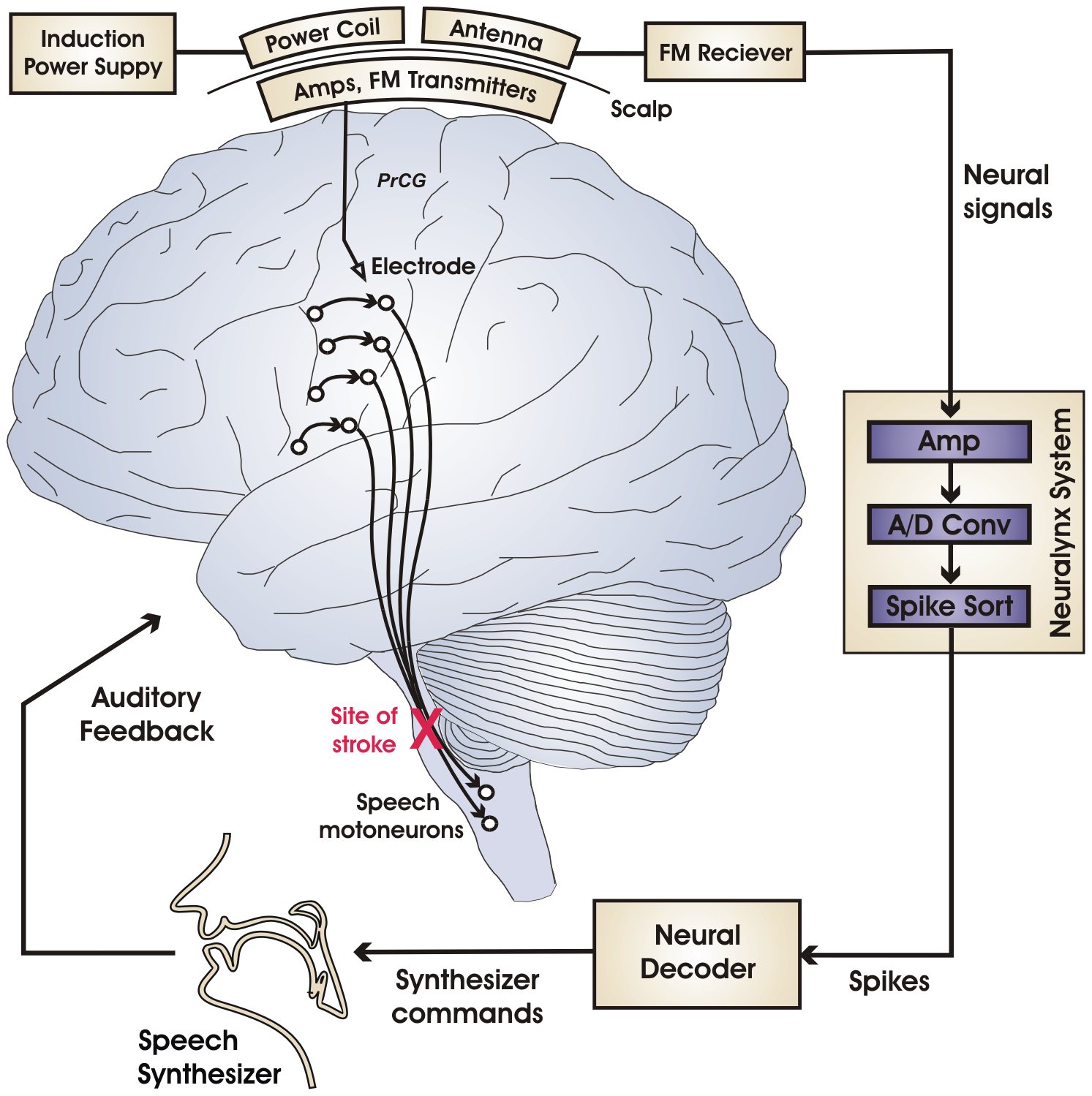
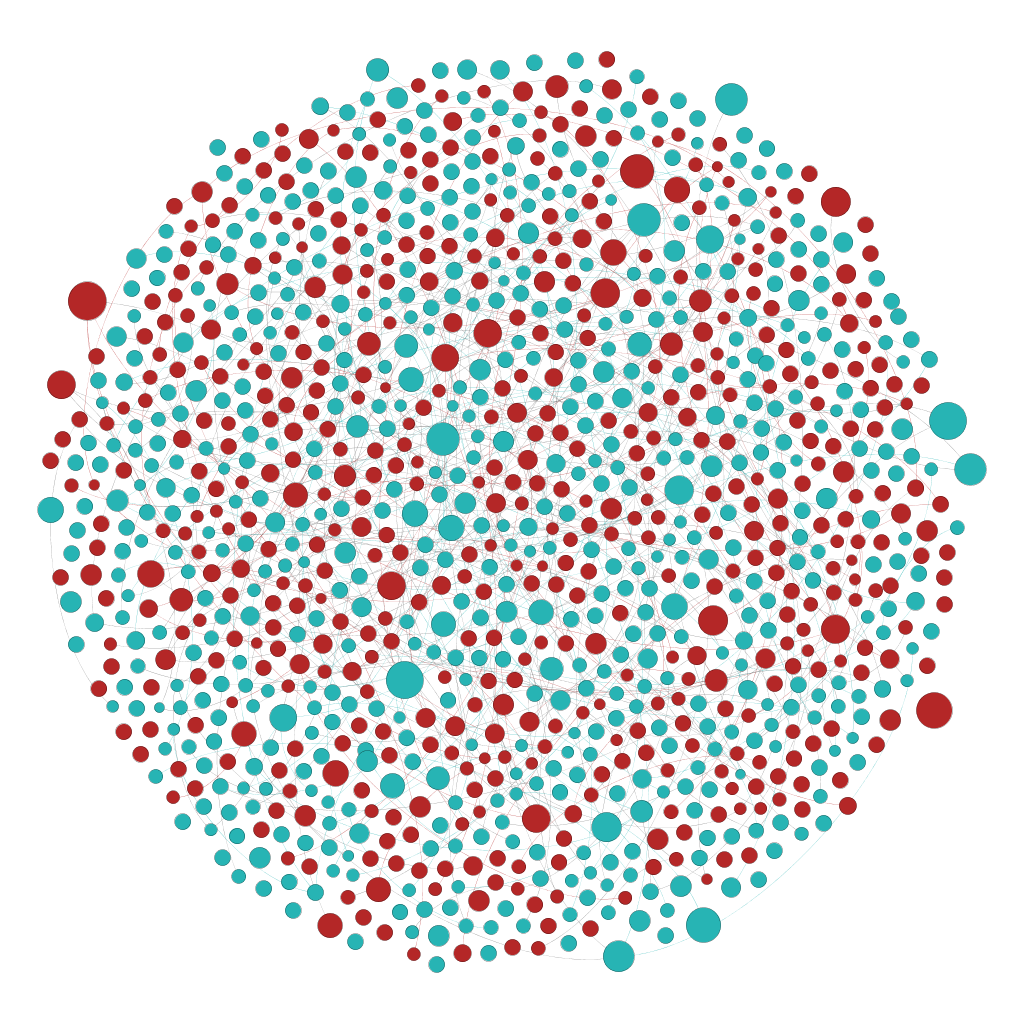
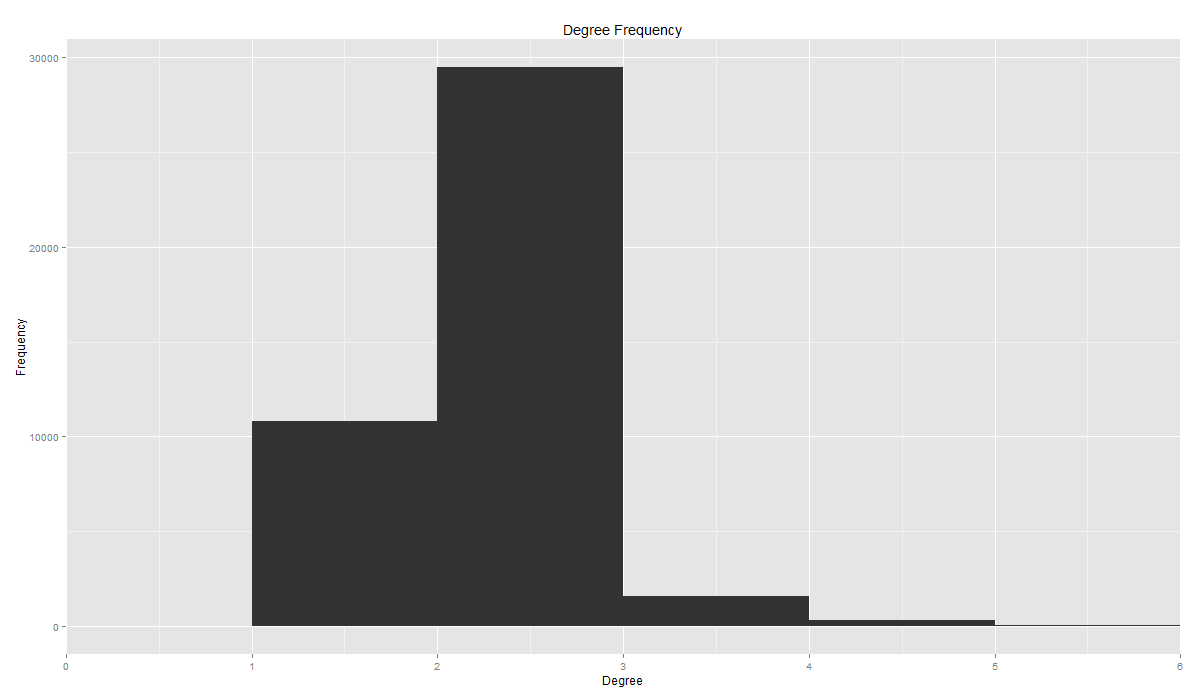
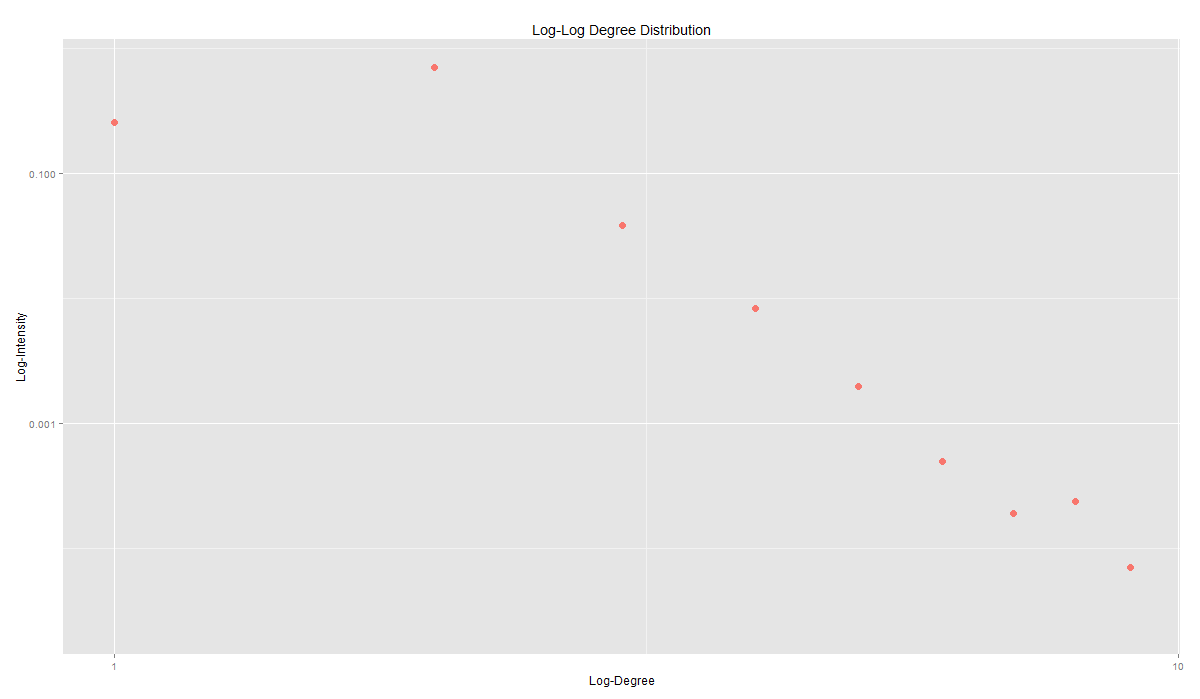
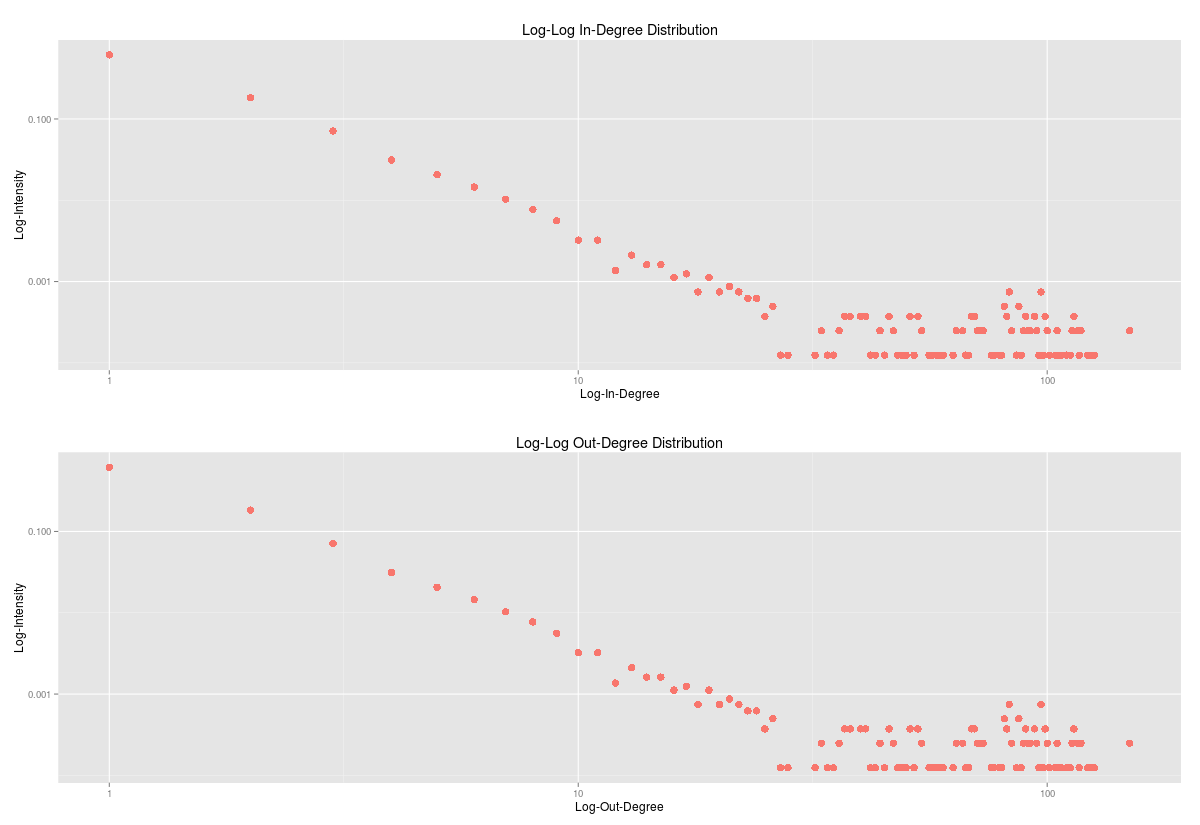
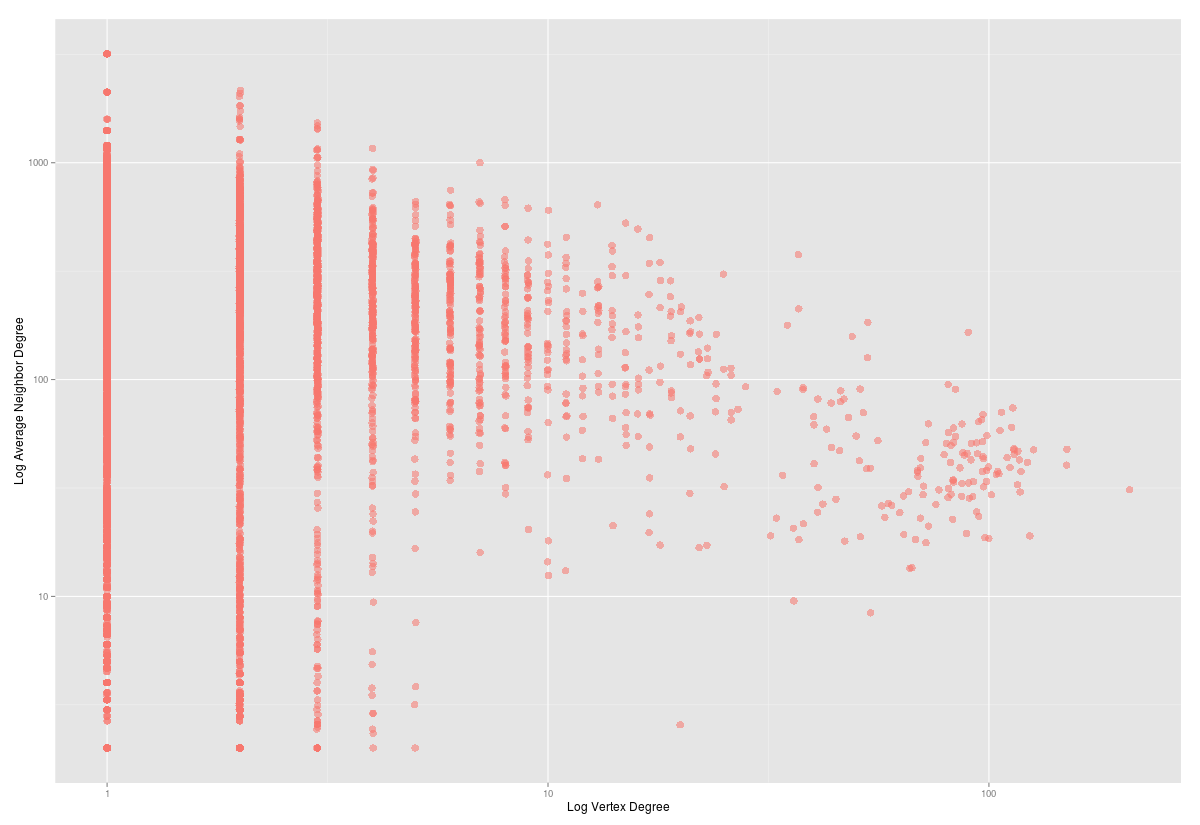
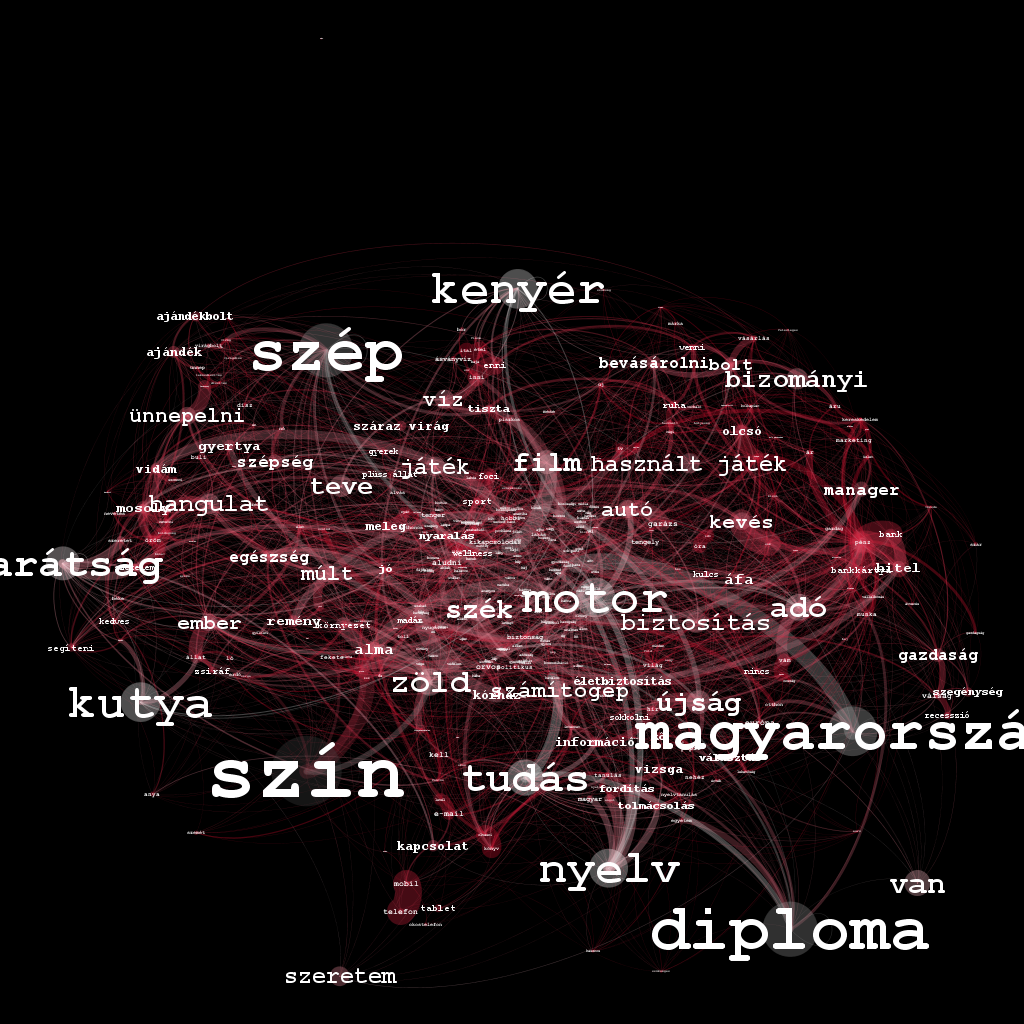
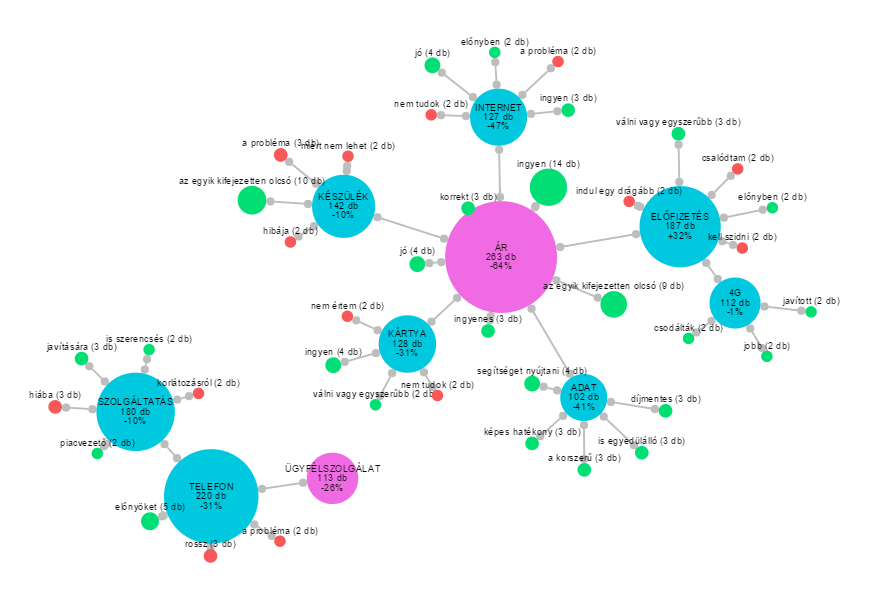
Habár az utóbbi időben más csoport ellen folyik csőstül a gyűlöletbeszéd, a romaellenesség állandónak számít a magyar közhangulatban. Egy korábbi kutatásunkban - melyhez a most elkészült adatvizualizációt szeretnénk bemutatni - ez utóbbi jelenséget vizsgáltuk a kuruc.info beszélő nevű Cigánybűnözés rovatában. Az oldal 2006-os indulásától 2015 elejéig elemeztük a cigányellenes témák időbeli alakulását, amit egy adatvizualizáció segítségével tettünk szemléletessé és interaktívvá.
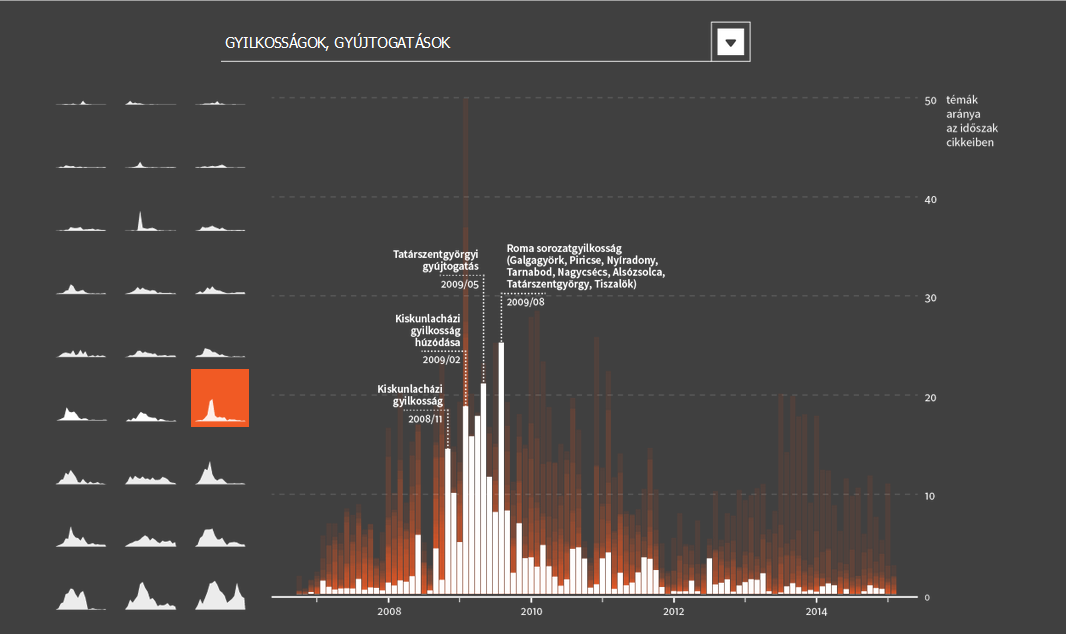
A Cigánybűnözés rovat cikkeinek témáit a látens Dirichlet allokáció (LDA) nevű topik modell segítségével nyertük ki, amivel 27 jól elkülönülő romaellenes témát kaptunk. Hogy a cikkek milyen topikokban íródtak, az idő függvényében is megvizsgáltuk. Így megkaptuk, hogy az egyes témákban mely időszakokban és időpontokban írtak kiemelkedően sokat. Az idősorban megjelenő csúcsok általában egy kirívó eseményhez köthetők, amelyeket az adatvizualizáción is megjelenítettünk. Vannak azonban olyan általános, de mégis gyakori témák (pl. a lopással kapcsolatos hírek vagy a verekedésekről, késelésekről, támadásokról szóló hírek), amelyeknél nem lehet ilyen kirívó, a médiában nagy visszhangot kapott eseményeket meghatározni. A vizualizáción jól látszik, hogy a 2006-tól 2011-ig tartó időszakban a hírportál aktivitása jóval nagyobb volt és többféle speciális témában írtak, míg a 2011-től 2015-ig tartó időszakban inkább olyan általánosabb hírekkel tartották fenn a rovatot, mint a lopásokról szóló hírek.
Az adatvizualizációt Szűcs Krisztina készítette, aki nagyszerű munkát végzett a topikok időbeli megjelenítésével. 2012-ben diplomázott a MOME-n, azóta szabadúszóként foglalkozik adatvizualizációk tervezésével.
Krisztina munkájával nagyon elégedettek vagyunk és mindenkinek csak ajánlani tudjuk, akinek adatvizualizációban szüksége van egy profira!
Krisztinát a szeptember 15-i Budapest Open Knowledge Meetup-on is meghallgathatjátok, ahol az Oktatás és az adatok téma kapcsán fog előadni az OECD és a visualizing.org "The Economic Return on Education" adatvizualizációs pályázatán első helyet szerzett munkájáról.