Egy kedves olvasónk klaviatúrát ragadott és nekünk szegezte a kérdést: "OK, a big data azt jelenti hogy tudunk adatokat gyűjteni és tárolni, mégpedig sokat, ezért big. De milyen adatok ezek? Minek tároljuk azt a sok adatot?" Felvesszük az elénk vetett kesztyűt és megpróbálunk válaszolni ebben a posztban!

Először szűkítsük egy kicsit a big data körét. Az utóbbi hetekben csak az nem hallott a Higgs-bozon megtalálásáról, aki elzárja magát a hírektől és embertársaitól. A CERN részecskegyorsítójában rengeteg adat keletkezik egy-egy mérés során, évente úgy 80 petabájt azaz 83886080 gigabájt, vagy 85899345920 megabájt. Ezt elemezve, leredukálva és különféle csodás módszereket alkalmazva leltek az isteni részecske nyomára a kutatók.
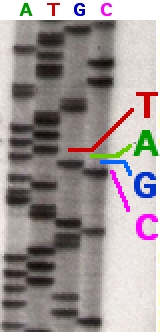
A Human Genom Project 1990 és 2003 között nagy erőfeszítések árán térképezte fel az emberi genomot. Ma már jóval olcsóbban, szinte nagyüzemben végzik a DNS-szekvenálást céges és állami kutatóhelyek. Ennek eredménye irdatlan nagy mennyiségű adat, mely jelentős része tkp. szöveges adat (az adenin, guanin, citozin és a timin nukleotid bázisok sorrendjének felsorolása). Ma már egyre több cég használ felhőalapú big data megoldásokat ezen a területen is.
Az alapvetően elméleti és alkalmazott tudományos problémákon túl azonban a big data sokkal inkább szól a hétköznapokról, rólunk, emberekről. Még 2009-ben jelent meg a Nature hasábjain a többek között David Lazer és Barabási Albert-László által jegyzett Computational Social Science című tanulmány, mely felhívja a figyelmet arra, hogy a kormányzati hivataloknál, internetes és telekommunikációs cégeknél hatalmas adatmennyiség gyűlt össze, mely a társadalomtudományok számára valóságos aranybánya lenne. Vásárlási, költözési, munkábajárási és egyéb szokásainkról szinte korlátlanul gyűjtenek adatokat a különféle szervezetek, ezek összessége pedig betekintést nyújt az emberi viselkedés egyedi és társadalmi szintjeibe is.
Drew Conway a big data "mozgalom" egyik központi figurája jegyezte meg, hogy a rendelkezésre álló adatokkal tkp. társadalomtudományi vizsgálatokat végeznek a legtöbben. A vásárlói viselkedés megértése, Facebook és Twitter kapcsolataink elemzése, vagy az amerikai elnökválasztás során alkalmazott új módszerek mind-mind klasszikus szociológiai, pszichológiai és közgazdasági kérdéseket válaszolnak meg.
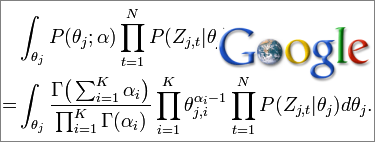
A nyelvtechnológiában a kilencvenes évektől egyre inkább előtérbe kerültek a statisztikai módszerek, melyekben a nyelvi adatok jelentős szerepet játszanak. A híres The Unreasonable Effectiveness of Data című tanulmány hívta fel a figyelmet arra, hogy a viszonylag egyszerűbb algoritmusok meglepően jó eredményeket produkálnak, ha kellően nagy mennyiségű adat áll rendelkezésükre. Így külön piac nyílt, egyre több cég gyűjt össze kellően nagy mennyiségű nyelvi adatot a webről és épít rá nyelvi modelleket, melyeket aztán értékesíteni lehet. Ilyen pl. a Wordnik vagy a múlt heti posztunkban bemutatott cégek.
A big data a legtöbb cég számára egy lehetőség, hogy jobban megértse az emberi tényezőket, nem csak az ügyfeleket, hanem saját maga működését is.