A big data korában egyre gyakrabban halljuk, az adatok majd mindent megoldanak. A Google a cambridge-i egyetemmel összefogva elindította az Automatic Statistician projektet, ami azt célozza, hogy a hihetetlen adatmennyiségeket automatikusan feldolgozva találhassunk összefüggéseket. Úgy tűnik semmi dolgunk nem maradt, a technológiai megoldások átveszik a tudományos kutatás szerepét is, Chris Anderson jóslata az elméletek végéről hamarosan igazzá fog válni. Tényleg automatizálható a tudományos munka? Van technológiai megoldás a tudomány és az ipar területén keletkező adatok egyszerű és olcsó elemzésére? Gary King és társai a Google FluTrends adatait vizsgálva arra hívják fel a big data híveinek figyelmét, hogy a szép új világ bizony nagyon messze van még és a technológiai szolucionizmus helyett a jó öreg viselkedés - és társadalomtudományok módszertanához kell fordulnunk.
A Google Flu Trends a hype ellenére mellélő
A Google 2009-ben a Nature hasábjain megjelent tanulmányában mutatta be, hogy a keresési statisztikák influenza járvány előrejelzésében nagyon hasznosak lehetnek. A kutatás eredménye a Google Flu Trends , amely alapjaira épült a Google Correlate, a napjainkban divatos jelenbecslés (nowcasting) módszerek elindítója lett.
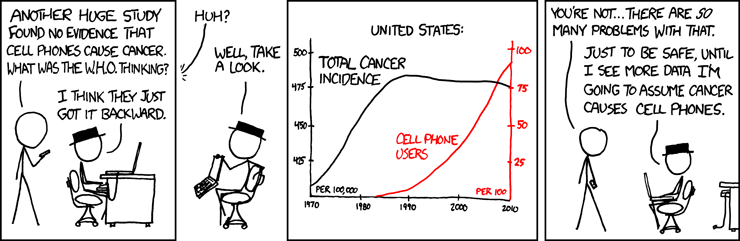
2014 legfontosabb tanulmánya a big data területén vitathatatlanul a Gary King és tsai nevéhez fűződő The Parable of Google Flu: Traps in Big Data Analysis. A rövid írás tkp. összefoglalható a benne közölt ábrával:
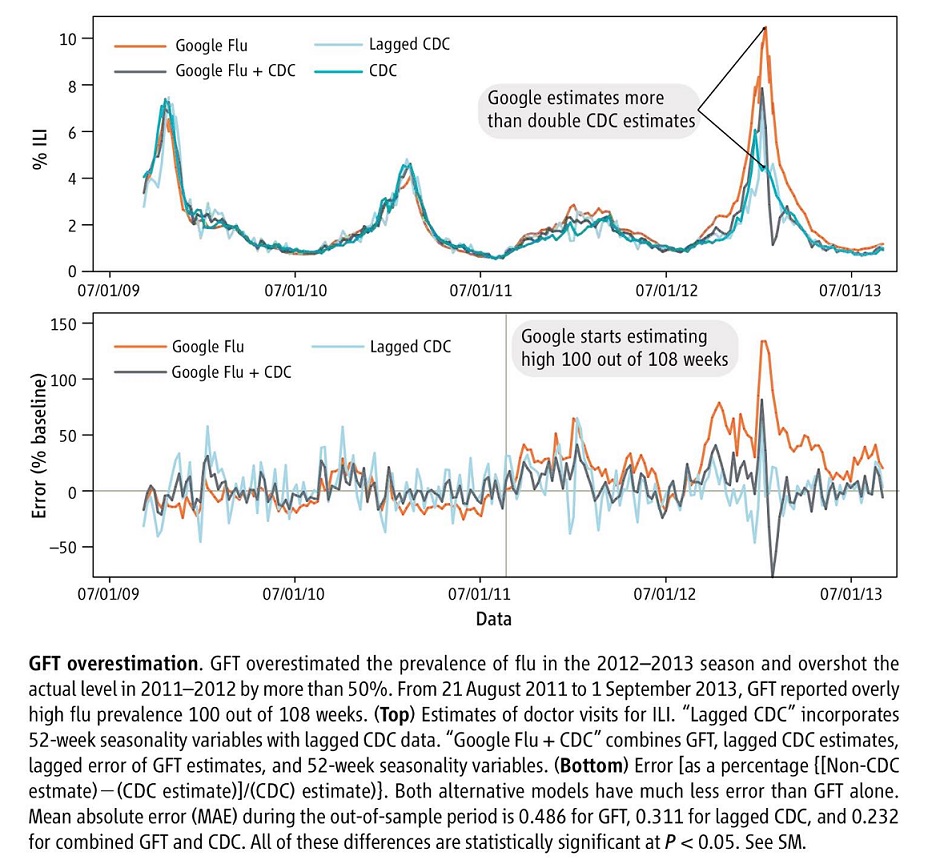
A fenti ábrán is láthatjuk, a Google Flu jelentősen túlbecsüli az influenza trendet, a hagyományos egészségügyi adatok sokkal jobbak (még akkor is, ha sokkal lassabb a beszerzésük). A legjobb azonban az, ha kombináljuk a keresési és a hagyományos adatokat! Hogy mi lehet ennek hátterében? A szerzők a big data felhasználásával kapcsolatban az alábbi problémákat említik:
- A Google algoritmusai változnak, az hogy mi számít releváns keresésnek, változik időben
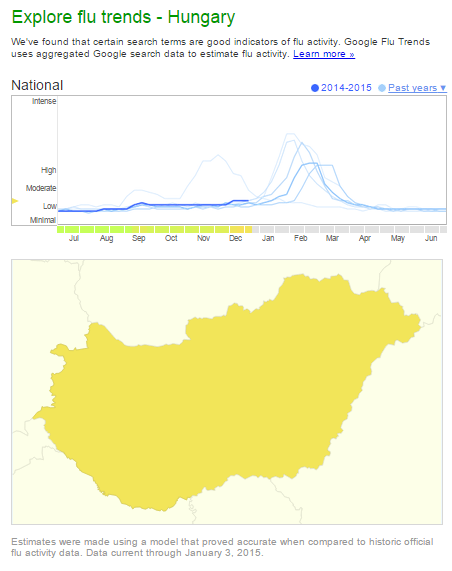
- A találatok megjelenítése is változik, a Google egyre inkább elmozdul a question answering irányába, a betegségekkel kapcsolatos keresések, gyakran a Knowledge Graph által "kibányászott" tényeket tartalmazó dobozt adják első találatnak (l. a lentebbi képet).
- További problémát jelent az, hogy az algoritmus változása hat a felhasználó viselkedésére. Ezt nevezik manapság a "name it they'll game it" elvnek.
- Automatikusan szimpla korrelációkat keresni érdekes feladat, nagyon hasznos eredményeket is adhat ez, de nem lehetünk biztosak abban, hogy a feltárt összefüggés mögött oksági kapcsolat van s a jövőben is fent fog állni ez.
- Először fordul elő a történelemben, hogy a privát szektorban több adat áll rendelkezésre mint a kormányzati és kutatóiban összesen. A privát szektor az adatokra mint erőforrásra tekint, nem áll érdekében (és gyakran jogilag sincs lehetősége) megosztani hogyan és milyen adatokat gyűjt.
Fontos megjegyezni, hogy King és tsai nem fikázzák le a Google Flu-t! Arra hívják fel a figyelmet, hogy annak alapvetően számítástudományi beállítottságú megalkotói elsiklottak metodológiai kérdések felett. Továbbá rávilágítanak arra, hogy a big data mellett az ún. small data és az adathalmazok összekapcsolása jelenti az igazán forradalmi lehetőséget.
Minden összefügg mindennel
A keresők, de az egész internet világa alapvetően ember alkotta dolgok. Pontosan ezért alkalmasak, ha csak behatároltan is, a társadalmi jelenségek vizsgálatára. Azonban ha emberekkel van dolgunk, akkor egy különös világba csöppenünk, amit Soros reflexivitás fogalma jellemez a legjobban.
The concept of reflexivity needs a little more explication. It applies exclusively to situations that have thinking participants. The participants’ thinking serves two functions. One is to understand the world in which we live; I call this the cognitive function. The other is to change the situation to our advantage. I call this the participating or manipulative function. The two functions connect thinking and reality in opposite directions. In the cognitive function, reality is supposed to determine the participants’ views; the direction of causation is from the world to the mind. By contrast, in the manipulative function, the direction of causation is from the mind to the world, that is to say, the intentions of the participants have an effect on the world. When both functions operate at the same time they can interfere with each other.
How? By depriving each function of the independent variable that would be needed to determine the value of the dependent variable. Because, when the independent variable of one function is the dependent variable of the other, neither function has a genuinely independent variable. This means that the cognitive function can’t produce enough knowledge to serve as the basis of the participants’ decisions. Similarly, the manipulative function can have an effect on the outcome, but can’t determine it. In other words, the outcome is liable to diverge from the participants’ intentions. There is bound to be some slippage between intentions and actions and further slippage between actions and outcomes. As a result, there is an element of uncertainty both in our understanding of reality and in the actual course of events. (George Soros: The General Theory of Reflexivity)
Az internet világában folyamatos változásban vagyunk! Adatokat gyűjtünk, hogy jobbá tegyük meglévő rendszerünket. A megváltozott rendszer nyilván visszahat a felhasználókra is, ahogy Kingék is kimutatták a Google Flu esetében. A reflexivitás világában élünk!
Mind társadalomtudósok vagyunk!
Justin Grimmer We're All Social Scientists Now: How Big Data, Machine Learning and Causal Inference Work Together című tanulmányában amellett érvel, hogy a a big data fantasztikus technikai lehetőségeket teremtette, de a technológiával elemezhető kérdések értelmes vizsgálatához a társadalomtudományok eszköztárára van szükség. Nem is annyira meglepő ez, hiszen az iparban általában felhasználókról és ügyfelekről, azaz emberekről szóló adatokkal foglalkozunk. Nem arról van szó, hogy ki kell rúgni minden programozót! Sokkal inkább arról, hogy a technológia nyújtotta lehetőségek kiaknázásához sokszínű csapatra van szükség.
Hogy állunk ezzel mi?

King és társai tanulmányát olvasva alapvetően megnyugodtam. A Jobmonitor keresési adataira alapozott jelenbecsléses vizsgálataink során mi is a kevert modelleket (a hivatalos statisztikák, a GoogleTrends és a Jobmonitor logok adatainak mixelése ez esetünkben) találtuk a legjobbnak (erről a májusi meetupon számolt be kollégánk). De nem önmagában az eredmény nyugtatott meg, hanem az, hogy kis csapatunkban pont a megfelelő mixben vannak szakemberek. Egy IT cégnél nem meglepő, hogy vannak szép számmal programozóink, de az sem annyira egzotikus, hogy akadnak nálunk alkalmazott fizikusok. A kutatóink viszont legalább két területen vannak otthon a nyelvészet, filozófia (nem kell meglepődni, a logika nagyon jól jön a szemantikus technológiáknál!) a szociológia és a statisztika tudományaiban. Nem mellesleg kutató kollégáink az informatikában sem elveszettek!