A blog készítői a Precognox Kft. keretein belül fejlesztenek intelligens, nyelvészeti alapokra épülő keresési, szövegbányászati, big data és gépi tanulás alapú megoldásokat.
Az alábbi keresődobozsegítségével a Precognox által kezelt blogok tartalmában tudsz keresni. A kifejezés megadása után a Keresés gombra kattintva megjelenik vállalati keresőmegoldásunk, ahol további összetett keresések indíthatóak. A találatokra kattintva pedig elérhetőek az eredeti blogbejegyzések.
Ha a blogon olvasható tartalmak kapcsán, vagy témáink alapján úgy gondolod megoldással tudunk szolgálni szöveganalitikai problémádra, lépj velünk kapcsolatba a keresovilag@precognox.com címen.
Precognox Blogkereső
Document
opendata.hu
Az opendata.hu egy ingyenes és nyilvános magyar adatkatalógus. Az oldalt önkéntesek és civil szervezetek hozták létre azzal a céllal, hogy megteremtsék az első magyar nyílt adatokat, adatbázisokat gyűjtő weblapot. Az oldalra szabadon feltölthetőek, rendszerezhetőek szerzői jogvédelem alatt nem álló, nyilvános, illetve közérdekű adatok.
A long time ago, in a galaxy far, far away data analysts were talking about the upcoming new Star Wars movie. One of them has never seen any eposide of the two trilogies before, so they decided to make the movie more accessible to this poor fellow. See more...
A Kereső Világ blogon közölt tartalmak a Precognox Kft. tulajdonát képezik. A tartalom újraközléséhez, amennyiben nem kereskedelmi céllal történik, külön engedély nem szükséges, ha linkeled az eredeti tartalmat és feltünteted a tulajdonos nevét is (valahogy így: Ez az írás a Precognox Kft.Kereső Világ blogján jelent meg). Minden más esetben fordulj hozzánk, a zoltan.varju(kukac)precognox.com címre írt levéllel.
A Magyar Tudományos Akadémia egy igazán illusztris konferenciával kíván tisztelegni a Magyar Tudomány Napja előtt: bemutatkozik az újonnan alakult Számítógépes Társadalomtudomány (Computational Social Science) témacsoport.
Az MTA TK kezdeményezésében a közelmúltban egy intézmény- és tudományágközi Számítógépes Társadalomtudomány (Computational Social Science) témacsoport alakult számos akadémiai kutatóközpont: az MTA KRTK, NYTI, SZTAKI, TK, a Wigner Fizikai Kutatóközpont, valamint a CEU Center for Network Science részvételével. A témacsoport bemutatkozó rendezvényére a Magyar Tudomány Ünnepén kerül sor az MTA Székházában, 2017. november 14-én 9-14 óra között.
Az eseményen a résztvevő intézmények kutatói tartanak nyilvános vitával egybekapcsolt előadásokat. A témacsoport kutatási céljaival összhangban olyan előadásokat hallhatunk majd, amelyek a nyelvtechnológia eszközeit alkalmazó, különböző szociológiai tárgyú vizsgálatokról, illetve problémafelvetésekről számolnak be.
Magam 10.55-től adok elő munkatársaimmal együtt (RECENS kutatócsoport), akikkel egy magyar nyelvű, spontán beszélt nyelvi korpusz létrehozásán dolgozunk annak céljából, hogy megfelelő vizsgálati anyagot teremtsünk a pletyka természetének feltárásához. Előadásunk címe "A pletyka a társas rend szolgálatában. Az informális kommunikáció szerkezetének mélyebb megértéséért a Computational Social Science eszközeivel" címet viseli. Nagyon örülök minden érdeklődőnek, illetve az előadáshoz kapcsolódó bármilyen kérdésnek, észrevételnek!
Alább olvasható a részletes program, amelyre minden érdeklődőt szeretettel várnak a rendezők:
9.00 - 9.10Nyitó gondolatok
9.10 - 9.20Bevezető az előadásokhoz Rudas Tamás, az MTA TK főigazgatója, az ELTE professzora
9.20 - 9.40 Az információs világ és a mi világaink – a kezdetek, az emberi szerep és a robot hisztéria Vámos Tibor, az MTA rendes tagja, az MTA SZTAKI professzor emeritusa
9.40 - 10.00Segíthetnek-e a szóbeágyazási modellek a társadalomtudósoknak? Prószéky Gábor, az MTA Nyelvtudományi Intézete igazgatója, a PPKE professzora; Siklósi Borbála, PPKE-ITK adjunktusa, Natural Language Processing Group; Novák Attila, PhD, PPKE-ITK, Natural Language Processing Group
10.00 - 10.20 Hibrid nyelvtechnológiák Kornai András, az MTA SZTAKI Nyelvtechnológiai Kutatócsoport vezetője, a BME professzora
10.20 - 10.40 Kérdések, vita
10.40 - 10.55 Szünet
10.55 - 11.15 A pletyka a társas rend szolgálatában. Az informális kommunikáció szerkezetének mélyebb megértéséért a Computational Social Science eszközeivel Takács Károly, PhD, az MTA TK RECENS Kutatócsoport vezetője; Galántai Júlia, az MTA TK RECENS Kutatócsoport tudományos segédmunkatársa; Szabó Martina Katalin, az MTA TK RECENS Kutatócsoport tudományos segédmunkatársa
11.15 - 11.35A társadalom hálózati jelenségeinek adatvezérelt vizsgálata Kertész János, az MTA rendes tagja, a CEU Network Science PhD iskola igazgatója, a BME professzora; Vedres Balázs, a CEU Center for Network Science igazgatója
11.35- 11.55 Gépi tanulás, predikció és okság a társadalomtudományokban Muraközy Balázs, PhD, az MTA KRTK Vállalati Stratégia és Versenyképesség ‘Lendület’ kutatócsoportjának vezetője
11.55-12.15Kérdések, vita
12.15- 12.30 Szünet
12.30 - 12.50 A hálózatok felfalják a számítógépeket. A számítások újjászületnek a hálózatokban Lévai Péter, az MTA rendes tagja, az MTA Wigner Fizikai Kutatóközpont főigazgatója; Telcs András, az MTA doktora, MTA PE Budapest rangsor kutatócsoport
12.50 - 13.10Kutatási adatok kezelése az MTA intézményeiben Kovács László, PhD, az MTA SZTAKI Elosztott Rendszerek Osztályának vezetője
13.10 - 13.30 Magyar nyelvtechnológiai infrastruktúra a társadalomtudományok szolgálatában Simon Eszter, PhD, az MTA Nyelvtudományi Intézet tudományos munkatársa; Váradi Tamás, PhD, az MTA Nyelvtudományi Intézet tudományos főmunkatársa
13.30 - 13.50 Kérdések, vita
13.50 - 14.00 Összefoglaló. ASzámítógépes Társadalomtudomány témacsoporttovábbi tevékenységei Péli Gábor, az MTA TK főigazgató-helyettese
A Kereső Világ a Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Az 1956-os dartmouth-i konferencia óta várjuk a nagy áttörést a mesterséges intelligencia terén. Miután végig próbáltunk mindent, a logikától a bayesiánus megközelítésen át konnekcionizmus (fiatalabbaknak deep learning) megannyi újjászületésén át, továbbra is ott tartunk, hogy nehezen tudjuk igazán intelligensnek tartani az olyan programokat, melyek 99.99999%-os pontossággal mondják meg hogy cica van-e egy adott képen. A deep learning rendszerek átverése külön "sporttá" vált a kutatók körében (kedvenc példánk itt), de már a kilencvenes években is az idegtudományok felé fordultak a hasonló problémák megoldására és az érdeklődés a figyelmi (attention) mechanizmusok felé fordult. Ennek egyik eredménye a ma deep learning rendszerekbe már be is épült (itt erről egy összefoglaló). Ezekben az időkben a kutatások egy másik irányt is vettek; mivel a figyelmi mechanizmusok összefüggésben állnak érzelmeinkkel, ezek megértése segíthet a technológia jobb alkalmazásában is. Megszületett a magyarra csak nagyon hülyén fordítható affective computing, ezt mutatja be Richard Yonk Heart of the Machine - Our Future in a World of Artificial Emotional Intelligence című könyve.
A kötet nagyon feszesen vezeti végig az olvasót az affective computing kialakulásán. Az első két fejezet tkp. letudja azt, amit a kognitív tudomány eredményeiből tudni kell, ezután jöhet a technológiai fejlemények bemutatása, ami amúgy egyben a híres Affectiva-ról szól. Ez a sztori két kutató - Rosalind Picard (az affective computing alapítója!) és Rana el Kaliouby - útja az akadémiai kutatásoktól az üzleti alkalmazásokig. Az affective computing kutatások eredetileg inkább asszisztív technológiai megoldásokra koncentráltak, pl. autisták számára megkönnyíteni beszélgetőtársaik érzelmeinek felismerését. No ehelyett ma főleg marketing célokat szolgál az Affectiva (vagy éppen a Realeyes, Beyond Verbal, stb.), ami persze nem baj, csak érdekes. Mivel a szerző szerint az affective computing leginkább az ember-gép kommunikáció terén válik egyre fontosabbá, azt láthatjuk, hogy ezen a területen nem igazán alkalmazzák az elérhető technológiákat még. Ami igazán fura volt számomra, hogy a szerző saját kis történetekkel próbálja felvázolni, hogyan is fog kinézni az a nem túl távoli jövő, amikor marketing helyett másra is lehet végre használni egy érzelemfelismeréssel felvértezett technológiát. Számomra nem annyira meggyőző az az érvelés, hogy egyszer ezt is el kell érni, ha intelligens rendszereket akarunk. Ennek ellenére a könyv rövid, érdekes és informatív, ergo mindenkinek ajánlani tudjuk.
Akit érdekel mire jó ez az egész, az alább láthatja hogyan dolgozik együtt saját emóciószótárunk a szövegek elemzése során a Microsoft API arcelemzőjével és a Beyond Verbal hangelemzőjével.
A Kereső Világ a Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
A felületes szemlélődő számára úgy tűnhet, a deep learning csupán az internet nagy kérdéseire fókuszál; cuki cica van-e egy adott képen vagy nem, van Gogh stílusú profilképünk legyen vagy adott ember stílusában generáljunk szövegeket. Akadnak olyan mellékszálak, mint az önvezető autók, melyek azért elérik a szélesebb publikum ingerküszöbét, hiszen ezek a szerkezetek olyanok mint egy megvalósult sci-fi, arról már nem is beszélve, hogy lehet rettegni, hogy mennyi embert fognak megölni és/vagy munkanélkülivé tenni. Kína pedig az egész országot befedő arcfelismerő rendszer bevezetését tervezi és mindenki a Nagy Testvér eljövetelét látja. Mindeközben már régen figyelnek minket az űrből apró műholdak százai, melyek irdatlan adattömeget küldenek az adatközpontokba, ahol a modern képfeldolgozásnak hála ma már napi szinten monitorozzák az olajfinomítók kapacitását, a bevásárlóközpontok parkolóinak kihasználtságát, az épülő iparkapacitások kiterjedtségét, a termőföldek állapotát és várható hozamát, vagy éppen a Dél-kínai-tengeren épülő mesterséges szigeteket.
1957-ben lőtték fel az első műholdat, a Szputyinkot. Azóta eltelt pár év, fejlődött a technológia és teret nyertek a nyílt adatok, ezért ma már a NASA, az ESA és még vagy tucatnyi űrügynökség is szabadon elérhetővé teszi adatainak egy részét. A szabályozás folyamatosan puhul, ezért megjelentek a kereskedelmi műholdak is. Az utóbbi időkben az olyan úttörő cégek hatására mint pl. a Planet, pedig divatba jöttek a cipősdoboznyi kis műholdak, melyekből egy-egy százas nagyságrendű hálózatot üzemeltet egy startup. A miniműholdaknak hála akár naponta is kaphatunk képet egy minket érdeklő területről, ami beindította az analitika területén ügyködők agyát is:
a Descartes Labs több szolgáltatótól gyűjti a műholdképeket és térkép szolgáltatást, mezőgazdasági előrejelzést, fogyasztói indexet, stb. készít ügyfeleinek, azok akik maguk akarnak összedobni egy modellt, pedig API-n keresztül férhetnek hozzá az adatokhoz. A legvadabb dolog tőlük egy vizuális kereső, amivel a műholdképek között vizuális jegyek alapján kutakodhatunk!
a Planet és az Orbital Insight egyszerre biztosít műholdas és adatelemzési infrastruktúrát
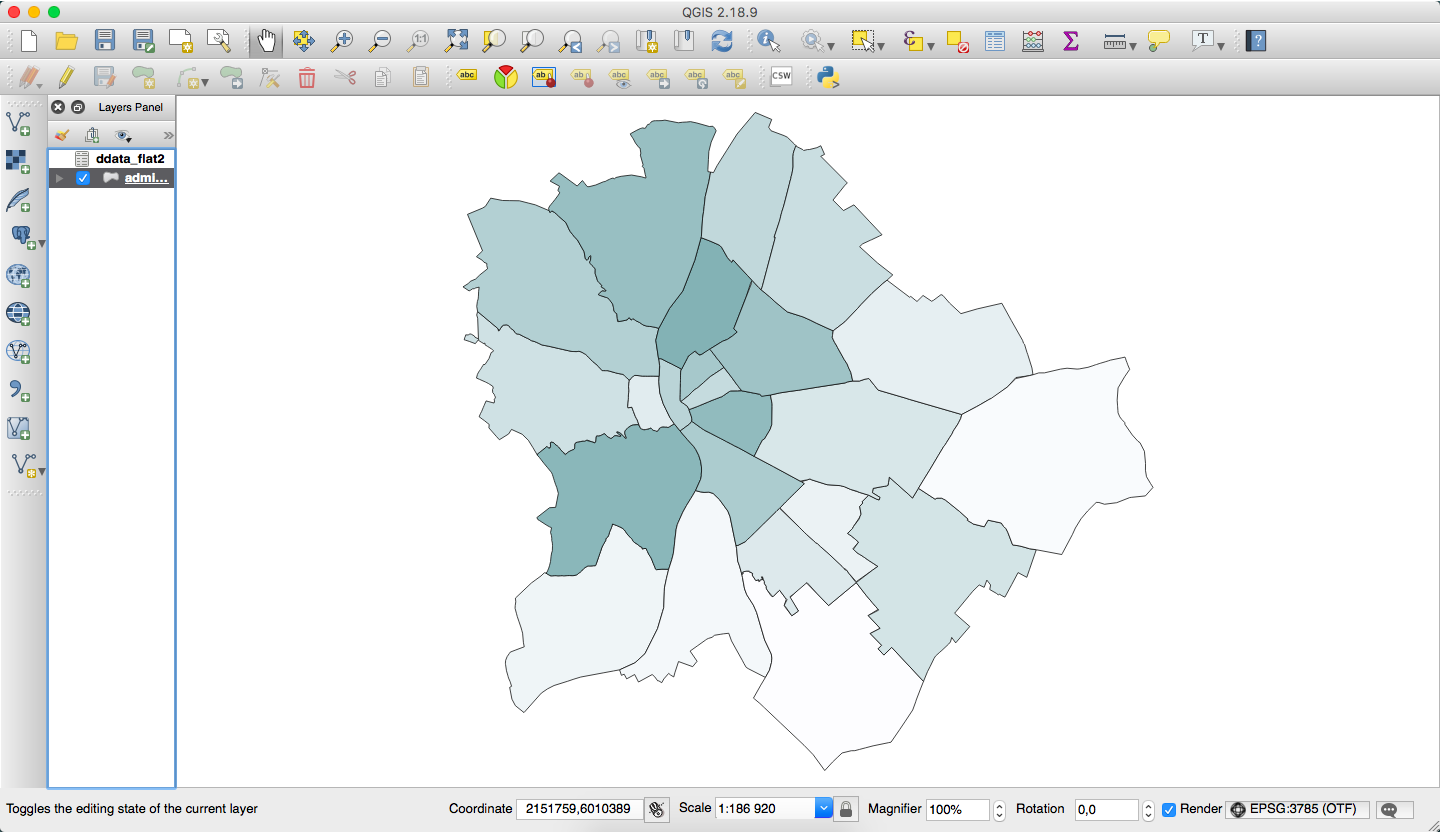
Dőlnek tehát az adatok, jelentős részük nyílt, illetve a kereskedelmi szolgáltatók NGO-k és kutatók számára általában ingyenes hozzáférést biztosítanak. Ezek elemzése ma már nem lehetetlen feladat, a Python például remekül el van látva olyan könyvtárakkal, melyekkel segítségével könnyen elvégezhetők a legalapvetőbb elemzések, de a QGIS is sok plugin-t nyújt erre. Ha például az érdekel minket, hogyan alakult a zöldterületek aránya Budapesten és környékén az utóbbi években, akkor kb. 20 perc alatt elkészíthetjük az alábbi kis vizut. A Landsat 7 képei egész jól lefedik a régiót és habár nem találtunk a zöldterületek azonosítására használt NDVI indexre Python implementációt, az annyira egyszerű, hogy két kódsorba megírtuk.
Komolyabb feladatok sem megoldhatatlanok ma már. A Descartes Labs vizuális keresőjéhez pl. egy szabadon elérhető Imagenet-et használta ResNet architektúrája előtrénelésére, hogy aztán azt az OpenStreetMap földhasználati kategóriák azonosítására tanítsa ki. Igen, egy tök általános modell transzferáltak műholdképekre! (Bővebben itt lehet olvasni erről)
A "new space" mozgalomnak még csak az elején járunk, de már láthatatlanul behálóznak minket a műholdas megfigyelések. Miközben a robotoktól és az önvezető autóktól félünk és próbálunk előre kitalálni megoldásokat olyan problémákra, melyek még nem is jelentkeztek, elsiklunk a felett, hogy ma már az égből figyelik mit építünk, hol parkolunk, mit termesztünk, stb.
A Kereső Világ a Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
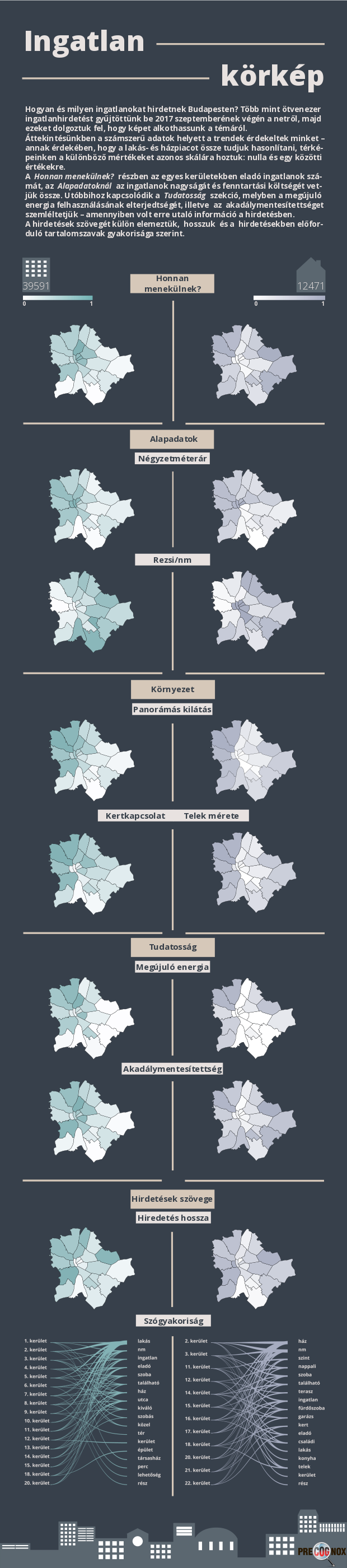
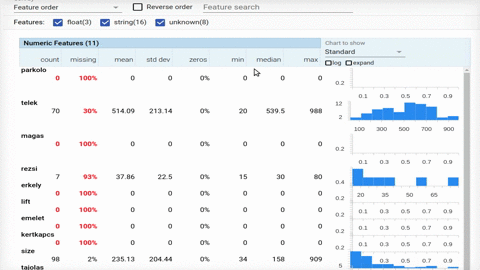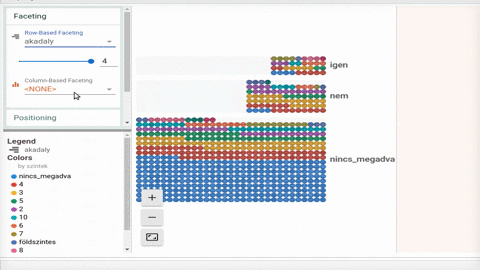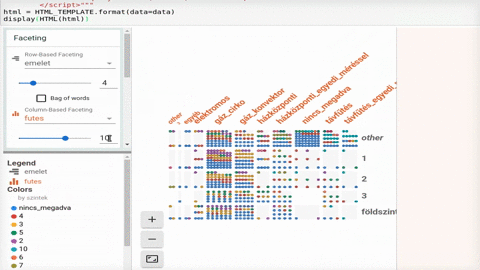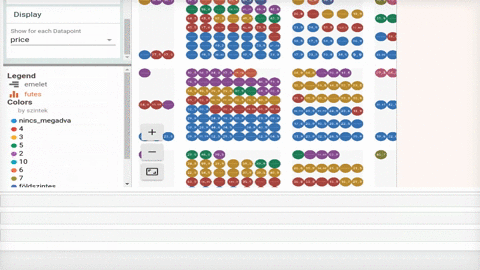
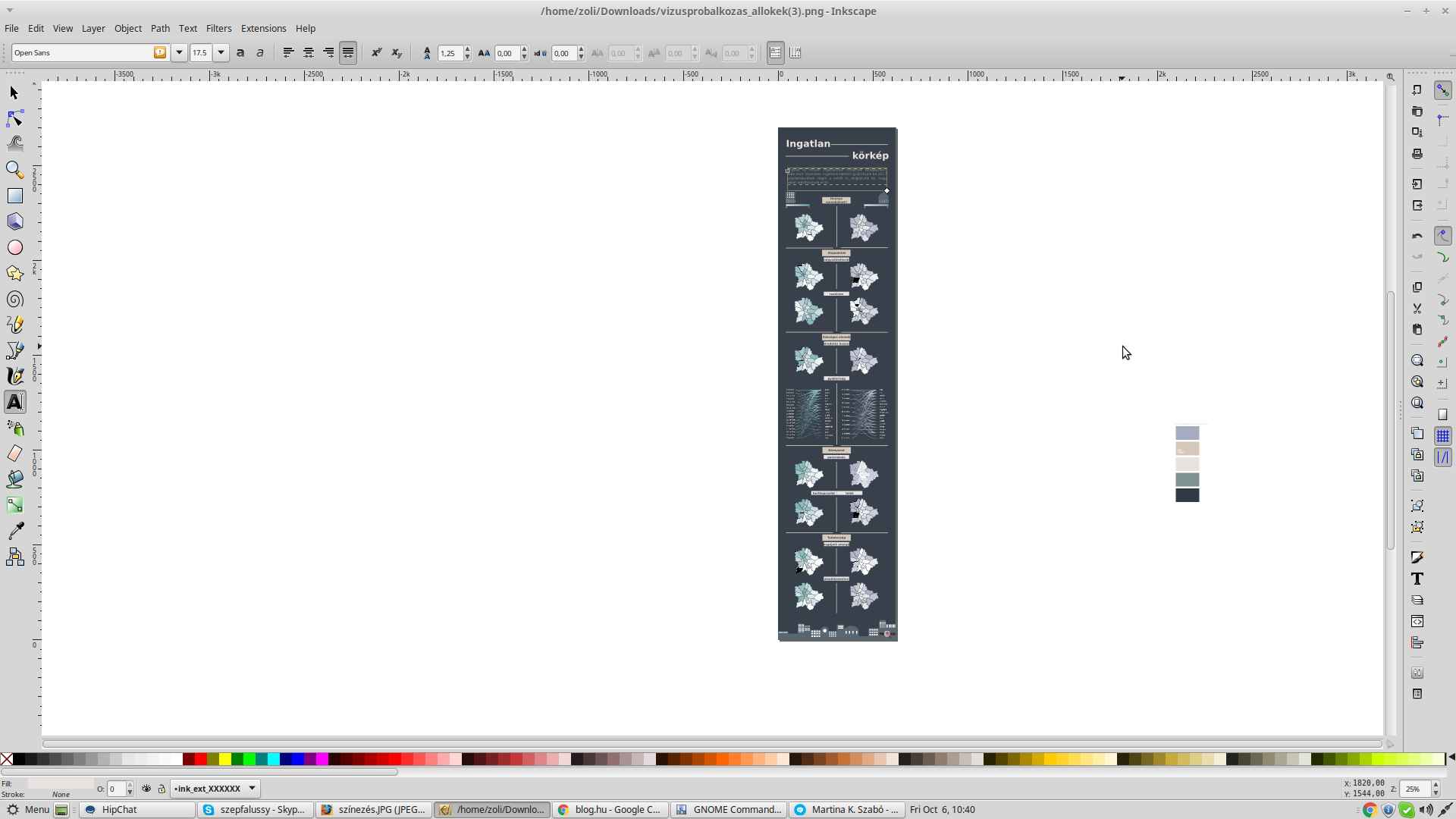
Régóta dolgozunk azon, hogy adatelemzési projektjeink végén ügyfeleink számára nem csak szakmailag pontos és használható, hanem vizuálisan is elfogadható riportokat tudjunk szállítani. Először az interaktív vizualizációkat használó riport formáját dolgoztuk ki, erre példa a Migráció arcai projektünk. Ennek során alapelvünk volt, hogy kizárólag open source eszközökkel dolgozzunk és amikor csak lehetséges, ne közvetlenül JavaScript könyvtárakkal, hanem Python-ból elérhető csomagok használatával generáljunk vizualizációkat. Ehhez a statikus riportok készítésénél is tartjuk magunkat, amire példa az alább látható infografika, ennek elkészítéséről szól ez a kis poszt.
A nyers adatoktól a megmutatni kívánt információig
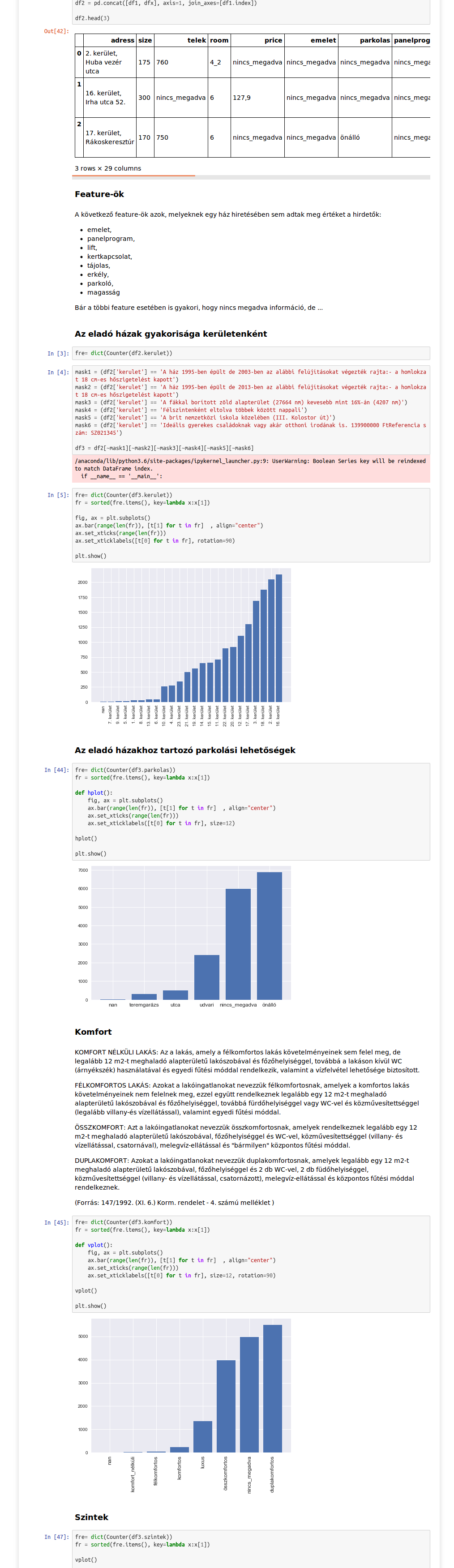
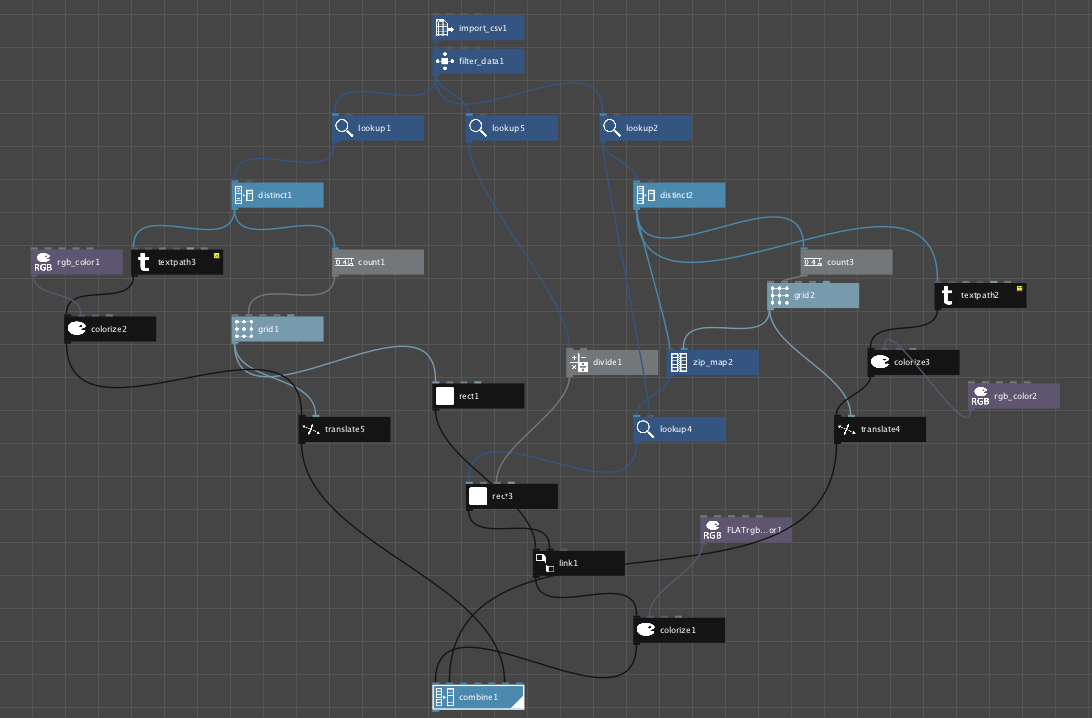
Az adatok begyűjtésére, előfeldolgozására és a feature-ök kinyerésére Pythonban írtunk egy pipeline-t. Köszi Luigi!
A nyers adatokon először a hagyományos EDA (Exploratory Data Analysis) fázist végeztük el, pl. ilyen szép Jupyter Notebook-ban néztük meg hogy mi van az egyes feature-ökkel.
Majd megnéztük a Google Facets segítségével is hogy mi a helyzet.
Az EDA során kiválasztottuk mit szeretnénk megmutatni az adathalmazból. Ezután legeneráltuk az aggregált adatokat kerületenként és jöhetett maga a vizualizáció.
Mivel dolgoztunk?
A szógyakorisági adathoz Nodebox-ban készítettünk linkes digarammot. A Nodebox egy Python alapú vizuális programozási környezet, amivel viszonylag könnyen és gyorsan lehet szép ábrákat generálni.
Az egyes ábrákat végül Inkscape segítségével szerkesztettük egy infografikába.
Ha prezentálni is szeretnénk
A Sozi segítségével az elkészült svg alapból pedig prezentációt is lehet készíteni, ami egy egyszerű kis html oldalt jelent. Az infografikánkból generált prezi itt érhető el, vagy egy kicsit lentebb beágyazva a posztba.
Régi álmunk vált valóra azzal, hogy kidolgoztuk a statikus riportok elkészítésének folyamatát. Tudjuk, még messze vagyunk a tökéletes végeredménytől, de örülünk annak, hogy megtettük az első lépést.
A Kereső Világ a Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.
Amint azt a Portfolio hírül adta, az IBM által fejlesztett, Watson névre keresztelt robot újabban már az emberi érzelmeket is felismeri. A cég egy különleges megkeresésre fejlesztette tovább Watsont úgy, hogy az a lelkünkbe láthasson.
Az egész a Wells Fargo tavaly kirobbant számlabotrányával kezdődött. Az Egyesült Államok egyik legnagyobb bankjának alkalmazottai, amint az a vizsgálatok során kiderült, az utóbbi öt évben kétmillió betéti és hitelkártyaszámlát létesítettek klienseiknek anélkül, hogy azok tudtak volna erről. A csalásra az csábította a dolgozókat, hogy a nagyobb teljesítmény, vagyis a több termék értékesítése nagyobb bónuszt hozott nekik a kasszára.
A Világgazdaság adatai alapján a Wells Fargo 2011 óta nagyjából 5300 alkalmazottat bocsátott el, noha közülük csak több százan voltak, akik illegálisan nyitottak számlát. Sokan – köztük vezető beosztásban lévők – azért kaptak útilaput, mert szemet hunytak a csalások felett.
A botrány után a hitelintézetekben jelentős igény támadt az alkalmazottak alaposabb monitorozására abból a célból, hogy egy esetleges hasonló csalássorozatot el lehessen kerülni. Az International Business Machines Corporationt (IBM) is megkeresték azzal a kérdéssel, hogy lehetséges-e a lakossági üzletágban dolgozó értékesítőket, hitelügyintézőket és más dolgozókat valamilyen módon behatóbban megfigyelni. Az IBM úgy gondolta, Watsonra bízza a piszkos munkát.
Watson akkor vált igazán híressé, amikor 2011-ben a Jeopardy! nevű televíziós vetélkedőben – amely hasonló a hazai Mindent vagy semmit! című játékhoz – két kiváló képességű játékost legyőzött.
A mérkőzésre a vetélkedő két legsikeresebb hajdani résztvevőjét hívták meg: Brad Ruttert, aki a játék történetében az addigi legnagyobb nyeremény birtokosa, és Ken Jenningst, aki pedig a leghosszabb ideig, összesen nem kevesebb mint 75 napig tartotta magát folyamatos játékban. Az összecsapás során Watsonnak a versenytársakkal azonos körülményeket biztosítottak: nem csatlakozhatott az internethez, és a kérdéseket a játékvezetőtől ő is élőszóban kapta. A szuperszámítógép végül 1 millió, Ken Jennings 300 000, Brad Rutter pedig 200 000 amerikai dollárt nyert.
Az IBM már a Wells Fargo megkeresése előtt is bevetette a banki szférában Watsont: a banki kereskedőket vizsgálta, amit több nagybank, illetve kisebb regionális pénzintézet is tesztelt. Ésszerű döntés volt tehát, hogy most is ő kapja a feladatot, akinek már van a területen szerzett tapasztalata.
Előbb azonban a cég továbbképzésre küldte Watsont: megtanították őt az olyan adatoknak az észrevételére, amelyek a Wells Fargo-ban történt botrány előjeleiként értelmezhetőek. Ennek köszönhetően felfigyel a gyanús logókra, a használatlan termékekre és számlákra, valamint a rossz adatokra és értesítési kérésekre.
De ez messze nem minden: Watson elolvassa az alkalmazottak emailjeit és megvizsgálja még a telefonhívásokaikat is. Olyan nyomokat keres az írott és a hangzó szövegekben, amelyek valamilyen nem megfelelő viselkedésre (pl. a menedzsereknek az értékesítési csapatra gyakorolt, nem kívánatos jellegű és mértékű nyomására) utalhatnak a dolgozói rendszerben.
És csak most jön a java: Watson még egyes érzelmek felismerésére is képes! Meg tudja például állapítani, ha egy munkatárs mérges, undorodik valamitől, fél, örül, szomorú, vagy éppen agresszív. Amint ugyanis arra a Portfolio is rámutat, az emóciók kiváló indikátorai lehetnek a gyanús viselkedésnek. A cikk két érdekes tendenciát említ példaként. Egy amerikai tapasztalat szerint a legendásan trágár amerikai kereskedők profánsága jelentősen csökken, mielőtt valami illegálisat cselekszenek. Az Egyesült Királyságban ugyanakkor ennek pont az ellenkezőjét tapasztalták: az etikátlan viselkedésre készülő kereskedők többet káromkodnak a séma kivitelezése előtt.
Azt, hogy Watson mennyire hatékonyan ismeri fel az érzelmeket az írott szövegekben, bárki tesztelheti az eszköz honlapján, egy demo program segítségével. Az elemezni kívánt szöveget a megfelelő formátumban fel kell töltenünk, majd azt az elemző a következő fő lépésekben feldolgozza:
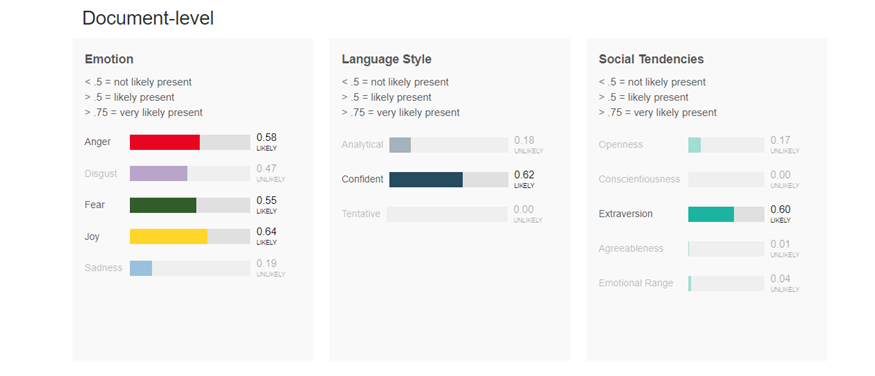
Mindezek után, egy tetszőlegesen bevitt, angol nyelvű szöveget elemeztetve az alábbihoz hasonló eredményt kapunk:
Egy példa Watson elemzési eredményeire, írott szöveg alapján (forrás: ibm.com)
Amint azt a Portfolio ugyanakkor megjegyzi, Watson elemzése sajnos rengeteg hamis pozitívot generál. Éppen ezért a találatokat legtöbbször humán erő bevonásával felül kell vizsgálni.
Saját emócióelemzésünk, avagy amit mi csinálunk...
Amint arról már többször beszámoltunk a blogon, magunk is foglalkozunk automatikus emócióelemzéssel, és sokat dolgozunk azon, hogy az eszközünket jobbá és jobbá tegyük. Lássuk csak, mit is csináltunk eddig!
Először is, pszichológiai eredményekre alapozva készítettünk egy magyar nyelvű emóciószótárat, majd azt a létrehozás és a vizsgálati tapasztalataink alapján továbbfejlesztettük. Emellett elkészítettünk egy kézzel annotált emóciókorpuszt is, amelyben nem csupán az ominózus emóciókifejezéseket jelöltük be, hanem minden olyan egyéb nyelvi elemet, amelyről úgy gondoltuk, hogy mind vizsgálati, mind fejlesztési szempontból hasznos lehet a későbbiekben.
A szótárainkat (annak első és második verzióját) számtalan automatikus tartalomelemzési feladatban felhasználtuk, és munkánk során érdekes, eleddig ismeretlen összefüggéseket tártunk fel az érzelmek, a szentimentek és a különböző egyéb szövegtartalmak (pl. a topikok) között. Eredményeinket sok konferencián (pl. Nyelv, kultúra, társadalom; MANYE; OSINT; Media Hungary; MSZNY stb.) és számos posztban ismertettük. Szonifikáltunk, dashboardot készítettünk romaellenes cikkekből, demóztunk szüléssel kapcsolatos interjúk alapján, meg egy csomót politizáltunk. Még multimodális emócióelemzést is végeztünk a céges hackathonon ‒ csak néhányat említve közülük.
És amin jelenleg dolgozunk...
A magyar nyelvű elemzések után úgy döntöttünk, megnézzük, mi a helyzet az orosz fronton. Létrehoztunk egy orosz nyelvű emóció-, valamint szentimentszótárat, továbbá egy nagy méretű, orosz nyelvű szépirodalmi szövegekből álló korpuszt. Munkatársunk, Nyíri Zsófi azon dolgozik, hogy a korpusz automatikus, emóció- és szentimentszótáras elemzésével feltárja az orosz szépirodalmi művek narratívatípusait. Munkájának eddigi, érdekes tapasztalatairól a II. Szláv Filológiai és Kultúratudományi Konferencián számolt be nem rég.
A projekt egy távolabbi, ugyanakkor fontos célja, hogy kísérletet tegyen a nyelvi emóciók párhuzamos vizsgálatára magyar, orosz, valamint angol nyelvű szövegekben.
Ugyancsak ehhez a projekthez kapcsolódóan azon is munkálkodunk, hogy a funkciószók és az emóciók közötti, eleddig rejtett összefüggéseket is feltárjuk. Korábban már posztoltunk arról, hogy, bár a funkciószók kiváló indikátorai lehetnek bizonyos, úgymond a szöveg "mélyebb rétegeiben húzódó" sajátságoknak, azokat a tartalomelemző feladatokban nemigen aknázzák ki a nyelvtechnológusok.
De miért is irányítsuk figyelmünket a funkciószókra a tartalomelemzésben? Miért ne csupán azokra a bizonyos tartalmas szavakra fókuszáljunk?
Amint azt már az említett posztban is ismertettük, a szociálpszichológus Pennebaker 2011-ben publikált könyve, a The Secret Life of Pronouns alapján, a nyelvhasználat során tudatosan alapvetően a tartalmas szavakra fókuszálunk. Ez azt jelenti, hogy amikor szövegeket alkotunk, kevésbé vagyunk megfontoltak a funkciószók használatát illetően; inkább a közölni kívánt szemantikai tartalomra, így szükségképpen elsősorban a tartalmas szavakra koncentrálunk. Ugyanakkor a kommunikációnk során a funkciószó-használatunkkal tudattalanul is olyan információkat közlünk magunkról, mint például a nemünk, a korunk, a szociális viszonyaink vagy az aktuális érzelmi állapotunk ‒ amelyeket esetleg egyáltalán nem is szerettünk volna a partner tudomására hozni. Pennebaker szerint tehát a funkciószó-használatunk az érzelmi állapotunkról is árulkodik, vagyis ezeknek a szöveges realizációja szorosan összefügg a beszélő emócióival.
Ezzel együtt, amint arra a szerző felhívja a figyelmet, a 20 leggyakoribb előfordulású angol szó között kizárólag funkciószókat találunk, s pusztán ez a húsz elem megközelítőleg a 30%-át teszi ki az angol nyelvi produktumoknak, az írott és a beszélt nyelvet illetően egyaránt.
A kérdést a magyar nyelv vonatkozásában, a Magyar Nemzeti Szövegtár adatait megnézve hasonló eredményt kapunk: a 20 legyakoribb szó között a magyar nyelvet illetően is, akárcsak az angolban, rendre funkciószókat találunk.
A funkciószók vizsgálatától, különösen az emócióelemzéssel együtt alkalmazva igazán figyelemre méltó összefüggések feltárását remélhetjük.
Jelenleg tehát azon dolgozunk, hogy az orosz nyelvű korpuszunkban végrehajtsuk az emóciók, a funkciószók és a szentimentek komplex feldolgozását.
A Kereső Világ a Precognox szakmai blogja A Precognox intelligens, nyelvészeti alapokra építő keresési, szövegbányászati és big data megoldások fejlesztője.










 De ez messze nem minden: Watson elolvassa az alkalmazottak emailjeit és megvizsgálja még a telefonhívásokaikat is.
De ez messze nem minden: Watson elolvassa az alkalmazottak emailjeit és megvizsgálja még a telefonhívásokaikat is. 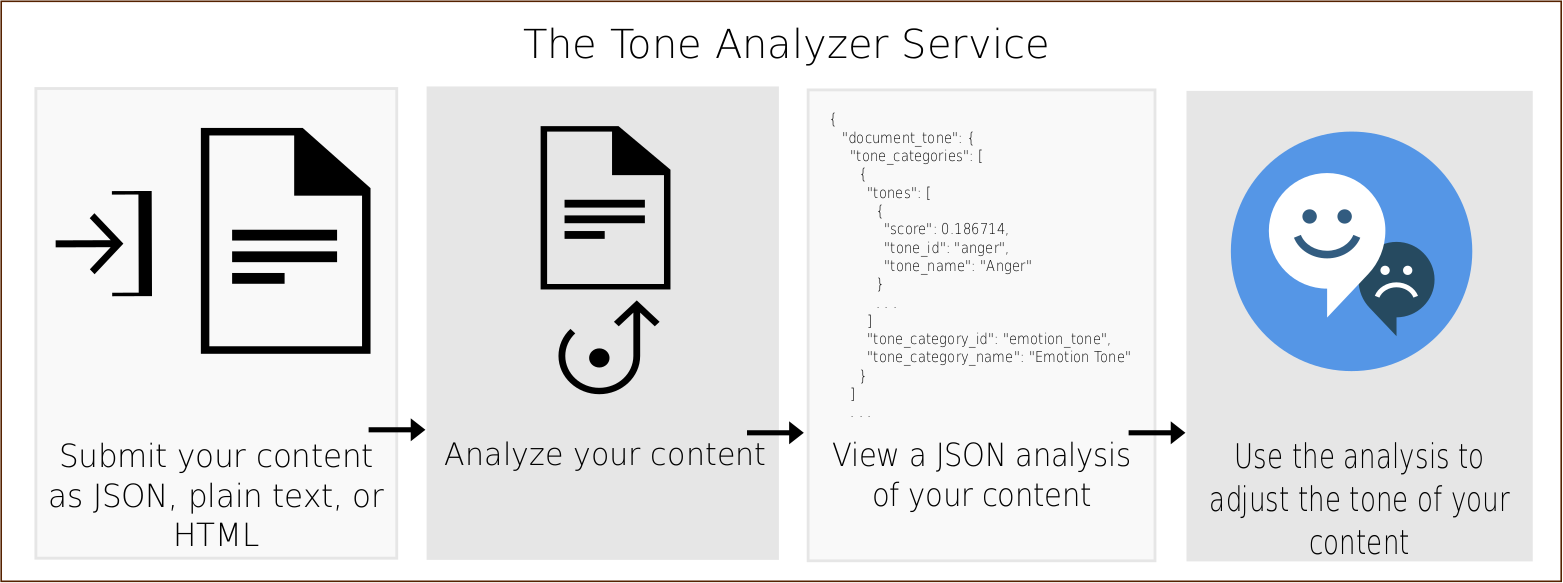

 Amint azt már az említett posztban is ismertettük, a szociálpszichológus
Amint azt már az említett posztban is ismertettük, a szociálpszichológus  Ezzel együtt, amint arra a szerző felhívja a figyelmet, a 20 leggyakoribb előfordulású angol szó között kizárólag funkciószókat találunk, s pusztán ez a húsz elem megközelítőleg a 30%-át teszi ki az angol nyelvi produktumoknak, az írott és a beszélt nyelvet illetően egyaránt.
Ezzel együtt, amint arra a szerző felhívja a figyelmet, a 20 leggyakoribb előfordulású angol szó között kizárólag funkciószókat találunk, s pusztán ez a húsz elem megközelítőleg a 30%-át teszi ki az angol nyelvi produktumoknak, az írott és a beszélt nyelvet illetően egyaránt.