



A legtöbb dialektológiai kutatás sajnos nagyon kevés adatközlővel készült/készül, de szerencsére napjainkban a technológiának hála akár 50 millió (!) beszélőtől is lehet adatokat beszerezni, ahogyan Bruno Gonçalves David Sánchez Crowdsourcing Dialect Characterization through Twitter című tanulmányukban arról beszámoltak.
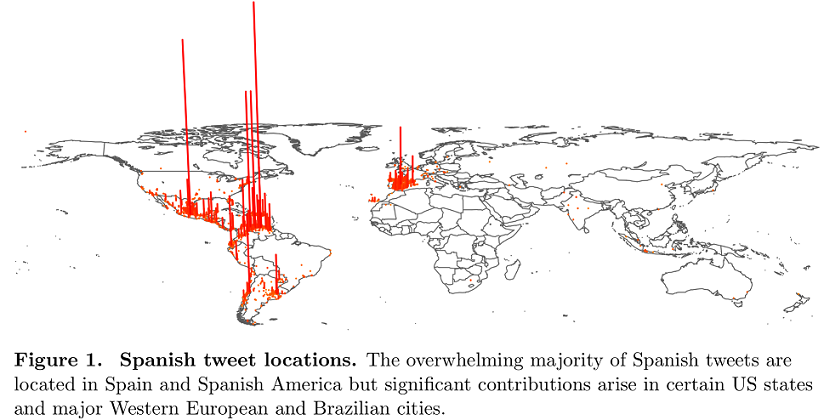
A kutatók az elmúlt két esztendő spanyol nyelvű, geolokációs meta-adatokkal ellátott tweetjeit elemezte. Az adatok földrajzi eloszlását mutatja be a fenti ábra. A kutatók elgondolása szerint a közösségi média nyelvhasználata közel áll a mindennapi beszélt nyelvhez, ezért alkalmas lehet a dialektusok tanulmányozására is (bővebben l. Milyen is az internet nyelve c. korábbi posztunkat).
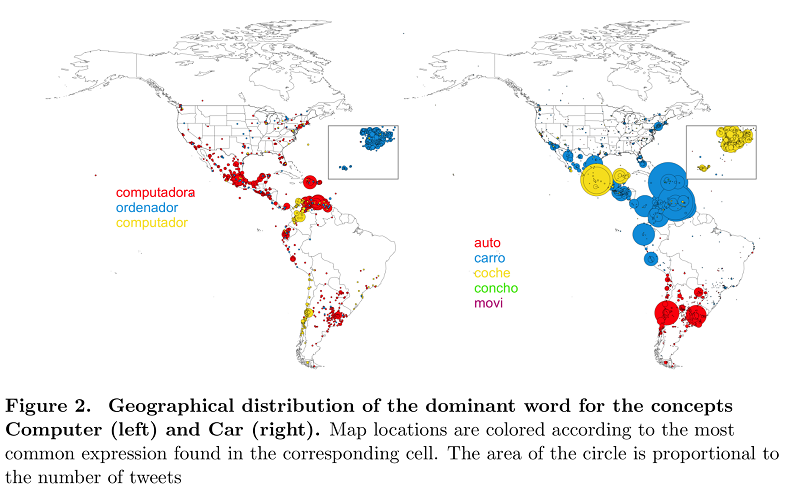
A kutatás egyik részében a hagyományos kutatásokat felhasználva a szókincsbeli eltéréseket vizsgálták. Majd következett a gépi tanulás bevetése.
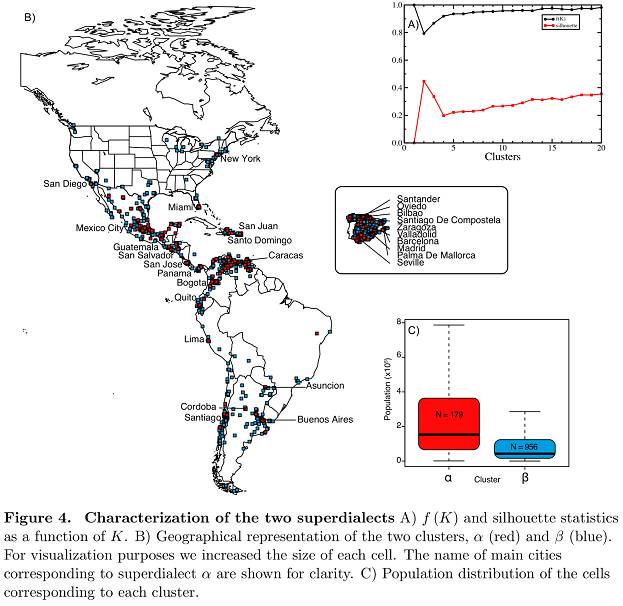
Ötvenmillió tweet csak egy nagyon, de nagyon nagy dokumentum mátrixba fér bele, aminek sok-sok dimenziója lesz, ezért főkomponens-elemzéssel szépen leredukálták azt. Ezután jöhetett a klasszifikáció legegyszerűbb módszere, a k-NN. Ennek eredménye két szuper-dialektus lett, az egyik a nagyvárosokra jellemző szóhasználat, a másik pedig a vidékiek spanyolja - mindez kontinensektől függetlenül!
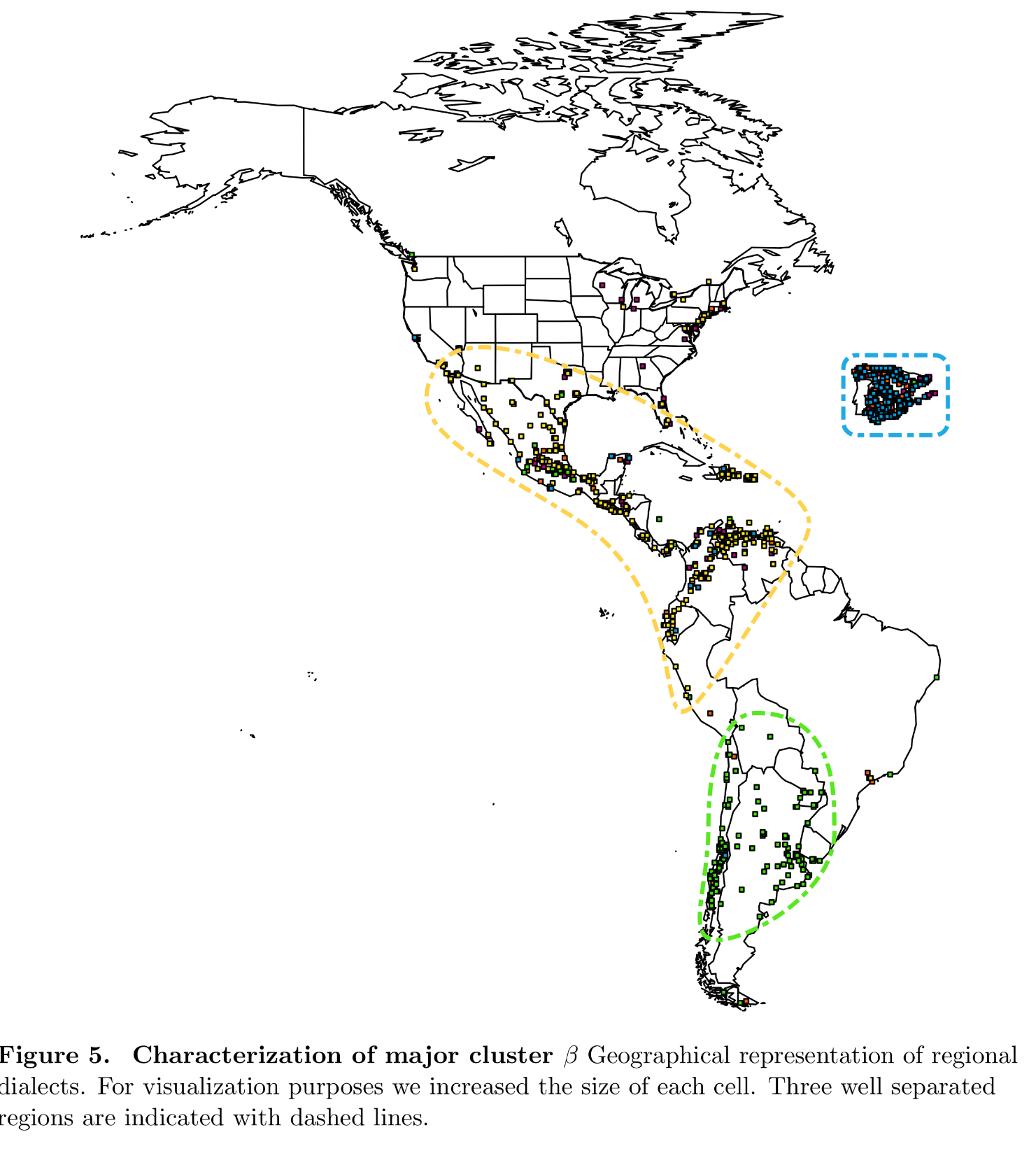
A vidéki spanyolt tovább vizsgálva pedig a klasszikus dialektológia által leírt főbb nyelvjárások képe rajzolódik ki, miképp a fenti ábra is mutatja.
A "Big Data" lassan olyan területeket is elér, ahol úgy gondolnánk nem sok keresnivalója akad. Kíváncsian várjuk a következő érdekes bevetését!




