


Kása Károly fejlesztési vezetőnk Big Data Meetupon tartott Hadoop based ETL and Solr based semantic search behind Jobmonitor.hu című előadásának prezentációja megtekinthető alább, ill. elérhető a slideshare-en.
Big Data - Keresés - Számítógépes nyelvészet - Szövegbányászat - Gépi tanulás - NLP Meetup - Precognox
Big Data Meetup prezentáció
2014.02.17. 08:00 Szerző: Címkék: meetup big data Hadoop Precognox Jobmonitor
A Kereső Világ a ![]() Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Szólj hozzá! • Kövess Facebookon • Iratkozz fel értesítőre
Egy igazán big data projekt a Precognox Labs-ben!
2014.02.14. 08:00 Szerző: Címkék: keresés analitika big data Precognox Labs
A Big Data meetupon a héten mutatta be fejlesztési vezetőnk a Jobmonitor mögött dübörgő Hadoop alapú ETL és Solr-es szemantikus kereső megoldásunkat. A technikának hála rendelkezésünkre áll egy olyan átfogó adatbázis, amely a hazánkban megjelent online álláshirdetések jelentős részét tartalmazza - a Precognox Labs a következő hónapokban megnézi mit is deríthetünk ki ezen adatokból!
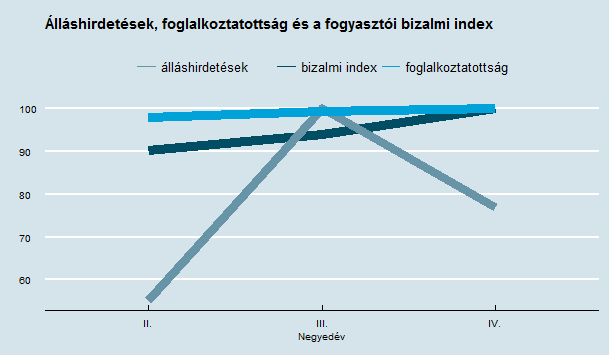
A legkézenfekvőbb kérdés, hogy az álláshirdetések száma összefügg-e a foglalkoztatottsággal, előre tudjuk-e jelezni azt a rendelkezésünkre álló adatokból? Van-e összefüggés más adatokkal, pl. a fogyasztói bizalmi index alakulásával? Hol, milyen állásokat kínálnak a munkáltatók? Mely állásokra keresnek rá a legtöbben? Ezernyi kérdésünk van még, a következő hónapokban meglátjuk tudnak-e erre válaszolni az adataink - olvasóinknak természetesen be fogunk számolni eredményeinkről!
A Kereső Világ a ![]() Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
3 komment • Kövess Facebookon • Iratkozz fel értesítőre
CommonCrawl - ha unod a kis adathalmazokat, akkor 148TB-ot elemezhetsz a segítségével
2014.02.11. 08:00 Szerző: Címkék: keresés big data CommonCrawl
A CommonCrawl Foundation célja, hogy mindenki számára nyilvánossá és elemezhetővé tegye az Internetet. Ezért rendszeres időközönként készítenek "pillanatfelvételt" keresőrobotjaik az egész netről, a legutóbbi adathalmazuk 148 terrabájt(!!) lett, ami letölthető, vagy az Amazon AWS-en rögtön elemezhető!

Az Amazon AWS-en nem csak az adat érhető el, hanem a feldolgozásához szükséges eszközök is - ami különösen a kezdők dolgát könnyíti meg. Sebastian Spiegler, a SwiftKey vezető adattudósa Statistics of the Common Crawl 2012 Corpus című jelentésében összegezte a korpusz főbb jellemzőit, melyből kiderül, hogy többé-kevésbé reprezentatív a minta.
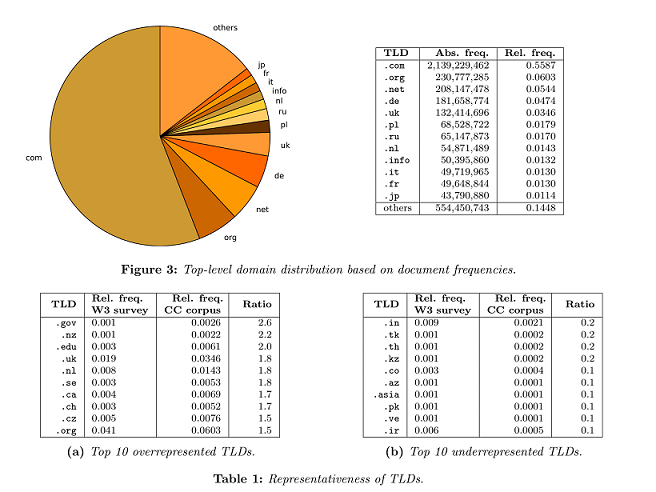
Az ún. top-level domain (azaz az internetes címek végződései, pl. .hu, .hr, .sk, stb.) tekintetében és a nyelvek esetében is kiegyensúlyozott a CommonCrawl korpusza. Érdekes, hogy az utf-8 karakterkódolás annak ellenére, hogy a legelterjedtebb, még nem szorította ki az egzotikus megoldásokat.
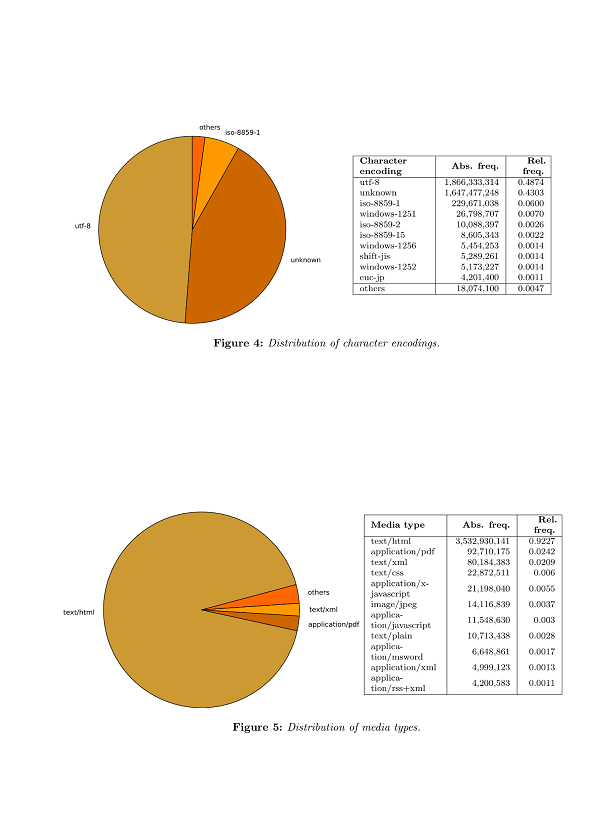
Az internetes tartalmak döntő többsége továbbra is szöveges, érdekes módon a mintából hiányoznak a videó tartalmak, a képek arány pedig igen alacsony.
A CommonCrawl ígérete szerint (és a blekko nagylelkűségének hála) 2014-től havi rendszerességgel fogja kiadni friss korpuszait. Az adatok pedig bárki számára hozzáférhetőek - ami remek lehetőség a big data iránt érdeklődők számára, hiszen a hasonló adatbázisok a nagy cégek féltett kincsei általában. Kutatók, aktivisták, startupok és wannabe data scientist-ek ingyen juthatnak immár igazi big data-hoz - tessék élni vele!
A Kereső Világ a ![]() Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
1 komment • Kövess Facebookon • Iratkozz fel értesítőre
Hírelemző - új projekt a Precognox Labs-ben
2014.02.10. 08:00 Szerző: Címkék: tartalomelemzés Precognox Labs
Olvasóink már tudják, minket nagyon izgat miképp is lehet a hírelemzésből következtetni a közeljövő eseményeire. A Precognox Labs új projektje, a Hírelemző eddigi ad hoc vizsgálatainak tapasztalataira építve egy tartalomelemző alkalmazás elkészítését tűzte ki célul - s ez egyben Kulcsár Ádám gyakornokunk diplomamunkája is.
Célunk az, hogy könnyen áttekinthetővé tegyük a ránk zúduló híreket. A keresés, a tartalomelemzés és a korpusznyelvészet lesz segítségünkre a projekt során.
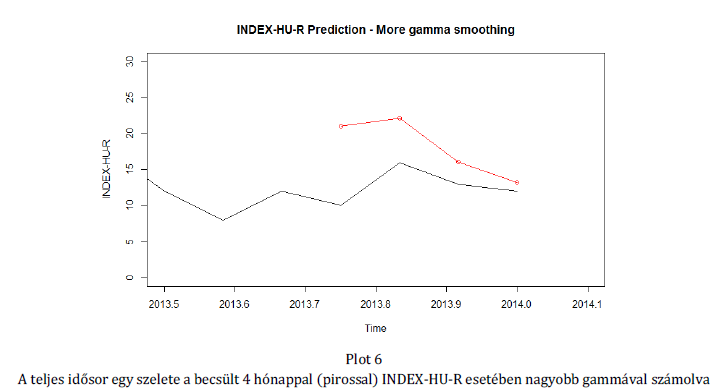
Szeretnénk túllépni a puszta tartalomelemzés keretein és - hacsak korlátozottan is - a feltárható trendek előrejelzésével, más statisztikákkal való összevetésével is foglalkozunk majd.
Az olvasók számára a projekt leglényegesebb eleme az, hogy tartalomelemzéssel foglalkozó írásainkban a bevett eszközeinket egyre inkább fel fogja váltani a Hírelemző.
A Kereső Világ a ![]() Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Szólj hozzá! • Kövess Facebookon • Iratkozz fel értesítőre
A Google mint adatkereső
2014.02.06. 08:00 Szerző: Címkék: open data Google Google Ngram Google Public Data Explorer
A Google már régóta bevezette az ún. faktuális kereséseknél (pl. időjárás, részvényárfolyam stb.) a kis infódobozokat, melyek a találatok felett helyezkednek el, ill. azoktól jobbra a Knowledge Graph-ból kinyert adatok kaptak helyet a közelmúltban. Az elmúlt hónapokban ez így elénk tárt adatok köre tovább bővült a Google Ngram lexikai és a Google Public Data Explorer nyílt adataival.
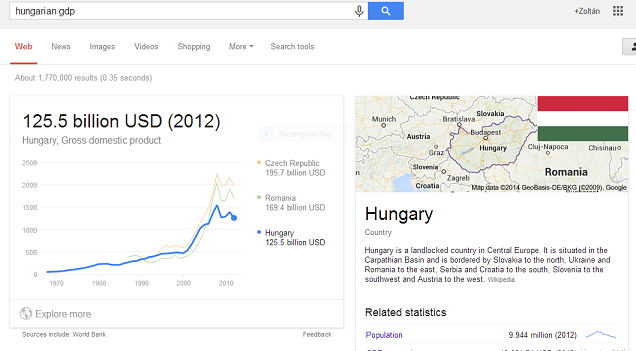
Ha pl. a magyar GDP adatokat keressük, a találatok felett megjelenik egy szép grafikon, ennek alján az "Explore more" linkkel. Az infódoboz mellett pedig ott a már megszokott Knowledge Graph-ból kinyert adat, ami szintén nagyon hasznos (ha pl. a magyar GDP helyett Tuvalura vagy egyéb egzotikus országra keresünk).
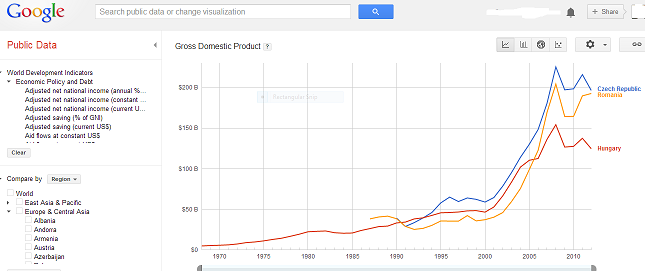
Az "Explore more" gombra kattintva a Google Public Data Explorer oldalán találjuk magunkat, ahol több kapcsolódó adatot is találhatunk és alapvető vizualizációs eszközök is a rendelkezésünkre állnak.
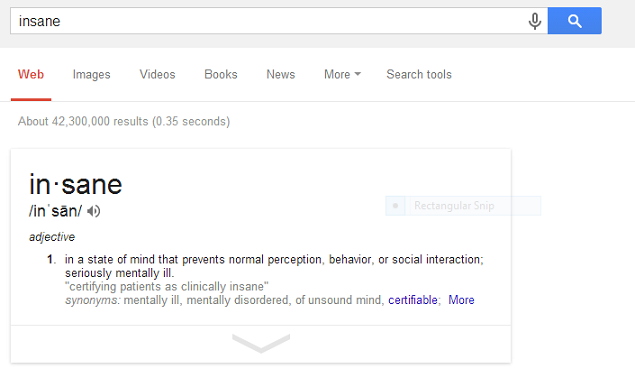
Az Ngram projekt adatai nem jelennek meg minden keresésnél, csak akkor ha a Google feltételezi, hogy a szó jelentése érdekelheti a felhasználót (valószínűleg ezt a szavak gyakorisága és a keresők kattintási statisztikái határozzák meg). Az infódobozban a szó elsődleges jelentése jelenik meg, a lefele nyílra kattintva kapunk további információkat.
A további információk között a szó eredetét találjuk és megtekinthetjük Ngram korpuszon mért gyakoriságát egy idősoron, továbbá a Google Translate segítségével lekérhetjük egyes nyelveken az adott szó megfelelőjét. (Minden rendes korpusznyelvész álma válik ezzel valóra, hiszen úgy tűnik a Google szerint ezen adatok érdeklik az embereket!)
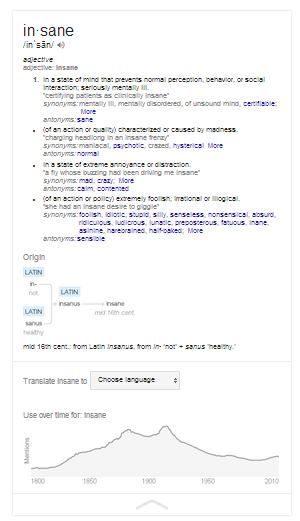
A faktuális válaszok megjelenésével egyre inkább úgy tűnik, hogy a keresők hagyományos szerepük mellé igyekeznek amolyan információfelfedező platformmá válni. Mi ennek csak örülni tudunk!
A Kereső Világ a ![]() Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.