A hackathon keretében kísérletet tettünk a scikit-learn python package klasszifikációs eszközeinek felderítésére.
A scikit-learn lehetőséget ad arra, hogy egészen kevés kódolással gyorsan implementálhassunk gépi tanulási eszközöket pythonban. Jópár szövegklasszifikációra is alkalmas algoritmust tartalmaz, úgy mint naive bayes, maxent, SVM, decision tree, etc. A package használata viszonylag egyszerű a beépített vektorizáló függvényeknek köszönhetően, amik az adott korpusz nyers sztringjeit automatikusan az összes classifier számára emészthető formába tudják alakítani. A választott classifier ezután a kapott adat és a használt algoritmus alapján felépít egy modellt, amit újabb adatok automatikus klasszifikációjára lehet használni.
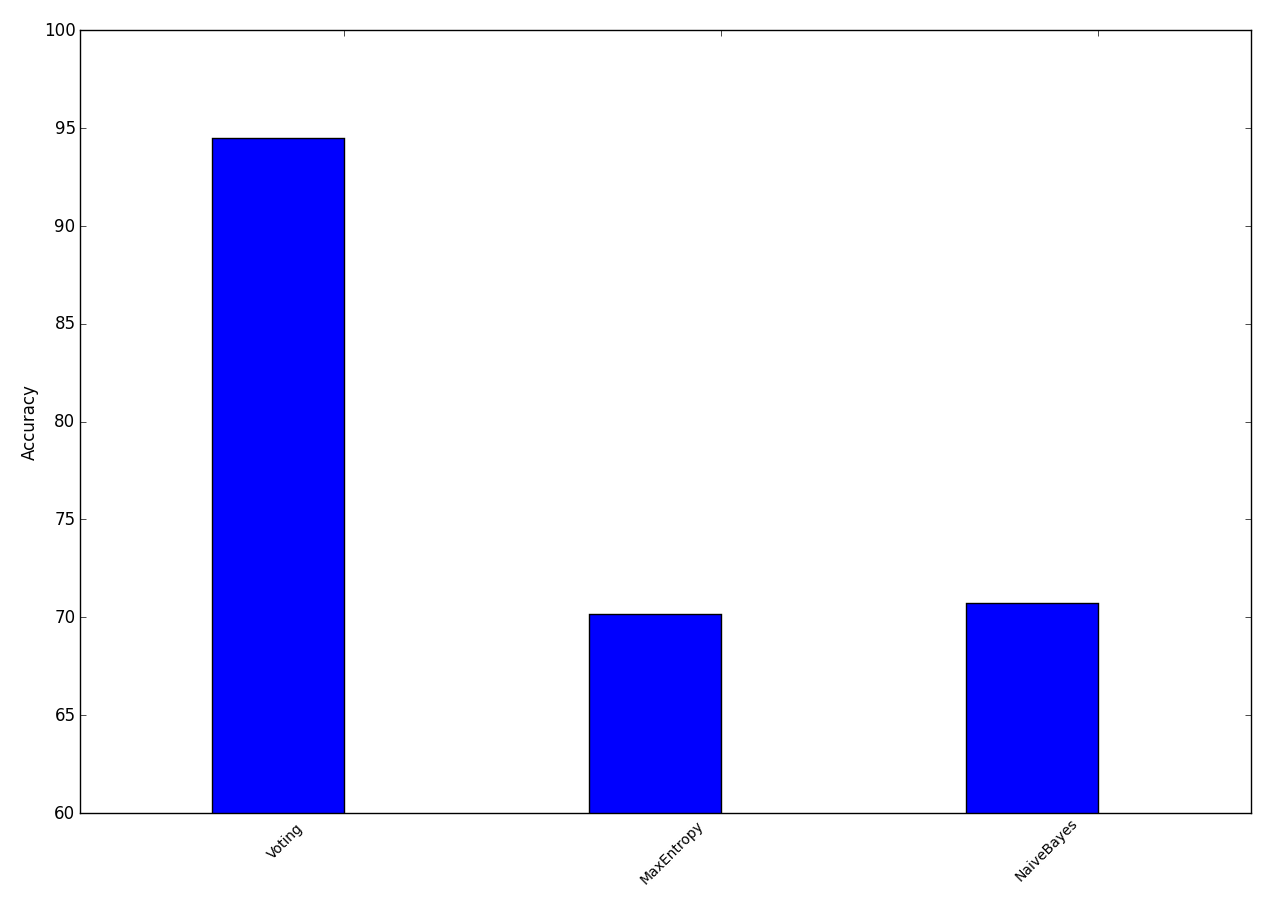
Mi a naive bayes és maximum entropy classifiereket használtuk, arra, hogy a korábban szentiment kalsszifikációhoz gyűjtött magyar twitter korpusz elemeit a posztolók neme szerint válogassuk szét. Ezután egy voter segítségével összegeztük az egyes classifierekből származó outputokat. Ez azért hasznos, mert az egyes algoritmusok más-más elven működnek, így más-más gyengeségeik és erősségeik vannak, viszont több különböző classifier használata esetén kiszűrhetjük a hibás klasszifikációkat, ha mindegyik classifier szavaz egy adott adatpontról, és a végleges outputot a szavazás eredménye határozza meg.
A kísérlethez a nyers korpuszt használtuk, minden előfeldolgozás nélkül, ami az egyes classifiereken meglepően jó, 65-70% körüli pontossággal állapította meg a tweetelők nemét. A voter használata ezt még kb. 25%-kal emelte.