[...] data is the next Intel Inside (Tim O'Reilly)
Sorozatunk előző részében bemutattuk a többé-kevésbé nyers adatokat kínáló DataMarket-et és az "anyacég"- az Infochimps - felhőszolgáltatásban kínált adatelemzési megoldásait. Mivel nem mindenki szeret maga bajlódni az adatok feldolgozásával, tisztításával és tárolásával, megjelentek az adatokat API-n (application programming interface, alkalmazás programozási interfész) keresztül rendszerezett formában elérhetővé tévő vállalkozások is a piacon. Most a legnagyobb és legérettebb játékost, a Factual-t, valamint a legígéretesebb feltörekvőt az Uberlic-et mutatjuk be.
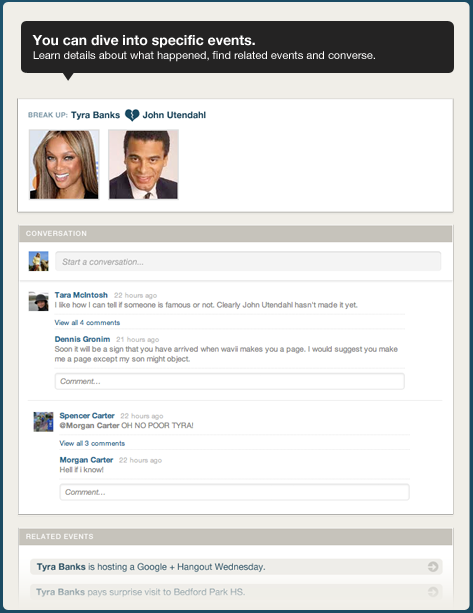
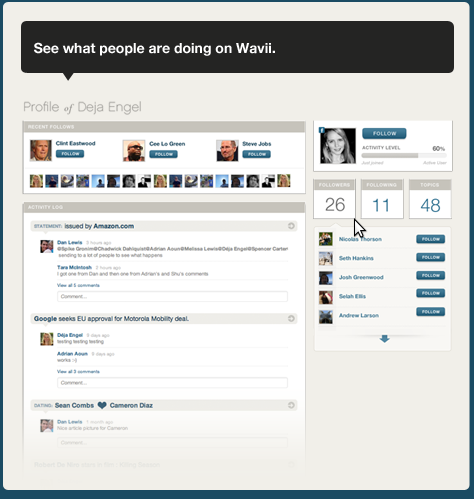
Szinte mindegy mivel foglalkozik egy honlap, nem árt ha "van adat mögötte". Egy KKV pl. alap esetben feltünteti elérhetőségét a céges honlapon, ami postacím, telefonszám, e-mail cím minimum. Ha indítunk egy a városunk kávézóit értékelő honlapot valahogy össze kell szedni melyik kávézó hol van, mikor van nyitva, milyen különlegességeket árul (illetve további érdekes adatokkal dobhatjuk fel az oldalt). Könnyen belátható hogy egy e-kereskedelmi oldal is sokat profitálhat, ha sikerül termékeiről további információkat gyűjtenie, de akár önálló szolgáltatások is alapozhatók bizonyos adatokra. Sokaknak van szüksége jó minőségű, könnyen használható adatokra, azonban ezek összegyűjtése és kezelése (data curation, adat gondozás) időigényes, összetett és nagyon drága dolog.
A Factual mögött a Google AdSense hirdetési platformját eredetileg kifejlesztő Applied Semantics ötletgazdája Gil Elbaz áll. Sokan próbáltak/próbálnak benyomulni az adatszolgáltatási piacra, de igazából eddig senkinek sem sikerült ez a Factual kivételével. Sikerük egyik titka, hogy olyan zseniális kutatókkal dolgoznak mint Tim Chklovski, illetve a kínai irodájukban található olcsón, de jól dolgozó magasan kvalifikált mérnökök hada. A hatékony működés lehetővé teszi, hogy külön figyelmet fordítsanak az egyes adathalmazok gondozására (data curation), ehhez nagy számban alkalmaznak ezen a téren járatos korpusznyelvészeket.
Az adathalmazok többsége ingyenesen elérhető. Az API felhasználóbarát, minimális webfejlesztési háttérismerettel (html és JavasScript) és egy kis gyakorlással bárki képes használni. Habár a cég nagyon sikeresen szervezett egy fejlesztői közösséget, új utakat is keres. Egyes adathalmazok szabadon letölthetőek, az igazán hasznosak és érdekesek pedig fizetség ellenében. Habár elindult a találgatás, hogy lehet mégsem jó üzleti modellt követett eddig a cég, a hivatalos közlemények szolgáltatásbővítésről szólnak és semmi nem utal arra hogy ezt megkérdőjelezzük.
Az Uberlic még csupán teszt üzemben működik és nem sokat tudunk róla, de máris a Factual ígéretes konkurenciájaként tartják számon. A berlini startup jelmondata - "One API to Link Them All" - jelzi hogy teljesen más oldaláról közelíti meg a problémát. Mivel a sok-sok adat valahol úgyis összegyűlik és előbb-utóbb valaki elérhetővé teszi "fogyasztható" formában, az Uberlic nem tesz mást mint ezeket összekapcsolja, így a felhasználónak nem kell külön-külön bajlódnia az egyes API-okkal, a cég pedig eltekinthet az adatgondozás terhétől.
Az Uberlic legnagyobb ígérete az, hogy az API-k összekapcsolása nem csak adatforrásokat jelent, hanem ügyesen építkezve megkereshetjük a számunkra ideális adatforrást, feldolgozhatjuk hogy kinyerjük belőle a kívánt információt, végül pedig ezt akár szépen meg is jeleníthetjük. Mindezt pedig úgy hogy saját eszközeinket minimálisan vesszük igénybe.