



Arra voltunk kíváncsiak, hogyan viszonyulnak egymáshoz a korábbi posztunkhoz begyűjtött korpuszban az egyes szavak, milyen szemantikai teret rajzolnak ki. Aki ismer minket, tudja, nem igazán szeretjük a puszta szógyakoriságon alapuló szófelhőket és helyettük inkább a kulcsszavakat és szógráfokat részesítjük előnyben (l. korábbi posztunkat, melyben Orbán Viktor évértékelő beszédeit elemeztük). Most azonban úgy gondoltuk, a korpusz word2vec modelljének 3D t-sne projekcióján értelmesen meg tudjuk mutatni az 1500 leggyakoribb szót és a közöttük lévő viszonyokat. Szimpla pontokból álló interaktív 3D vizunk itt érhető el, a szavakat is megjelenítő verzió pedig itt. UPDATE: Mivel a vizuk zabálják a memóriát, készítettünk egy csupán 360 szavat tartalmazó verziót is belőlük, ennek dot változata itt érhető el, a szavas változata pedit itt, 1000 szavas dot verzió, ami mutatja az adott szót ha rámegyünk egérrel pedig itt. (A nyájas olvasó figyelmét szeretnénk felhívni, hogy a vizuk nem mobilbarátok! A szófelhős verzió Windowson nem minden esetben működik. Ha túl nagy méretben jelennek meg a szavak, akkor ez az az eset.)
A korpusz magyarlánccal lemmatizált verzióján a gensim segítségével tréneltünk egy word2vec modellt, ennek 3D t-SNE projekcióját az sklearn használatával készítettük el. A szólistában végül csak mellék- és főneveket, illetve a nem azonosított elemeket hagytuk. A 3D vizukat az R threejs könyvtárával készítettük.
Az egér jobb gomját lenyomva tartva mozgatni, a bal gombot lenymva tartva pedig forgatni lehet a vizut, zoomolni pedig scrollozással lehet.
UPDATE:
1500 szó pozíciójának megjelenítése zabálja a memóriát, ezért készítettünk egy felhasználóbarátabb verziót is a vizukból. A négy oldal (444, index, origo, 888) szógyakorisági tábláiból a top 200 elemet vettük és csak ezek pozíciója kerülhetett fel. Külön színnel jelöltük a közös, illetve egy-egy oldal elemeit. Azt vettük észre, hogy így a 888 és az origo között nincs különbség, azaz nagyon egyforma szókincsük van.
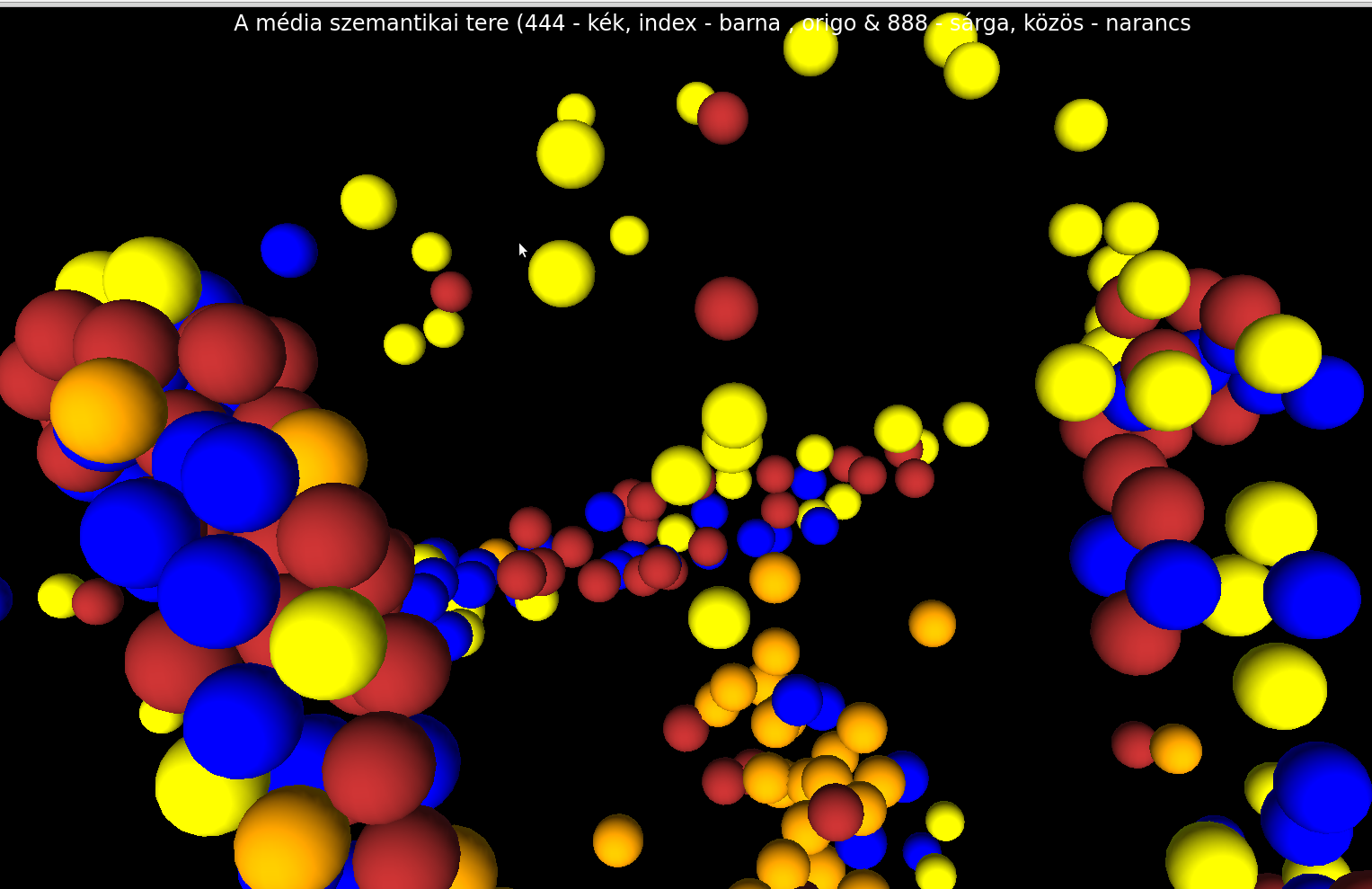

A vizuk az alábbi linkeken érhetőek el:




