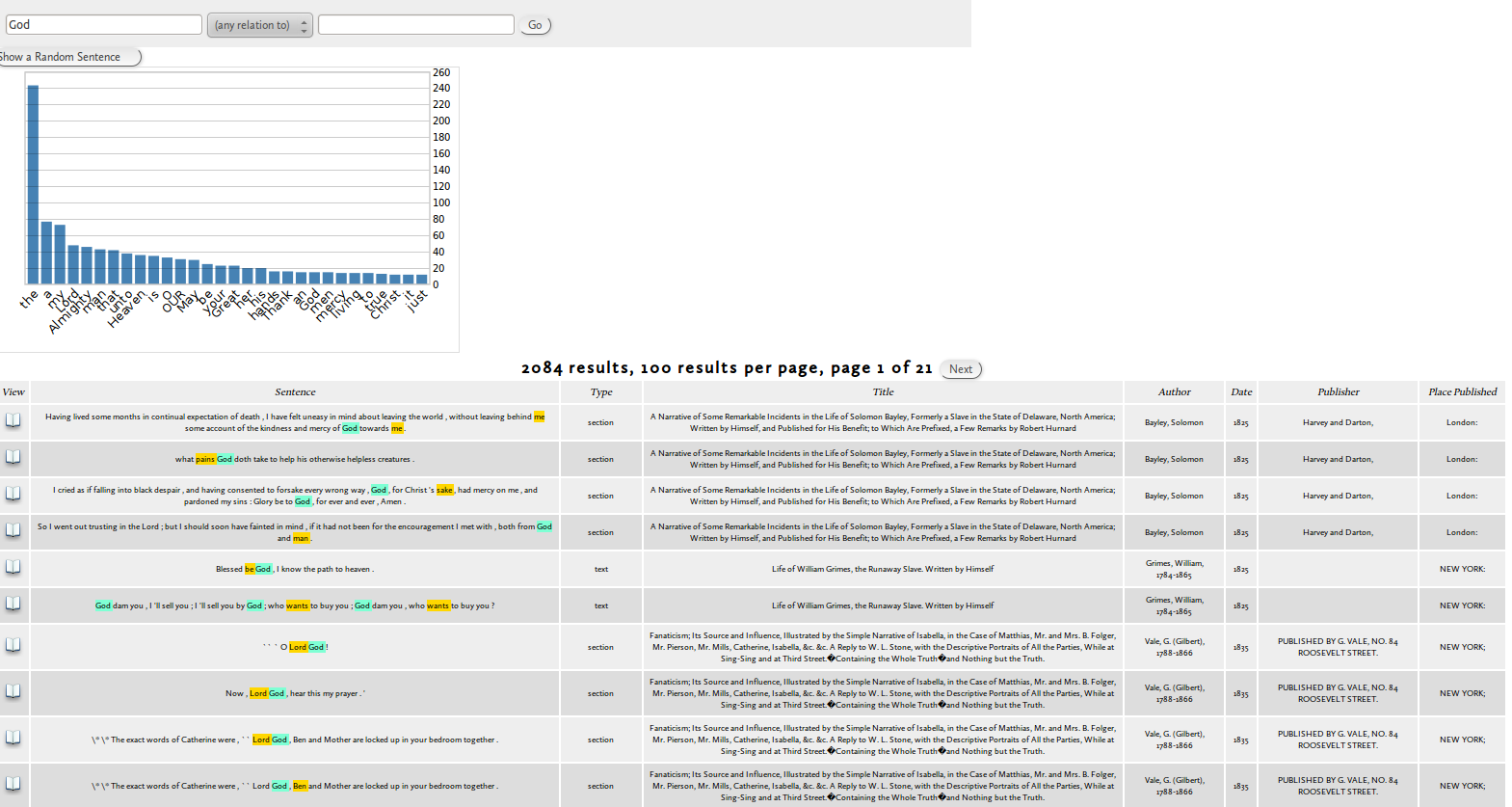
Aditi Muralidharan a Berkeley PhD hallgatója egy olyan alkalmazást álmodott meg ami lehetővé teszi hogy a szövegekben különböző, a szavak között fennálló viszonyokra kereshessünk. Ez önmagában még nem nagy újdonság, a korpusznyelvészetben régóta bevett dolog, azonban a WordSeer felülete nem igényel különösebb előképzettséget, és az eredmények is rögtön értelmezhetőek. Kérjünk le pl. egy véletlenszerűen kiválasztott mondatot a “Slave Narratives” korpuszból.
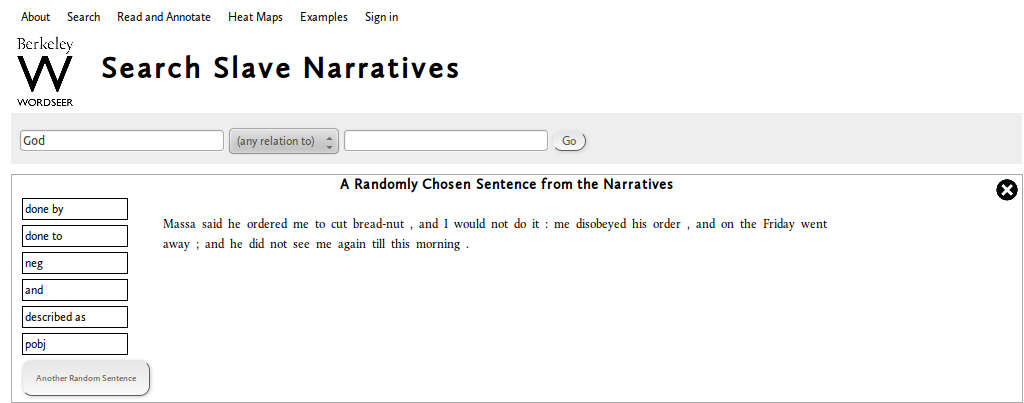
A bal oldalon a menüből választhatjuk ki hogyan elemezze a rendszer a mondatot, a “done by”, “described as” “neg” stb. opciókra kattintva a megfelelő nyelvi konstrukciók kiemelve jelennek meg. Ha látni akarjuk hogy milyen más szavakkal fordulnak elő az adott viszonyban az egyes szavak, vagy hogy milyen viszonyba állhat egymással két vagy több szó, akkor erre is rákereshetünk.
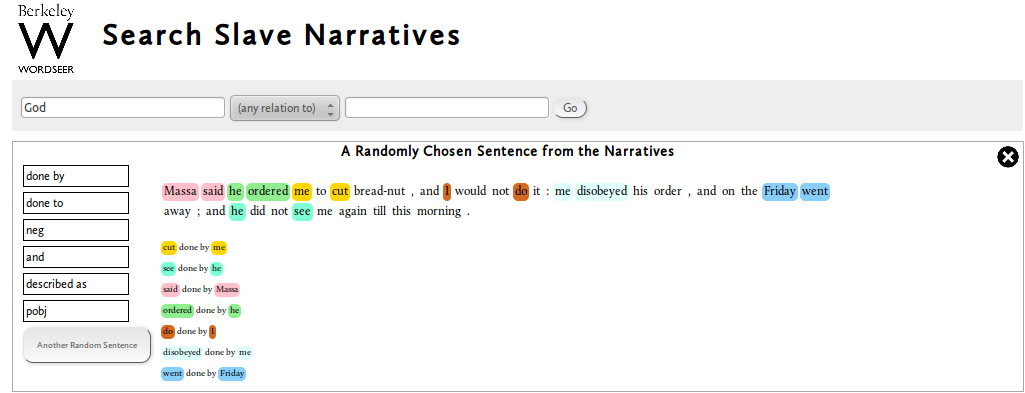
A “God” szóra keresve megkapjuk milyen viszonyokban fordul elő, és az ehhez tartozó mondatokat is láthatjuk. Ha szűkítünk pl. a “described as” viszonyra, láthatjuk miképp írják le Istent ezekben az elbeszélésekben.
A WordSeer nagy figyelmet kapott, hiszen nem csak a kvantitatív (számszerűsíthető, mérhető) munkákhoz használható remekül, hanem a bölcsészettudományokban sokkal gyakoribb és elfogadottabb kvalitatív (értelmező) vizsgálódásokhoz nyújt hasznos adatokat. A rendszer nyílt forráskódú, bárki kipróbáljhatja, módosíthatja és nem csak irodalmi/történelmi szövegekkel működik.
Ahogy egyre több adatot digitalizálunk kitágul a látóterünk, azonban egyre nehezebb is a megszokott módszerekkel feldolgozni a forrásokat. A keresés ezeken a területeken is segíti a felhasználókat. Kultúránk, múltunk és jelenünk megismerése fontos jövőnk szempontjából, a technológia gazdagítja ezt a folyamatot, de tanulhatunk is a felmerülő problémákból. Szerencsére már hazánkban is művelik a DH-t: Kalcsó Gyula Digitális bölcsészet blogját ajánljuk minden érdeklődő figyelmébe.








![Comparison of the Top Three Search Engines: Bing+Yahoo > Google? [INFOGRAPHIC]](http://www.searchenginejournal.com/wp-content/uploads/2011/10/20111004-Top-Three-Search-Engines-Compared.jpg)