


Gerő Dávid Péter vendégposztja, az Egyszerű magyar mondatok kezelése NLTK környezetben című szakdolgozatának témájából.
Az írásom célja, hogy kedvet és lelkesedést ébresszek a próbálkozás utáni tanulás iránt egy számítógépes nyelvfeldolgozó keretrendszer bemutatásával. Megmutatni egy eszközrendszert és az eszközrendszeren egy magyar nyelvészeti probléma megoldását, amely alkalmas arra, hogy a diákok a felsőoktatásban elsajátított vagy éppen tanult ismeretanyagokat lefordíthassák a számítógép által is értelmezhető formába.
A célhoz eszköz kell. A választás a Python programozási nyelven megvalósított Natural Language Toolkit-re (NLTK) esett. Mind a programozási nyelv, mind a számítógépes eszközrendszer könnyű elsajátíthatósága miatt.
Az előttünk álló probléma a magyar nyelvű névelő egyeztetés és a választott nyelvészeti keretek pedig a generatív nyelvtan és megszorítás alapú nyelvtan.
Miről is beszélek most egyáltalán?
Ugorjunk a példára.
ember, kutya, egy ember, egy kutya, *a ember, az ember, a kutya, *az kutya
Tehát a nyelvünk ábécéje: e, egy, a, az, ember, kutya
Az ábécé feletti halmazunk: az ábécé permutációja (az ábécé hat elemű, így ennek faktoriálisát vesszük: 6! = 720 elemű.)
Tehát a nyelvünk (L) 720 mondatból áll.
Nekünk pedig az a szerény feladatunk, hogy ebből a 720 mondatból kiválasszuk azt a hat elemet, amelyek a magyar nyelv része. - Ez utóbbit nevezzük LM-nek, amely LM teljes részhalmaza a magyar nyelvnek.
Fogalmazzuk újra a problémát!
Generatív nyelvtan alapján az feladatunk, hogy egy olyan transzformációs szabályhalmazt adjuk, amely a megadott ábécé alapján csak és kizárólag a keresett hat elemű halmazt (LM-et) generálja.
Megszorítás alapú nyelvtan szempontjából pedig az a feladatunk, hogy olyan megszorítás alapú szabalyokat adjuk, amely az L halmazból kizárólag a keresett hat elemű halmazt (LM-et) választja ki.
Most már minden tiszta. Szerencsére. Fordítsuk először képletre aztán kódra a gondolatot és vizsgáljuk meg a működését!
Generatív nyelvtannal
A G=(N, T, S, H) rendezett négyest generatív nyelvtannak (vagy generatív grammatikának) nevezzük. (Pontos definíció: www.inf.unideb.hu/~nbenedek/FormNyelvAutom/chunks/ch03s02.xhtml )
A problémánk mentén N, a nemterminális szimbólumok halmaza { S, DP, D, DhatN, DhatP, DmghP, DmghN, NmghP, NmghN }
A T a terminális szimbólumok halmaza { e, egy, a, az, ember, kutya }
A H, a helyettesítési szabályok halmaza. { S → DP, DP → D , D → DhatM, D → DhatP , DhatM → e N, DhatM → egy N , DhatP → DmghP NmghP, DhatP → DmghM NmghM , DmghP → az , DmghM → a , N → NmghP, N → NmghM ,
NmghP → ember, NmghM → kutya }
Míg az S, a kitüntetett egy elemű halmaz, a kezdőszimbólum. { S }
Néhány munkadefiníció magyarázatra szorul. A DhatM nemterminális szimbólum azokat a determinánsokat jelöli, amelyek határozottsági jegye mínusz értéket vesz fel. Míg a DhatP azon determinánsokat jelölik, amelyekt határozottsági jegye pozitív. A DmghM és DmghP a magánhangzóval kezdődő alaknak a nemterminális szimbóluma.
Abbéli csodálkozásunkban, hogy sikerült egy ilyen kis képletbe ilyen sok szimbólumot beillesztenünk... Fordítsuk gyorsan kódra a működést.
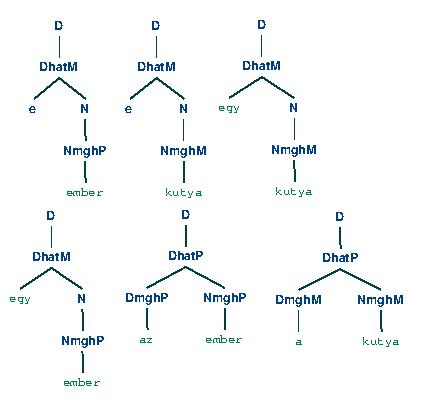
Mit érdemes észrevennünk?
A nyelvtani fájlt érdemes megfigyelnünk. A nyelvtani fájlban nem definiáltuk külön a nemterminális és termininális szimbólumok halmazát. Csupán felállítottuk a transzformációs szabályokat... és mégis működik.
Az NLTK amellett, hogy egy könnyű szintaxist biztosíts a számunkra saját nyelvtanunk definiálására meg van az a nagyszerű lehetősége, hogy a terminális és nemterminális szimbólumok halmazát automatikusan, a szabályhalmazból következteti ki.
Ezért a generatív grammatika definiciójára hivatkozva: nekünk elegentő helyettesítő szabályok halmazát felírnunk és ebből a szabályhalmazból automatikusan létrehozza számunkra a rendszer a terminális, nemterminális és a kezdőszimbólum halmazát.
Megszorítás alapú nyelvtannal
Végezetül álljon itt egy példa a keresett nyelv megszorítás alapú leírására.
Megszorítás alapú nyelvtan szempontjából az a feladatunk, hogy olyan megszorításokat adjuk, amely az L halmazból kizárólag a keresett hat elemű halmazt (LM-et) választják ki.
Összegzés
Egy egyszerű nyelvtant szerkesztettük, amely a névelők és főnevek egyeztetését hivatott modellezni magyar nyelven. Se maga a nyelvtan, se annak informatikai megvalósítása nem teljes. Sőt nyelvészeti szempontból megkérdőjelezhető is. Ennek ellenére a nyelvtanok, a különböző nyelvtani keretrendszerekben működnek és pontosan az általunk keresett helyes magyar mondatokat generálják vagy fogadják el.
A célunknak megfelelően könnyen áttekinthető példák, amelyek azt szorgalmazzák, hogy a saját nyelvtan szerkesztése és a saját nyelvtannak a számítógép által értelmezhető formában való megjelenítése és megvalósítása nem egy ördöngős informatikai feladat. Ha olyan eszközrendszer áll a rendelkezésünkre, mint a példák során felhasznált NLTK.
Jó játékot!
Gerő Dávid Péter (@davidpgero), a Szegedi Tudományegyetem magyar-nyelvtechnológus hallgatójaként végzett 2014-ben. Jelenleg szoftverfejlesztőként tevékenykedik és nem szereti a mazsolát.
