



Amint azt a Portfolio hírül adta, az IBM által fejlesztett, Watson névre keresztelt robot újabban már az emberi érzelmeket is felismeri. A cég egy különleges megkeresésre fejlesztette tovább Watsont úgy, hogy az a lelkünkbe láthasson.

Az egész a Wells Fargo tavaly kirobbant számlabotrányával kezdődött. Az Egyesült Államok egyik legnagyobb bankjának alkalmazottai, amint az a vizsgálatok során kiderült, az utóbbi öt évben kétmillió betéti és hitelkártyaszámlát létesítettek klienseiknek anélkül, hogy azok tudtak volna erről. A csalásra az csábította a dolgozókat, hogy a nagyobb teljesítmény, vagyis a több termék értékesítése nagyobb bónuszt hozott nekik a kasszára.
A Világgazdaság adatai alapján a Wells Fargo 2011 óta nagyjából 5300 alkalmazottat bocsátott el, noha közülük csak több százan voltak, akik illegálisan nyitottak számlát. Sokan – köztük vezető beosztásban lévők – azért kaptak útilaput, mert szemet hunytak a csalások felett.
A botrány után a hitelintézetekben jelentős igény támadt az alkalmazottak alaposabb monitorozására abból a célból, hogy egy esetleges hasonló csalássorozatot el lehessen kerülni. Az International Business Machines Corporationt (IBM) is megkeresték azzal a kérdéssel, hogy lehetséges-e a lakossági üzletágban dolgozó értékesítőket, hitelügyintézőket és más dolgozókat valamilyen módon behatóbban megfigyelni. Az IBM úgy gondolta, Watsonra bízza a piszkos munkát.

Watson, a mesterséges intelligencia kinézete (forrás: businessinsider.com)
Watson akkor vált igazán híressé, amikor 2011-ben a Jeopardy! nevű televíziós vetélkedőben – amely hasonló a hazai Mindent vagy semmit! című játékhoz – két kiváló képességű játékost legyőzött.
A mérkőzésre a vetélkedő két legsikeresebb hajdani résztvevőjét hívták meg: Brad Ruttert, aki a játék történetében az addigi legnagyobb nyeremény birtokosa, és Ken Jenningst, aki pedig a leghosszabb ideig, összesen nem kevesebb mint 75 napig tartotta magát folyamatos játékban. Az összecsapás során Watsonnak a versenytársakkal azonos körülményeket biztosítottak: nem csatlakozhatott az internethez, és a kérdéseket a játékvezetőtől ő is élőszóban kapta. A szuperszámítógép végül 1 millió, Ken Jennings 300 000, Brad Rutter pedig 200 000 amerikai dollárt nyert.
Az IBM már a Wells Fargo megkeresése előtt is bevetette a banki szférában Watsont: a banki kereskedőket vizsgálta, amit több nagybank, illetve kisebb regionális pénzintézet is tesztelt. Ésszerű döntés volt tehát, hogy most is ő kapja a feladatot, akinek már van a területen szerzett tapasztalata.
Előbb azonban a cég továbbképzésre küldte Watsont: megtanították őt az olyan adatoknak az észrevételére, amelyek a Wells Fargo-ban történt botrány előjeleiként értelmezhetőek. Ennek köszönhetően felfigyel a gyanús logókra, a használatlan termékekre és számlákra, valamint a rossz adatokra és értesítési kérésekre.
 De ez messze nem minden: Watson elolvassa az alkalmazottak emailjeit és megvizsgálja még a telefonhívásokaikat is. Olyan nyomokat keres az írott és a hangzó szövegekben, amelyek valamilyen nem megfelelő viselkedésre (pl. a menedzsereknek az értékesítési csapatra gyakorolt, nem kívánatos jellegű és mértékű nyomására) utalhatnak a dolgozói rendszerben.
De ez messze nem minden: Watson elolvassa az alkalmazottak emailjeit és megvizsgálja még a telefonhívásokaikat is. Olyan nyomokat keres az írott és a hangzó szövegekben, amelyek valamilyen nem megfelelő viselkedésre (pl. a menedzsereknek az értékesítési csapatra gyakorolt, nem kívánatos jellegű és mértékű nyomására) utalhatnak a dolgozói rendszerben.
És csak most jön a java: Watson még egyes érzelmek felismerésére is képes! Meg tudja például állapítani, ha egy munkatárs mérges, undorodik valamitől, fél, örül, szomorú, vagy éppen agresszív. Amint ugyanis arra a Portfolio is rámutat, az emóciók kiváló indikátorai lehetnek a gyanús viselkedésnek. A cikk két érdekes tendenciát említ példaként. Egy amerikai tapasztalat szerint a legendásan trágár amerikai kereskedők profánsága jelentősen csökken, mielőtt valami illegálisat cselekszenek. Az Egyesült Királyságban ugyanakkor ennek pont az ellenkezőjét tapasztalták: az etikátlan viselkedésre készülő kereskedők többet káromkodnak a séma kivitelezése előtt.
Azt, hogy Watson mennyire hatékonyan ismeri fel az érzelmeket az írott szövegekben, bárki tesztelheti az eszköz honlapján, egy demo program segítségével. Az elemezni kívánt szöveget a megfelelő formátumban fel kell töltenünk, majd azt az elemző a következő fő lépésekben feldolgozza:
Az elemzés lépései (forrás: ibm.com)
Mindezek után, egy tetszőlegesen bevitt, angol nyelvű szöveget elemeztetve az alábbihoz hasonló eredményt kapunk:
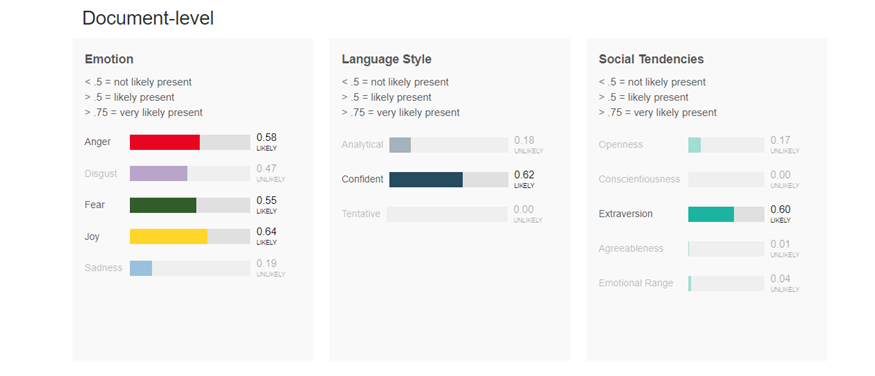
Saját emócióelemzésünk, avagy amit mi csinálunk...
Amint arról már többször beszámoltunk a blogon, magunk is foglalkozunk automatikus emócióelemzéssel, és sokat dolgozunk azon, hogy az eszközünket jobbá és jobbá tegyük. Lássuk csak, mit is csináltunk eddig!
Először is, pszichológiai eredményekre alapozva készítettünk egy magyar nyelvű emóciószótárat, majd azt a létrehozás és a vizsgálati tapasztalataink alapján továbbfejlesztettük. Emellett elkészítettünk egy kézzel annotált emóciókorpuszt is, amelyben nem csupán az ominózus emóciókifejezéseket jelöltük be, hanem minden olyan egyéb nyelvi elemet, amelyről úgy gondoltuk, hogy mind vizsgálati, mind fejlesztési szempontból hasznos lehet a későbbiekben.
A szótárainkat (annak első és második verzióját) számtalan automatikus tartalomelemzési feladatban felhasználtuk, és munkánk során érdekes, eleddig ismeretlen összefüggéseket tártunk fel az érzelmek, a szentimentek és a különböző egyéb szövegtartalmak (pl. a topikok) között. Eredményeinket sok konferencián (pl. Nyelv, kultúra, társadalom; MANYE; OSINT; Media Hungary; MSZNY stb.) és számos posztban ismertettük. Szonifikáltunk, dashboardot készítettünk romaellenes cikkekből, demóztunk szüléssel kapcsolatos interjúk alapján, meg egy csomót politizáltunk. Még multimodális emócióelemzést is végeztünk a céges hackathonon ‒ csak néhányat említve közülük.

És amin jelenleg dolgozunk...
A magyar nyelvű elemzések után úgy döntöttünk, megnézzük, mi a helyzet az orosz fronton. Létrehoztunk egy orosz nyelvű emóció-, valamint szentimentszótárat, továbbá egy nagy méretű, orosz nyelvű szépirodalmi szövegekből álló korpuszt. Munkatársunk, Nyíri Zsófi azon dolgozik, hogy a korpusz automatikus, emóció- és szentimentszótáras elemzésével feltárja az orosz szépirodalmi művek narratívatípusait. Munkájának eddigi, érdekes tapasztalatairól a II. Szláv Filológiai és Kultúratudományi Konferencián számolt be nem rég.
A projekt egy távolabbi, ugyanakkor fontos célja, hogy kísérletet tegyen a nyelvi emóciók párhuzamos vizsgálatára magyar, orosz, valamint angol nyelvű szövegekben.
Ugyancsak ehhez a projekthez kapcsolódóan azon is munkálkodunk, hogy a funkciószók és az emóciók közötti, eleddig rejtett összefüggéseket is feltárjuk. Korábban már posztoltunk arról, hogy, bár a funkciószók kiváló indikátorai lehetnek bizonyos, úgymond a szöveg "mélyebb rétegeiben húzódó" sajátságoknak, azokat a tartalomelemző feladatokban nemigen aknázzák ki a nyelvtechnológusok.
De miért is irányítsuk figyelmünket a funkciószókra a tartalomelemzésben? Miért ne csupán azokra a bizonyos tartalmas szavakra fókuszáljunk?
 Amint azt már az említett posztban is ismertettük, a szociálpszichológus Pennebaker 2011-ben publikált könyve, a The Secret Life of Pronouns alapján, a nyelvhasználat során tudatosan alapvetően a tartalmas szavakra fókuszálunk. Ez azt jelenti, hogy amikor szövegeket alkotunk, kevésbé vagyunk megfontoltak a funkciószók használatát illetően; inkább a közölni kívánt szemantikai tartalomra, így szükségképpen elsősorban a tartalmas szavakra koncentrálunk. Ugyanakkor a kommunikációnk során a funkciószó-használatunkkal tudattalanul is olyan információkat közlünk magunkról, mint például a nemünk, a korunk, a szociális viszonyaink vagy az aktuális érzelmi állapotunk ‒ amelyeket esetleg egyáltalán nem is szerettünk volna a partner tudomására hozni. Pennebaker szerint tehát a funkciószó-használatunk az érzelmi állapotunkról is árulkodik, vagyis ezeknek a szöveges realizációja szorosan összefügg a beszélő emócióival.
Amint azt már az említett posztban is ismertettük, a szociálpszichológus Pennebaker 2011-ben publikált könyve, a The Secret Life of Pronouns alapján, a nyelvhasználat során tudatosan alapvetően a tartalmas szavakra fókuszálunk. Ez azt jelenti, hogy amikor szövegeket alkotunk, kevésbé vagyunk megfontoltak a funkciószók használatát illetően; inkább a közölni kívánt szemantikai tartalomra, így szükségképpen elsősorban a tartalmas szavakra koncentrálunk. Ugyanakkor a kommunikációnk során a funkciószó-használatunkkal tudattalanul is olyan információkat közlünk magunkról, mint például a nemünk, a korunk, a szociális viszonyaink vagy az aktuális érzelmi állapotunk ‒ amelyeket esetleg egyáltalán nem is szerettünk volna a partner tudomására hozni. Pennebaker szerint tehát a funkciószó-használatunk az érzelmi állapotunkról is árulkodik, vagyis ezeknek a szöveges realizációja szorosan összefügg a beszélő emócióival.
 Ezzel együtt, amint arra a szerző felhívja a figyelmet, a 20 leggyakoribb előfordulású angol szó között kizárólag funkciószókat találunk, s pusztán ez a húsz elem megközelítőleg a 30%-át teszi ki az angol nyelvi produktumoknak, az írott és a beszélt nyelvet illetően egyaránt.
Ezzel együtt, amint arra a szerző felhívja a figyelmet, a 20 leggyakoribb előfordulású angol szó között kizárólag funkciószókat találunk, s pusztán ez a húsz elem megközelítőleg a 30%-át teszi ki az angol nyelvi produktumoknak, az írott és a beszélt nyelvet illetően egyaránt.
A kérdést a magyar nyelv vonatkozásában, a Magyar Nemzeti Szövegtár adatait megnézve hasonló eredményt kapunk: a 20 legyakoribb szó között a magyar nyelvet illetően is, akárcsak az angolban, rendre funkciószókat találunk.
A funkciószók vizsgálatától, különösen az emócióelemzéssel együtt alkalmazva igazán figyelemre méltó összefüggések feltárását remélhetjük.
Jelenleg tehát azon dolgozunk, hogy az orosz nyelvű korpuszunkban végrehajtsuk az emóciók, a funkciószók és a szentimentek komplex feldolgozását.




