



"But it must be recognized that the notion of "probability of a sentence" is an entirely useless one, under any known interpretation of this term." (Chomsky)
Az elmélet vége
Chomsky manapság legtöbbet idézett mondatai mind a valószínűség ellen szólnak. Mindenki szereti idézni ezeket, mert hát annyira bejött az élet a statisztikai nlp-nek, hogy érthetetlen miért is gondolnánk arra, hogy generatív elméletekkel, vagy egyáltalán elméletekkel égessük magunkat. Chris Anderson híres The End of Theory cikkében olyan megállapításokra jut, hogy a tudományos módszernek vége:
But faced with massive data, this approach to science — hypothesize, model, test — is becoming obsolete.
Ami helyette van az tkp. adatgyűjtés és korreláció az adatpontok között:
Petabytes allow us to say: "Correlation is enough." We can stop looking for models. We can analyze the data without hypotheses about what it might show. We can throw the numbers into the biggest computing clusters the world has ever seen and let statistical algorithms find patterns where science cannot.
Mit mondott az öreg Chomsky?

Chomsky annyi mindent mondott már, hogy rajta kívül valószínűleg kevesen tudják követni elméletének fejlődését. Annyi azonban szinte bizonyos, hogy nem következetlen figura az öreg, pár nagyon alapvető elve már korai munkásságától kimutatható. Mivel mi nyelvtechnológiával foglalkozunk, ezért most kihagyjuk a szép szintaktikai fákat, alfát nem mozgatjuk, arra keressük a választ, miért idegenkedik annyira a valószínűségektől.
Kezdjük egy egyszerű kérdéssel: mi is egy nyelvelmélet?
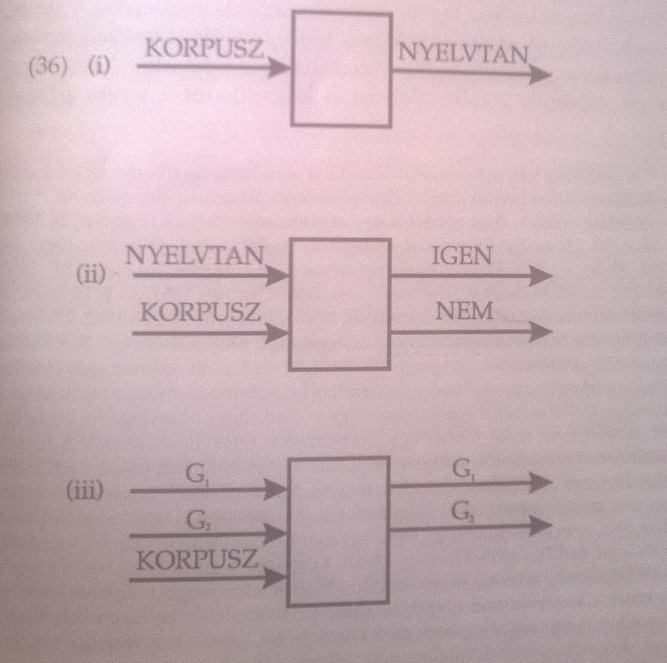
Az első, manapság egyre népszerűbb elképzelés szerint egy adott korpusz alapján kell megállapítani az adatokat generáló szabályokat (ez a fenti képen az első ábra). A másik elképzelés szerint egy nyelvelmélet célja, hogy egy szintaktikai szabályhalmazról egy korpusz segítségével ítéletet alkosson. Azonban Chomsky szerint ezen elképzelések túl ambiciózusak! Egy nyelvelmélet maximum arra jó, hogy egy korpusz segítségével eldöntse hogy két (vagy több) grammatika közül melyik bír nagyobb magyarázó erővel.
A grammatikák esetében a magyarázó erőt azonosíthatjuk azzal az egyszerű elvvel, hogy a helyes és helytelen mondatok közötti különbséget észleljük. A Mondattani szerkezetekben ezt így összegzi:
Tulajdonképpen mi alapján fogunk hozzá a nyelvtanilag helyes és helytelen sorozatok különválasztásához? [...] Először is, nyilvánvaló, hogy a nyelvtanilag helyes mondatok halmaza nem azonosítható a megnyilatkozások egyetlen, a nyelvész által terepmunka során megszerzett korpuszával sem. Egy nyelv valamennyi nyelvtana a megfigyelt megnyilatkozások véges, és bizonyos fokig esetleges korpuszának tulajdonságait vetíti rá a nyelvtanilag helyes megnyilatkozások (feltehetően végtelen) halmazára. E tekintetben a nyelvtan a beszélő eljárását tükrözi, a beszélőét, aki a nyelvvel kapcsolatos véges és esetleges tapasztalata alapján végtelen számú új mondatot képes létrehozni és megérteni.
Itt megjelenik az ún poverty of the stimulus, azaz az elégtelen mennyiségű inger érvelés. Minden embernek egy potenciálisan végtelen nyelvet kell véges időn belül elsajátítania és nagyon úgy tűnik, hogy negatív példák nélkül (magyarán nem szólunk a gyereknek hogy "figyelj, most mondok neked pár példát agrammatikus mondatokra"). Ezt szokás még Gold elméletével kiegészíteni, mely szerint a formális nyelvek nem tanulhatók meg negatív példa nélkül. Korpusznak itt nevezzünk egy egyszerű karaktersorozatot. Tanulónk egy gép, aminek ki kell találni hogy a szabályok egy halmazából melyek generálták a karaktersorozatot. Gold bebizonyította, hogy negatív példák bemutatása nélkül ez a feladat megoldhatatlan. (Johnson Gold's Theorem and Cognitive Science tanulmányát ajánlom az érdeklődő olvasóknak a témában!)
Ebből a szempontból lényegtelen, hogy az egyes szabályok kategorikusak, vagy rendelünk hozzájuk valamilyen valószínűségi értéket! A lényeg az, hogy valahogy eleve adottnak kell lenniük a szabályoknak, méghozzá úgy, hogy nagyon hamar megtalálja egy gyermek az anyanyelvét generáló grammatikát. Gondoljunk bele, a nyelvelsajátítás ún. kritikus periódusa alatt 2-5 éves kor között kell megtalálni a korpuszhoz tartozó grammatikát! Chomsky ezért Occam borotváját használva a lehető legegyszerűbb elmélet mellett dönt, a nyelvelsajátítás képessége innát (velünk született) kell hogy legyen. Ezzel párhuzamosan érvel a valószínűségek ellen is. Korlátozott, gyakran ellentmondásos adatokból kellene következtetnünk egy általános rendszerre, ez felveti az indukció problémáját. Az adatok ellentmondásossága felveti annak problémáját is, hogy egy inkonzisztens halmazból bármi következhet, azaz ha egy korpuszban (igaz különböző frekvenciával) de találhatunk adatokat grammatikus és agrammatikus szerkezetekre is, akkor nagyon sokat kellene számolnunk a nyelvtanulás során.
A modern nyelvészet legnagyobbjához illő huszáros vágással intézi el Chomsky a fenti kérdést. A korpusz a nyelvhasználat, azaz a performancia lenyomata. E mögött ott van a kompetencia, azaz "helyes és helytelen sorozatokat" elválasztó grammatika, ami kategorikus és nem hibázik. A performancia tökéletlenségét a zavaró külső tényezők (pl. hogy elfáradunk, megoszlik figyelmünk, véges az elménk, stb.) okozzák. A nyelvelméletek számár a kompetencia az igazi terep, ott a valószínűségeknek nincs helye.
Jungle Theory Never Dies!
Nézzük meg Bog és tsai Probabilistic Linguistic-je (a valószínűség nyelvészeti alkalmazásának első hullámában megjelent tanulmánykötet) hogyan érvel a hagyományos nyelvészet ellen.
1) A variancia a nyelv minden szintjén jelen van
2) A nyelvi jelenségek frekvenciája (eloszlása) hatással van a nyelvre
3) Elmosódott határok a nyelvi kategóriák, a jólformáltság stb. területén
4) A nyelvek elsajátíthatósága
Mielőtt elveszítenénk nem nyelvész olvasóinkat, inkább egy példával élnénk a az 1)-3) pontokra. Hallgassunk egy kis zenét!
Vessünk egy pillantást a dal szövegére is! Amennyiben az olvasó ismeri a patois nyelvet, akkor gondoljon egy magyar népdalra inkább! Amennyiben nem ismeri, de tud angolul, akkor már talán érti hogy a nyelv nem egy egyszerű dolog. A szöveg nagyon angolos, kb. középszintű nyelvtudással is érhető. Ellenben nem kapna ötöst az, aki angol órán így beszélne vagy írna. A jamaikai patois nem ragadható meg egyszerűen, mert az ún. post-kreol kontinuum állapotában van, ami nagyon tudománytalanul azt jelenti, hogy egyes verziói nem érthetőek az angol beszélő számára, még a másik véglet szinte az English Grammar in Use szabályai szerint formált mondatokból áll. Persze ez egy kontinuum, azaz nincs egy patois A, ami nagyon nem angol, és egy patois Z, ami meg a tökéletes oxfordi angol lenne. Sőt, egy adott beszélő is váltogatja a kontinuumon belül a pozícióját. Azaz varianciával van tele a nyelv, a kiejtéstől kezdve a szintaxisig. Ezt a varianciát erősen befolyásolja a nyelvi jelenségek frekvenciája - pl. otthon inkább patois A, iskolában, hivatalban patois Z, barátokkal, kollégákkal valahol a kettő között beszélget valaki. A szülőhelyükről elkerülő tájszólásban beszélők általános élménye, hogy otthon, hazai közegben vissza szoktak állni a tájszólásra, de amúgy nagyon hamar asszociálódnak. Ennek csak részben oka a megbélyegzés, prózaibb ok az, hogy a standard változattal magasabb gyakorisággal találkoznak, ez pedig hatással van rájuk. A jólformáltság, azaz hogy mit fogadunk el grammatikusnak is hasonlóan viselkedik! A 'eztet jól megcsináltad' valószínűleg kiakasztana egy tanítónénit, ellenben én nagyon gyakran találkozom vele.
A 4) esetében már egy kicsit el kell merülnünk a korábban említett Gold-tételben. Láttuk, hogy ennek értelmében negatív példa nélkül nem tanulható meg egy nyelv. Ha az eredeti kritériumot egy kicsit enyhítjük s csak azt kérjük elméleti tanulónktól, hogy egy adott korpuszhoz tartozó grammatikákból zárja ki azokat, melyek tutira nem működnek, akkor viszont azt láthatjuk, bizony negatív evidencia nélkül is megtanulhatók a probabilisztikus grammatikák, mert ahogy Manning tömören összefoglalja (a Probabilistic Linguistics-ben):
- egy probabilisztikus grammatika velejárója, hogy minden mondatnak van egy valószínűségi értéke, ha korpuszunkat egy ilyen grammatika generálta, akkor a mondatok frekvenciájában ez tükröződni fog
- ez a valószínűségi eloszlás tkp. tekinthető negatív evidenciának is, minél kisebb a frekvencia, annál kisebb valószínűséget kell tulajdonítani az őt generáló szabálynak
Mielőtt örülnénk! A fentiek feltételezik, hogy a tanuló egy stacionárous ergodikus forrásból származó korpusszal találkozik! Maga Manning is megjegyzi azonban, hogy a nyelv nem ilyen. Evvel Chomsky is tisztában van, hiszen a Mondattani szerkezetekben hivatkozik Shannon-ra (aki szintén kimondja, a nyelv nem stacionárius ergodikus forrás). A kedves olvasó ne adja fel, ezeket a nagy szavakat következő posztunkban a helyére fogjuk tenni mindegyiket!
Így vagy úgy, de generatívvá kell válnunk
Anderson víziója szerint az adatok majd mindent megoldanak. Nem véletlenül hivatkozik cikkében a Google-re, hiszen a keresőóriás kutatási igazgatója és két senior kutatója írta a big data programadó tanulmányát The Unreasonable Effectiveness of Data (sokak számára csak UED) címmel, ami máig a legolvasottabb írás a témában. A paper tkp. eseteket sorakoztat fel melyekben viszonylag "buta" statisztikai eljárások nagy adatmennyiségre ráeresztve jobban teljesítenek a szofisztikált modelleknél.
Peter Norvig, a tanulmány egyik szerzője és a Google kutatási igazgatója, Chomsky kritizálásában is élen jár! Sajnos On Chomsky and the Two Cultures of Statistical Modeling című esszéje nem lett annyira sikeres, mint a UED, pedig érdemes lenne követni gondolatait.
Norvig egyrészt egyet tud érteni Chomskyval abban, hogy minden elmélet lényege egy jelenség magyarázó erővel történő leírása, ami megnyitja az utat a predikció felé. A statisztikai megközelítésben két iskolát különíthetünk el, az egyik tkp. leírja a vizsgált adathalmazt, még a másik megpróbálja modellezni és általánosítani azt. Norvig szerint Chomskynak az első iskolával van baja igazából, amit el is fogad. De mi ezzel a gond?
Vizsgáljuk meg a kNN algoritmust egy kicsit! A kNN tkp. "megeszi" az összes tréningadatot, szépen elraktározza azt úgy ahogy van. Az eljárás ún. "lazy learning" mert semmilyen absztrakció nem történik benne, minden példát összevetünk a tréningadatokkal, hogy megnézzük a vektortérben melyekhez van a legközelebb - és ennyi. Maga az eljárás sokszor nagyon hatékony, de erőforrás-igényes nagy adathalmazokon futtatni és nem túl flexibilis. A gépi tanulás lényege, hogy a tréningadatokból vagy az adatokra alapozva egy hatékony és flexibilis modellt alkossunk, ami képes predikcióra, ezért a legtöbb esetben az adatok mögött meghúzódó disztribúcióra vonatkozó feltételezésekkel kell élnünk. Így a modell egy elmélet arra vonatkozólag, hogy miképp jöhetett létre adathalmazunk, azaz egy generatív elmélet.
Győzött a statisztika?
Az algoritmikus modellezés tehát nagyon hasonlít Chomsky grammatikákkal kapcsolatos elképzelésére, habár ezt Norvig ügyesen elhallgatja írásában. Ellenben megjelenik egy nagyon hatásosnak tűnő érv, mely szerint a nyelvtechnológiában és úgy általában az informatika és a telekommunikáció területén nagyon hasznos dolog az információelmélet (ami az algoritmikus modellezés szinonimája néhol az esszében), ellenben szegény Chomsky és társai alacsony bérért tengetik életüket az egyetemek elzárt világában. Válasszuk ketté ezt az érvet. Először vizsgáljuk meg, hogy a gyakorlati használhatóság tényleg érv-e egy elmélet nagyobb magyarázó ereje és érvényessége mellett, majd nézzük meg, hogy volt-e hatása a generatív grammatikának máshol is.
Az első kérdésre nagyon egyszerű válaszolni. A gyakorlati alkalmazás nem jelentheti egy elmélet felsőbbrendűségét. Gondoljunk csak bele, a newtoni fizika ma is nagyon jól használható mérnökök számára, lehet vele épületeket tervezni, lövedékek röppályáját kiszámítani stb. A közoktatásban is általában a klasszikus newtoni fizikával ismerkedünk meg és a relativitáselmélet meg a kvantumfizika csak érintőlegesen szerepel a tantervekben. Ez azt jelenti, hogy mivel nagyobb üzlet a klasszikus fizika (gondoljunk bele, az ipari forradalom óta használja az ipar, azóta rengeteg értéket teremtettek már vele) ezért jobb mint a kvantummechanika?
A generatív grammatika hatását megkérdőjelezni manapság hülyeség. Az elmúlt hatvan évben alig akadt olyan produktuma a kognitív tudományoknak, mely ne foglalt volna állást Chomsky-t illetően. Őt egyszerűen szeretni vagy gyűlölni kell ezen szakmákban. A nyelvtechnológia és a mesterséges intelligencia sem kivétel a szabály alól, ezért nyugodtan elmondhatjuk, megtermékenyítően hatottak a generatív iskola gondolatai az alkalmazott kutatásokra is, még az ipar is szeret leállni veszekedni velük.
Az elméletek tökéletlenek - s ez így van rendjén
Korábban már írtunk arról, hogy az elméletek empirikusan aluldetermináltak, itt csak röviden szemléltetjük mit is jelent ez a gyakorlatban. Ha adott a megfigyeléseinket rögzítő adatok halmaza, akkor szeretnénk abból egy elméletet alkotni, ami lehetővé teszi, hogy predikciókat is tehessünk. Hiszen tök jó tudni pl. hogy eddig minden villámlást követett mennydörgés, de következik-e ebből az hogy, a következő viharban is lesznek villámok és dörögni fog az ég? Ez ismét az indukció problémája! Ahhoz, hogy túllépjünk adatainkon, fel kell vennünk olyan állításokat elméletünkbe, mely lehetővé teszi a még nem megfigyelt adatokra való állítások megtételét! Ezt tette Chomsky is és ezt teszi minden valószínűségi modellezéssel foglalkozó kutató. Jó okuk van erre, de be kell látni, hogy empirikusan sohasem igazolható minden elméleti előfeltevés, minden esetben ott a hiba lehetősége! Popper szerint azonban a tudomány lényege pontosan az, hogy artikulálni kell miképp bukhat el elméletünk, meg kell adni falszifikációs feltételeit. A tudomány lényege nem a megcáfolhatatlanság, hanem a nyíltság, a kritizálhatóság. Ennek rész, hogy egy elmélettel kapcsolatban felszínre kell hozni előfeltevéseit. Szerintünk Chomsky sokkal tisztességesebben jár el ezen a téren, mint Norvig. A Google kutatója ui. elfelejt két fontos dolgot:
- maga Shannon is csak egy eszköznek tartotta az információelméletet a nyelv modellezésére, mivel szerinte a nyelv nem egy stacionárius ergodikus forrás
- az algoritmikus modellezés nem lehet szigorúan empirista, mivel természete szerint egy absztrakt modell létrehozását célozva induktív lépést kell hogy tartalmazzon, ami pedig empirikusan aluldeterminált
A Probabilistic Linguistics érvei nagyon meggyőzőek, de Norvig esszéjének kritikája alapján be kell látnunk, a szigorú empirizmus nem lehetséges. A nyelvi modellek ebből kifolyólag nem rendezhetőek sorba értékességük szerint. El kell fogadnunk, hogy a nyelvvel kapcsolatos gondolkodás területén nincs uralkodó paradigma. Ennek inkább örüljünk, hiszen nagyon unalmassá válna a világ, ha csak egy kereten belül gondolkodhatnánk!




