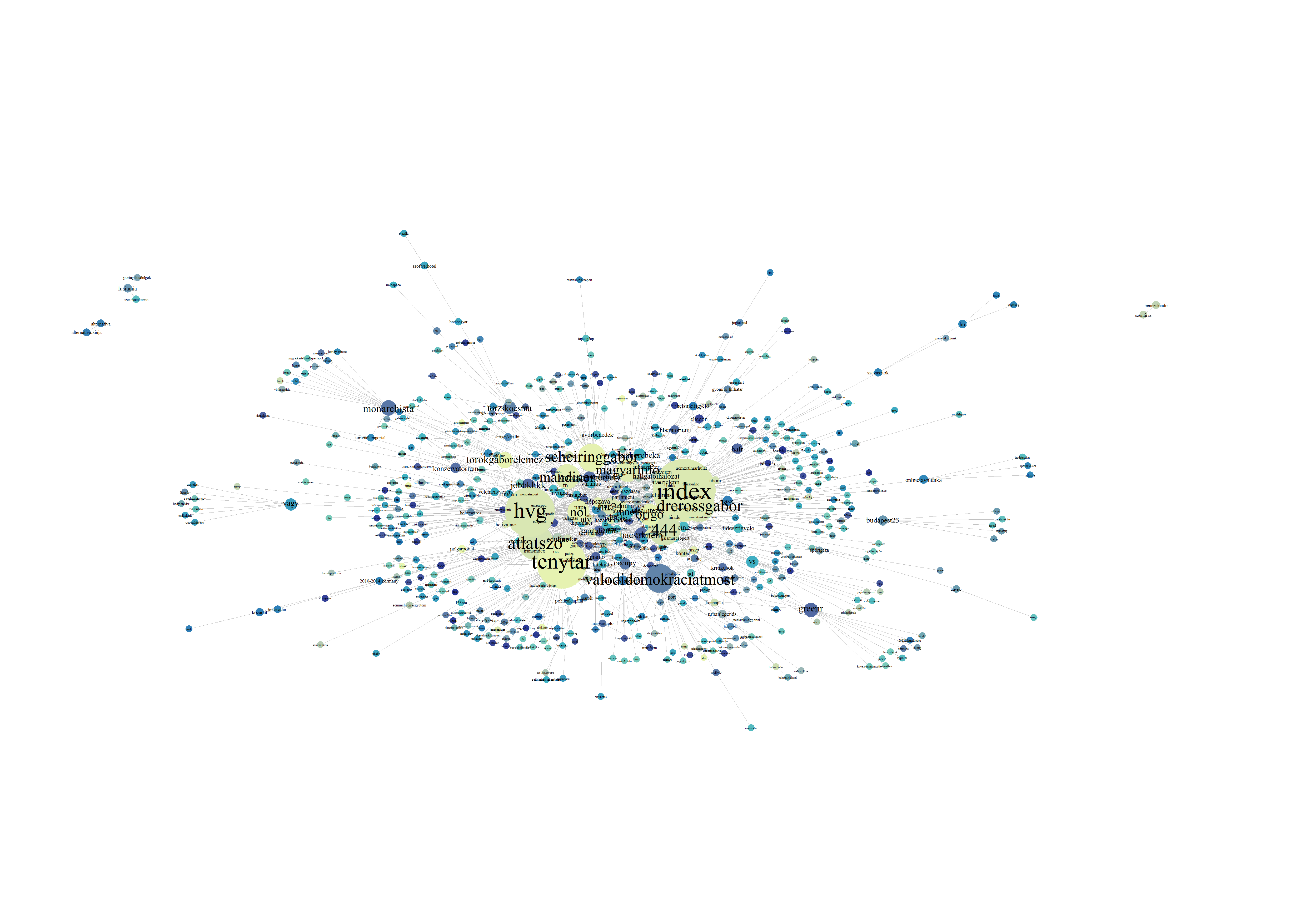
A jelen poszttal induló kutatássorozatunkhoz James W. Pennebaker The Secret Life of Pronouns című könyve adta az ötletet. A szerző angol nyelvű szövegeket vizsgál abból a szempontból, hogy vajon a funkciószavak használata milyen, eleddig rejtve maradt információkat árul el számunkra az adott nyelvhasználót illetően. Kíváncsiak voltunk, mi derül ki, ha a mindezeket a sajátságokat a magyarban is megnézzük.
Eredetileg azt szerettük volna megvizsgálni, hogy vajon találunk-e valamilyen szignifikáns összefüggést a magyar nyelvű szövegekben előforduló emóciószavak és a személyes névmások között. Pennebaker könyve azonban annyi izgalmas ötleteket adott, hogy végül úgy döntöttünk, egy egész kis kutatási projektet szentelünk a feladatnak, és mélyebben is beleássuk magunkat a témába.
Olvasóink tehát időről időre megismerkedhetnek majd a vizsgálati eredményeinkkel, s a jelen posztban - az izgalmak fokozása céljából - az ötletadó Pennebakerről lesz szó, valamint az emóciók, a személyiség, a nyelv és az agy izgalmas kapcsolatrendszerét tárgyaljuk részletesebben.
Pennebaker 2011-ben publikált könyve, a The Secret Life of Pronouns több évtizednyi kutatómunka eredménye, amelyben a szociálpszichológus szerző többek között nyelvészekkel, számítógépes és marketinges szakemberekkel, valamint jogászokkal együtt vett részt. A vizsgálati sorozat egyik elméleti alapvetése azt volt, hogy az ún. funkciószavak, amelyek közé pl. a névmások, a névelők és a segédigék tartoznak, elárulnak bizonyos részleteket az emberi személyiségről, a gondolkodási sajátságokról, az érzelmi állapotról, illetve az adott személy emberi kapcsolatairól.
 A funkciószavak az ún. tartalmas szavakkal állnak szemben. Ez utóbbiak ugyanis, ahogyan pl. a főnevek, a melléknevek, a számnevek vagy az igék, általában konvencionális alapon összeköthetőek a világ jelenségeivel - míg a funkciószavak nem. Amíg például az asztal vagy a séta hasonló képzeteket hoz létre az adott nyelv beszélőiben, addig az akkor vagy az ő jelölete rendkívül változatos lehet. A funkciószók szerepe ugyanis a tartalmas szavak közötti kapcsolatok megteremtése, illetve azok jelentéseinek árnyalása, módosítása. (A jelenségről további információt találni többek között itt.)
A funkciószavak az ún. tartalmas szavakkal állnak szemben. Ez utóbbiak ugyanis, ahogyan pl. a főnevek, a melléknevek, a számnevek vagy az igék, általában konvencionális alapon összeköthetőek a világ jelenségeivel - míg a funkciószavak nem. Amíg például az asztal vagy a séta hasonló képzeteket hoz létre az adott nyelv beszélőiben, addig az akkor vagy az ő jelölete rendkívül változatos lehet. A funkciószók szerepe ugyanis a tartalmas szavak közötti kapcsolatok megteremtése, illetve azok jelentéseinek árnyalása, módosítása. (A jelenségről további információt találni többek között itt.)
Az alábbi táblázat tartalmazza a funkciószók típusait, valamint néhány példát mindegyikre az angol és a magyar nyelvből (vö. Lengyel 2000; Szita-Görbe 2010):
| Kategória | példák az angolból | példák a magyarból |
| névmások | I, she, it | én, ő, az |
| névelők | a, an, the | a, az, egy |
| prepozíciók | up, with, in, for | - |
| névutók | - | fölé, mellett, nélkül, iránt |
| segédigék és segédszók | is, don't, have | fog, múlik, való, marad, volna |
| negáló elemek | no, not, never | ne, nem, soha |
| kötőszók | but, and, because | de, és, mert |
| kvantorok | few, some, most | néhány, sok, legtöbb |
| határozószók | very, really | kicsit, nagyon, eléggé |

Pennebaker kutatócsoportjának a 90-es években sikerült létrehoznia az ún. LIWC programot (Linguistic Inquiry and Word Count), amely majd' 80 különböző, kézzel összeállított szótár alapján volt képes nagy mennyiségű szöveg elemzésére. Az eszköz segítségével a csoport számtalan szövegtípus nyelvi sajátságait térképezte fel azután, s a munkájuk eredményeképpen létrejött legfontosabb megállapításokat 2011-ben, az említett könyvben publikálták.
A kutatás további figyelemre méltó hozadéka volt, hogy létrehoztak egy gyors személyiségelemző eszközt, amelyet bárki kipróbálhat az interneten keresztül egy szöveg bemásolása segítségével. A program természetesen angol nyelven készült, és ezen a linken érhető el.
De miért is irányítsuk figyelmünket a funkciószavakra a tartalomelemzésben? Miért ne csupán azokra a bizonyos tartalmas szavakra fókuszáljunk?
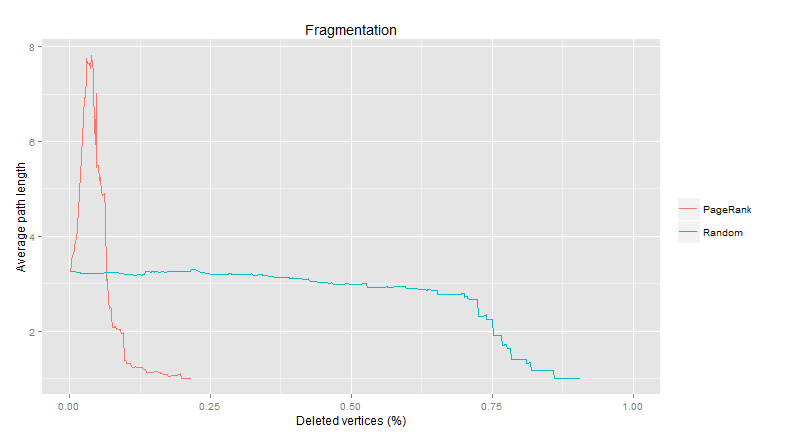
Pennebaker többek között azzal érvel, hogy hogy a 20 leggyakoribb előfordulású angol szó között kizárólag funkciószavakat találunk, s pusztán ez a húsz elem megközelítőleg a 30%-át teszi ki az angol nyelvi produktumoknak, az írott és a beszélt nyelvet illetően egyaránt.
A Magyar Nemzeti Szövegtár (MNSZ) adatai alapján megnéztük, vajon mi a helyzet a magyar nyelvben. Az angolhoz hasonló eredményre jutottunk: tartalmas szót nem is találtunk a top 20-ban.
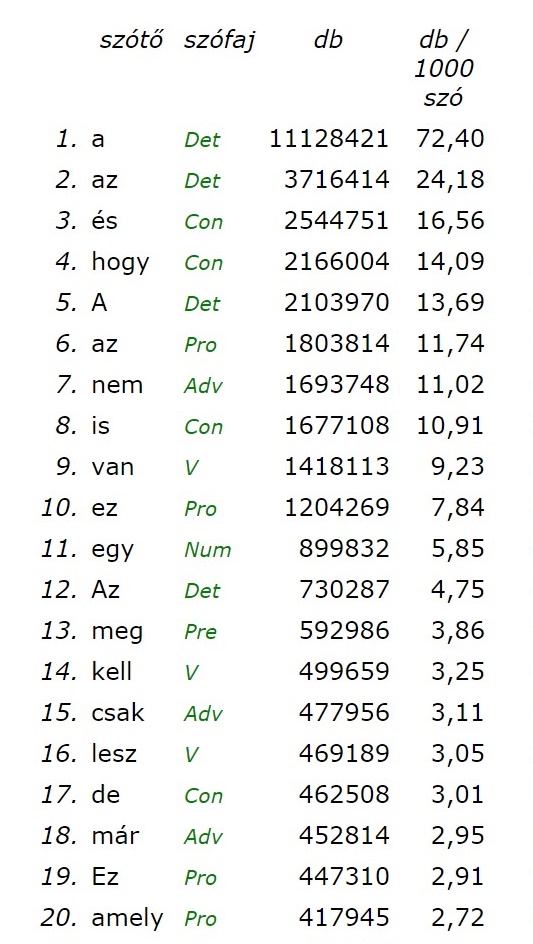
A jelenség további érdekes momentuma, hogy a nyelvhasználat során tudatosan alapvetően a tartalmas szavakra fókuszálunk, mind a produkció, mind az interpretáció folyamatában. Ez egyrészről azt jelenti, hogy amikor szövegeket alkotunk, kevésbé vagyunk megfontoltak a funkciószavak használatát illetően; inkább a közölni kívánt szemantikai tartalomra, így szükségképpen elsősorban a tartalmas szavakra koncentrálunk. Ugyanakkor a kommunikációnk során a funkciószó-használatunkkal tudattalanul is olyan információkat közlünk magunkról, mint például a nemünk, a korunk, a szociális viszonyaink vagy az aktuális érzelmi állapotunk - amelyeket esetleg egyáltalán nem is szerettünk volna a partner tudomására hozni. Az elmondottakon túl a funkciószavak "megbúvó" természete azt is eredményezi, hogy amikor szövegeket interpretálunk, a tartalmas szavakra koncentrálunk, azokra támaszkodva igyekszünk megérteni a közvetített tartalmat. A funkciószavak mégis, mintegy tudat alatt hatnak ránk. Pennebaker Abraham Lincoln 1863-as, elementáris erővel ható beszédét hozza példaként, amelynek java része tulajdonképpen 14, több alkalommal ismételt funkciószóból állt.
Azt mondja Pennebaker tehát, hogy funkciószó-használatunk az érzelmi állapotunkról is árulkodik. De hogyan lehetséges az, hogy ez a két faktor összefügg? Hol és hogyan kapcsolódhatnak össze ezek a faktorok az emberi agyban?
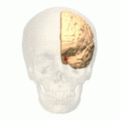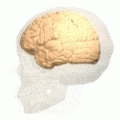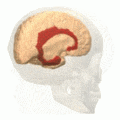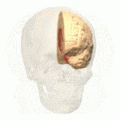
A szerző az ún. Broca- és Wernicke-afázia példáján keresztül mutat rá az összefüggés természetére. Tekintsük mi is e jelenségeket részletesebben!
Az alábbi egyszerű sematikus ábra az agyban található ún. Broca- és Wernicke-területek elhelyezkedését szemlélteti.
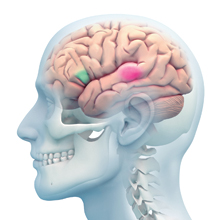
A Broca-terület, amelyet felfedezője, Paul Broca után neveztek el, a bal homloklebenyen található, míg a Carl Wernicke után elnevezett Wernicke-terület a bal fali lebenyen helyezkedik el. Mindkét tudós orvos volt, és a 19. században, beszédprodukcióval és beszédértéssel kapcsolatos defektusokon keresztül ismerték fel a tárgyalt agyi területek jelentőségét (további információért l. pl. ezt, ezt és ezt).
Broca az 1860-as években egy egész sorozat tanulmányt publikált arról, hogy a később róla elnevezett terület károsodása következtében gyakorta fájdalmasan lassú, és elemeiben össze nem függő beszéd alakul ki a betegeknél. Szigorúbban fogalmazva azt mondhatjuk, hogy a terület sérülése a funkciószavak megfelelő használatának képességét (is) veszélyezteti. Súlyos esetben akár drámaian - szinte kizárólag főnevekre -redukálódik a szókincs. Nézzünk egy rövid részletet egy Broca-afáziában szenvedő beteg beszédéből (vö. Bánréti 2006)!
Kérdező: Hogy került a kórházba?
Vizsgálati személy: Igen ... hétfőn ... öö ... apa és Piri (a beteg neve) ... és apa ... kórházba. Két ..... orvos, és ... harminc perc ... és ... igen ... és ... kórház. És ööö szerdán ekkor... kilenc órakor ... és ... harminc perc ... csütörtök ... tíz óra, orvosok. Két orvos ..... és fogak. Igen ... így'
A fenti részlet jól szemlélteti a Bánréti (2006) által említett alapvető tüneteket, úgymint a mondatrészleteket produkáló, el-elakadó, töredezett beszédet, amelyet a szótalálási nehézségek, a gyakran elhagyott funkciószavak, valamint az elhagyott toldalékok jellemeznek.
Az ún. Wernicke-terület károsodása Broca-afáziától igen eltérő nyelvi tüneteket produkál. Az ebben az agyi rendellenességben szenvedőkre jellemző a rendkívüli szóbőség, beszédük grammatikailag helyes, de tartalmatlan. Megfigyelhető, hogy a betegeknek szótalálási problémái vannak, egészen egyszerű főnevek és igék sem jutnak az eszükbe, ezért azokat gyakran más, oda nem illő, sőt kitalált szavakkal helyettesítik. A tartalmas szavakkal vannak tehát problémáik, ugyanakkor a funkciószavakat gond nélkül, megfelelő módon használják.
A következő részlet egy Wernicke-afáziás magyar betegtől származik, Herman József gyűjtéséből (vö. Pinker 1999):
Vizsgálati személy: ...eltávottam rajta így sikantiá voltunk úgyhogy nem tudtam eztet kiváltani hanem azon gondolkodtam hogy hátha lenne davivi hanem azt mondtam ippen be hogy úgy kell tenni hogy megint el tudtam fele... szóval csak aztat szerettem volna hogy így a gyerek megvan hanem szállítjuk nekik hogy mondhatját táguttuk egymást.
Kérdező: Hány éves a bácsi gyereke?
Vizsgálati személy: Hát nekem a két epretek huszon dehogy huszon hanem harm... negyven ötvenöt tül van ez az árpa...
A Broca-terület, amely tehát a funkciószavak használatának képességével szoros összefüggést mutat, a frontális agyi lebenyben található. Ez az agyi terület azonban több más képességet is irányít, és közülük számos a szociális jellegű képesség és készség. A frontális lebenyhez köthető például a különböző érzelmek kifejezési, sőt palástolási képessége, de több más, szociális kapcsolatainkban fontos szerepet játszó kompetencia is itt lokalizálódik. És ami számunkra még izgalmasabbá teszi a problémakört, az az, hogy az arckifejezések értelmezésének képessége is ehhez az agyi területhez köthető, korábbi posztunkban pedig épp arra igyekeztünk rávilágítani, hogy milyen párhuzamok találhatóak az arcon megjelenő és a szövegszintű emóciókifejezések kontextusbeli megértése között!
A frontális lebenynek a szociális képességekben való kimagasló szerepét mutatja Phineas P. Gage (1823-1860) híressé vált, tragikus esete. A férfi mérnökként az új-angliai vasúttársaságnál a pályamunkások csoportvezetője volt, azonban egy 1848-ban bekövetkezett balesetben egy hosszú vasrúd fúródott a fejébe, amely az agyának a bal frontális lebenyét nagy mértékben elpusztította.
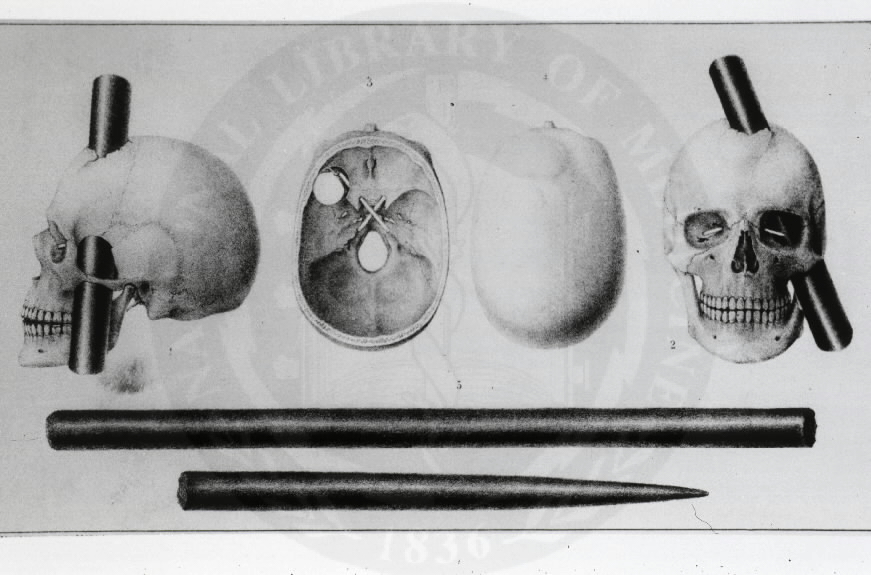
A család, és a többi, róla gondoskodó legnagyobb meglepetésére azonban Gage még a tragédia évében felépült. Ugyanakkor, a baleset teljesen átformálta a férfi személyiségét és viselkedését. A korábban figyelmes, kedves, pontos és precíz műszakvezető a tragédia következtében fegyelmezetlen, trágár, figyelmetlen, agresszív, sőt perverz emberré vált, ahogyan arról az esetet publikáló amerikai orvos, John Martyn Harlow beszámolt. Gage barátai egyenesen úgy találták, hogy a férfi “többé már nem Gage”. Harlow így ír megfigyeléseiről:
His contractors, who regarded him as the most efficient and capable foreman in their employ previous to his injury, considered the change in his mind so marked that they could not give him his place again. He is fitful, irreverent, indulging at times in the grossest profanity (which was not previously his custom), manifesting but little deference for his fellows, impatient of restraint of advice when it conflicts with his desires, at times pertinaciously obstinent, yet capricious and vacillating, devising many plans of future operation, which are no sooner arranged than they are abandoned in turn for others appearing more feasible. In this regard, his mind was radically changed, so decidedly that his friends and acquaintances said he was "no longer Gage".

Pennebaker amellett érvel, hogy amennyiben a személyiség és a szociális viselkedés szorosan kapcsolódik a frontális lebenyhez, nem meglepő, ha azt tételezzük, hogy magának a frontális lebenyben levő nyelvi központnak, a Broca-területnek is kapcsolata kell, hogy legyen a személyiséggel és a szociális viselkedéssel. Pennebaker rámutat, hogy a funkciószavak megfelelő használatához - amelyért tehát a Borca-terület felel - szociális képességek, illetve készségek szükségesek. Ahhoz például, hogy névmásokat megfelelően használhassunk, tisztában kell lennünk azzal, hogy a kommunikációs partnerünk képes megtalálni azok referensét a szövegben vagy a szövegen kívüli világban; így az alábbi mondat esetében:
Nem tudom, hova tehette, de hozd akkor azt a másikat onnan.
Bár a példában alig találni tartalmas szót, az ilyen és ehhez hasonló megnyilatkozásokat gond nélkül produkáljuk és interpretáljuk mindennapi kommunikációnkban - feltéve persze, ha egészséges Broca-területtel rendelkezünk.
A tárgyalt összefüggéseket támasztják alá azok a jelenségek is, miszerint bizonyos funkciószavak használati sajátságai eltérnek a férfiak és a nők, továbbá különböző korosztályok között (pl. a férfiak több névelőt, míg a nők több egyes szám első személyű személyes névmást használnak). Mindemellett a lelkiállapot is jelentősen befolyásolja a funkciószavak használatát. A Kasseli Egyetem kutatói által, Dr. Johannes Zimmerman vezetésével végzett kutatás eredményei szerint például azok az emberek, akik gyakrabban használják az egyes szám első személyű - vagyis a saját magára utaló - személyes névmásokat (én, magam, engem stb.), nagyobb valószínűséggel hajlamosabbak a depresszióra vagy szenvednek depresszióban, továbbá több nehézségük van interperszonális kapcsolataikban is, mint azoknak, akik megnyilatkozásaikban a többes szám első személyű (mi, magunkat stb.) személyes névmásokat részesítik előnyben (a kutatásról részletesebben l. itt).

Az e poszttal indított kutatássorozatunk célja, hogy feltérképezzük, milyen kapcsolatok mutatkoznak a funkciószó- használat és az ember érzelmi állapota, szociális státusza, kora, neme és egyéb esetleges tulajdonságai között. Első eredményeinkről rövidesen beszámolunk.

IRODALOM és FORRÁSOK
Bánréti Zoltán 2006. Neurolingvisztika. In Kiefer-Siptár (szerk): Magyar nyelv. Budapest, Akadémiai kiadó – Kluwer. 653-725.
Hoffmann Ildikó 2007. Nyelv, beszéd és demencia. Philosophiae Doctores 56. Budapest, Akadémia Kiadó.
Hoffmann Ildikó-Németh Dezső 2006. Neurolingvisztikai tanulmányok. Szeged, JGYTF Kiadó.
Lengyel Klára 2000. A segédigék és származékaik. In Keszler Borbála (szerk.): Magyar grammatika. Budapest, Nemzeti Tankönyvkiadó. 252-258.
Pennebaker, James W. 2011. The Secret Life of Pronouns: What Our Words Say About Us. New York, Bloomsbury Publishing.
Pinker, S. 1999. A nyelvi ösztön. Budapest, Typotex.
Szita Szilvia-Görbe Tamás 2010. Gyakorló magyar nyelvtan – A Practical Hungarian Grammar. Budapest, Akadémiai Kiadó.
Magyar Nemzeti Szövegtár (MNSZ) [http://corpus.nytud.hu/mnsz/]
[http://www.theguardian.com/science/blog/2010/nov/05/phineas-gage-head-personality]
[http://www.nyest.hu/hirek/nyelvtani-szofajok-az-mti-nel]
[http://index.hu/tudomany/gesch/]
[http://analyzewords.com/]
[http://www.nytud.hu/oszt/neuro/banreti/publ/banretikezi.pdf]
[http://nemettolmacs.blogspot.hu/2008/05/broca-s-wernicke-afzirl.html]
[http://life.ma/eletmod/betegsegek/8845-depresszios-lehet-aki-sokat-beszel-magarol/]