A twitteren zajló kommunikációnak fontos kiegészítői az emotikonok, hiszen kevés karakterrel, viszonylag komplex, szavakkal nehezen megragadható jelentéstartalmakat lehet velük közvetíteni. Emiatt fontos szerepük lehet a tweetek automatizált feldolgozásában is, például ha érzelmi töltés szerint szeretnék klasszifikálni az egyes posztokat. De mégis milyen emotikonokat használnak a magyar twitterezők? Mielőtt megválaszolnánk ezt a kérdést, gyorsan tisztázzuk, hogy mi mindenre gondolhatunk, amikor emotikonokról beszélünk!

Az emotikonok (emotion + icon) valamilyen arckifejezés reprezentációi különböző betűkből és más írásjelekből felépítve. A nyugaton elterjedt emotikonok általában kilencven fokban elfordítva értelmezendők - pl :c vagy ;-) - és sok felületen automatikusan kis képekre, “emojik”-ra cserélődnek, amiknek külön unicode karakterek felelnek meg. Az emoji szó egyébként japán eredetű, és csak véletlenül hasonlít az emoticonra, eredetileg kb. “kép-karakter”-t jelent. A legtöbb emoji nem is hordoz különösebb érzelmi töltést.![]()
A keleti online kommunikáció szülöttei a “kaomoji”-k (kb. “arc-karakter”), amik elfordítás nélkül értelmezhetőek és általában sokkal több karakterből állnak, mint a nyugati emotikonok. A kaomojik szemantikai elemzése nem egyszerű feladat, mivel meglehetősen nagy teret engednek a felhasználók kreativitásának, és gyorsan fejlődnek. Egyelőre a nyugati online életben csak kevés honosodott meg, a magyar twitterezők pedig csak elvétve használnak kaomojikat, és akkor is csak egyszerűbbeket. (“⌒◞౪◟⌒”)/♫•*¨*•.¸¸♪
A twitter megjeleníti az emojikat, de egyik emoticont sem változatatja át automatikusan, ezért a felhasználók kedvükre váltogathatnak az emotikon típusok közt. Íme a 30 leggyakoribb emoji és nem-emoji emoticon, ~55000 magyar tweet alapján:

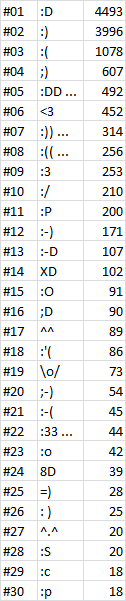
* (A számlálásnál azonosnak tekintettem azokat az emotikonokat, amiknek az utolsó karaktere kétszer, vagy annál többször szerepelt. Ezeket jelzi a három pont.)
Nagy korpuszok különös tulajdonsága, hogy a bennük előforduló szavak gyakorisága egy jellegzetes eloszlást követ. Függetlenül attól, hogy milyen nyelvet tekintünk, minden szó összes előfordulása fordítottan arányos azzal, hogy hányadik leggyakoribb a szó a korpuszban. Például a második leggyakoribb szó fele annyiszor fordul elő, mint az első, a tizedik leggyakoribb pedig tized annyiszor. A jelenséget Zipf-törvénynek, vagy Zipf-eloszlásnak nevezzük George Kingsley Zipf után, aki nyelvészként tevékenykedett a huszadik század elején. Zipf úgy vélte, ez a törvényszerűség valamilyen módon az emberi természetből fakad, de talán túlzás ezt feltételezni, mivel azóta számos más, kevésbé humán-spcifikus területen is megfigyelték. Többek között véletlenszerűen generált betűsalátákban.
De mi köze van mindennek az emotikonokhoz? A fenti két táblázatban látszik, hogy az egyes emotikonok gyakorisága ütemesen csökken, ahogy a sorszámok növekednek. Felmerül a kérdés, hogy itt is megfigyelhető-e Zipf-törvénye. A Zipf-eloszlást követő adatok egy log-log skálán jellemezően egy egyenes mentén rendeződenk. Valahogy így:
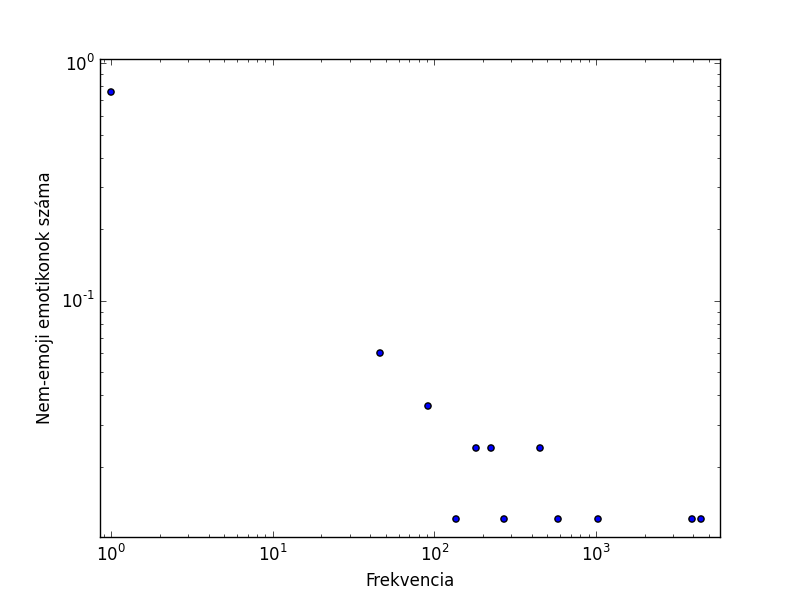

Az ábrákon az látható, hogy adott gyakoriság-oszályba tartozó emotikonok összesen hányszor fordultak elő, osztva az összes emotikon-előfordulással. Bár a pontok nem illeszkednek tökéletesen egy egyenesre, úgy tűnik az emotikonok gyakoriságeloszlása meglehetősen hasonlít a normál szavakéra.