A legtöbb mai szentimentelemző rendszer valahol a 80%-os pontosság környékén mozog manapság, ami nem rossz, de "van hely a javulásra". A Stanford Deeply Moving: Deep Learning for Sentiment Analysis projektje 85% felé viszi a pontosságot a deep learning bevetésével, érdemes egy kicsit közelebbről is megvizsgálni módszerüket.
A jelenleg elérhető szentimentelemző megoldások vagy valamilyen klasszifikációs (általában bayesiánus) megoldást használnak, vagy pedig szótárakat vetnek be. Mindkét irányzat figyelmen kívül hagyja a nyelvtani szerkezetet. A szótári módszernél manapság egyre gyakrabban vetik be az ún. shiftereket, azaz a módosítók (pl. negáció) figyelését is, de ez ritkán lép túl a pár soros szóláncokon. Továbbra is komoly gondot jelent a szentiment tárgyának azonosítása, az irónia és a metaforák kezelése. Úgy tűnik, ezen problémák megoldásához a nyelvtani szerkezet, sőt a szemantika vizsgálata is elengedhetetlen.
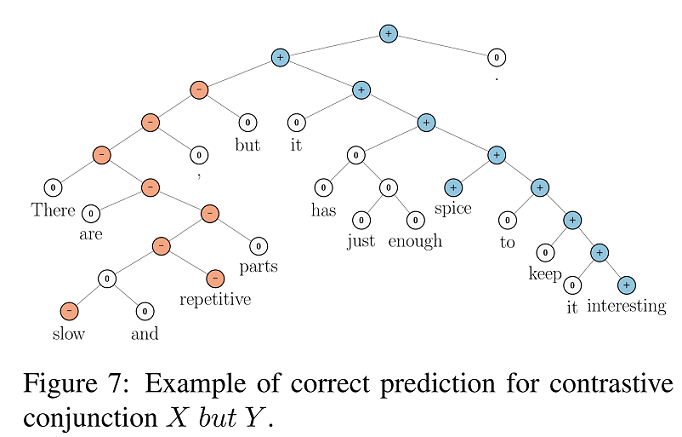
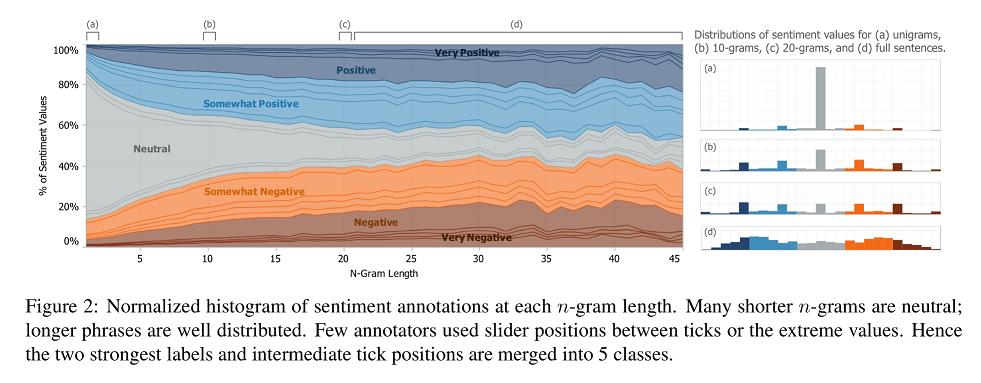
A stanfordi kutatók abból indulnak ki, hogy a nyelv kompozícionális, azaz egy kijelentés jelentése függ tagjainak jelentésétől és az összetétel módjától. Ezért megoldásuk a mondatok szerkezeti szinten történő szentimentelemzésére épít. A Rotten Tomatoes mozi kritikákat tartalmazó adatbázisát dolgozták fel annotátorok segítségével. Az egyes mondatokat a Stanford CoreNLP-vel parsolták (szintaktikailag elemezték) és a Mechanical Turk-ön toborzott felhasználók segítségével az elemzési fák egyes elemeihez szentimentértékeket rendeltek. Érdekes, hogy a mondatrészek hosszának növekedésével csökken a neutrális elemek száma, illetve a szélsőséges (nagyon pozitív, nagyon negatív) értékek aránya minden hossz esetében viszonylag alacsony.
A szentimentértékekkel annotált treebank (azaz a szintaktikailag elemzett és szentimentinformációval is felcímkézett mondatok halmaza) tréningadatul szolgált több gépi tanulási algoritmusnak. Az ún. recursive neural tensor network (egy, a neurális hálókból származtatott eljárás) lett a legjobb ezek közül, ami az ötfokú szentimentelemzési feladatokban 80, a pozitív-negatív besorlás során 85.4 százalékos pontosságú eredményeket produkált.
Az eredmények tükrében úgy tűnik, a nyelvtechnológiába is megérkezett a deep learning! A magyar deep learner szentimentelemzők hivatalos dala pedig ez lesz: