



A keresőgépekkel kapcsolatos leggyakoribb szakkifejezések (pl. search engine, crawler, page rank, deep web) a tananyag előző részeiben találhatók. Az alábbiakban néhány olyan angol nyelvű fogalom és rövidítés magyarázata olvasható, amelyek a kereséshez kapcsolódnak és a keresőfelületeken illetve a szakirodalomban szintén elő szoktak fordulni:
(A szerk. megjegyzése: a példaként mellékelt képek nagyobb méretben megtekinthetők a jobb egérgombbal való rákattintással, a megjelenő fülön a "Kép megjelenítése" opció kiválasztásával!)
- query/search expression (kérdés/keresőkifejezés): Egy vagy több szót/karaktercsoportot tartalmazó utasítás a keresőrendszer számára, amely tartalmazhat még - a szavak közötti kapcsolatot jelző - műveleti jeleket is, továbbá lehetnek benne helyettesítő karakterek és a rendszer által biztosított különféle szűrőfeltételek.
- Boolean operators (Boole-operátorok/logikai műveletek): Egy 19. sz. angol
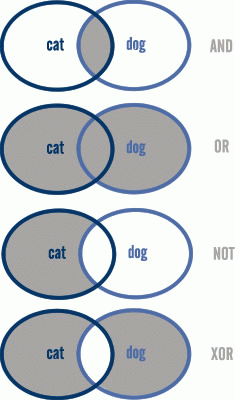 matematikusról elnevezetett műveleti jelek, melyekkel a találati halmazok közötti kapcsolatokat határozhatjuk meg: ezeket az AND/ÉS/+, OR/VAGY, XOR, NOT/AND NOT/NEM/- szavak ill. jelek jelölhetik. Az XOR (kizáró VAGY) műveletet nem sok keresőrendszer ismeri. Az OR művelet alacsonyabb prioritású, így ha szinonima-csoportok közt akarunk AND vagy NOT műveletet végezni, akkor előbbieket zárójelbe kell tenni, hogy megfelelő sorrendben történjen a kifejezés kiértékelése: a (panda OR koala) AND (mackó OR maci OR medve) kifejezés találati halmaza más és jóval kisebb lesz, mint a panda OR koala AND mackó OR maci OR medve. A NOT művelet pedig sorrendfüggő: a panda NOT mackó egész más találatokat ad, mint a mackó NOT panda. Egyes rendszerek megkívánják, hogy nagybetűvel írjuk az operátorokat (így különböztetve meg őket a stopword-öktől), illetve azt is, hogy amennyiben matematikai jeleket használunk, akkor a + illetve - jelek után ne írjunk szóközt. (Megjegyzendő még, hogy a Google esetében a szóköz nélküli + jel a keresett szó pontos egyezését írja elő: a "magyar +korkép" és a "magyar +kórkép" kifejezések így egész más találatokat adnak, mint a "magyar korkép".)
matematikusról elnevezetett műveleti jelek, melyekkel a találati halmazok közötti kapcsolatokat határozhatjuk meg: ezeket az AND/ÉS/+, OR/VAGY, XOR, NOT/AND NOT/NEM/- szavak ill. jelek jelölhetik. Az XOR (kizáró VAGY) műveletet nem sok keresőrendszer ismeri. Az OR művelet alacsonyabb prioritású, így ha szinonima-csoportok közt akarunk AND vagy NOT műveletet végezni, akkor előbbieket zárójelbe kell tenni, hogy megfelelő sorrendben történjen a kifejezés kiértékelése: a (panda OR koala) AND (mackó OR maci OR medve) kifejezés találati halmaza más és jóval kisebb lesz, mint a panda OR koala AND mackó OR maci OR medve. A NOT művelet pedig sorrendfüggő: a panda NOT mackó egész más találatokat ad, mint a mackó NOT panda. Egyes rendszerek megkívánják, hogy nagybetűvel írjuk az operátorokat (így különböztetve meg őket a stopword-öktől), illetve azt is, hogy amennyiben matematikai jeleket használunk, akkor a + illetve - jelek után ne írjunk szóközt. (Megjegyzendő még, hogy a Google esetében a szóköz nélküli + jel a keresett szó pontos egyezését írja elő: a "magyar +korkép" és a "magyar +kórkép" kifejezések így egész más találatokat adnak, mint a "magyar korkép".)
- proximity operators (közelségi operátorok): A keresőkifejezésben levő szavak megengedett távolságát határozhatjuk meg velük. Általában a WITH/W és a NEAR/N operátorokat használják - előbbi rendszerint az azonos bekezdésben, utóbbi az azonos mondatban való előfordulást írja elő. Az operátor elé vagy után (zárójelben vagy közvetlenül) tett számmal konkrét maximális távolságot is előírhatunk. Nem minden keresőrendszer ismeri ezeket, és az is változó, hogy ezek az operátorok a szavak sorrendjét is előírják vagy sem. Ha egymás melletti és adott sorrendben levő szavakból álló kifejezést keresünk, akkor idézőjelek közé kell írni őket (phrase searching), ahogy a fenti Google-példában is.
- prefix/suffix (előtag/utótag): A keresett szavak vagy adatok elé (rendszerint : vagy = jellel) vagy után (rendszerint / jellel) írt mezőnév vagy egyéb betűcsoport, amellyel adott mezőre korlátozhatjuk a keresést, vagy egyéb szűrési feltételt írhatunk elő. Pl. az archive.org-nál: title:révai AND mediatype:Texts AND collection:toronto
- fuzzy matching (hibatűrő keresés/illeszkedés): Olyan algoritmus, amely gépelési illetve felismerési hibák ellenére is megtalálja az egyező szavakat a keresőkérdésben és az adatbázisban. Más értelemben pedig a hasonló szóalakokat (pl. többes szám, ragozott forma, szinonima) is megtaláló keresési módot hívják így. Gyakran a ~ jelet használják operátorként erre a célra, és esetleg egy utána írt számmal az illeszkedés pontosságát is előírhatja a felhasználó. Nem minden keresőnyelvben van fuzzy utasítás, illetve van, ahol a keresőrendszer alapállapotban így működik (pl. a Google) és csak " vagy + jellel lehet csak pontos illeszkedést előírni. Pl. az archive.org-nál a title:család~ AND mediatype:texts keresőkifejezés megtalálja a családi, csalás, salad, salud, call'd stb. szavakat tartalmazó könyvcímeket is.
- truncation, wildcards (csonkolás, helyettesítő/joker karakterek): A beírt keresőszó elejének vagy végének (u.n. balról ill. jobbról való csonkolás), illetve a szó belsejében egy vagy több karakter helyettesítésére szolgáló jelek (pl. *, ?, %, $). Rendszerint a * tetszőleges számú karaktert helyettesít, a ? pedig egyet (ez utóbbi néhol ismételhető is), pl. creator:sz?c??n*
- stopwords (tiltott szavak): Olyan szavak vagy egyéb karakterek, amelyeket a keresőrendszer nem vesz figyelembe a keresőkifejezés kiértékelésekor (vagy csak akkor, ha külön kényszerítjük rá a + vagy " jellel). Rendszerint a névelők és kötőszavak (továbbá esetleg egyéb rövid, 1-3 betűs szavak), valamint az írásjelek és speciális jelek tartoznak ide, amelyek túl kevés információt hordoznak vagy túl gyakoriak, így a tárolásuk vagy a visszakeresésük fölöslegesen terhelné a rendszert.
- natural language processing (NLP) (természetes nyelv feldolgozás): Az emberi nyelvek gépi feldolgozásával, értelmezésével foglalkozó szakterület. Ennek eredményeként egyes keresőrendszerek képesek kielemezni a hétköznapi nyelven beírt mondatokat, és a kulcsszavakat kiemelve és keresőkérdéssé alakítva releváns találatokat adni. Ilyen például az Ask.com: Who were the presidents in the USA in the 1960s?
- query expansion (QE) (keresés kiegészítés/kiterjesztés): Az eredeti keresőkérdés kibővítése, továbbfejlesztése akár a felhasználó, akár a keresőrendszer részéről, hogy pontosabb vagy több találatot eredményezzen a keresés. Egyes keresőrendszerek kérésre vagy automatikusan átsúlyozzák az eredeti kérdésben szereplő kulcsszavakat, ragozott/képzett/összetett formában is lekeresik őket, illetve azok szinonimáit vagy kapcsolódó fogalmait.
- selection-based search (kijelölésen alapuló keresés): Olyan alkalmazás-kiegészítés, amely lehetővé teszi, hogy a felhasználó az egérrel kijelölt szót vagy kifejezést egy-két kattintással lekeresse különböző
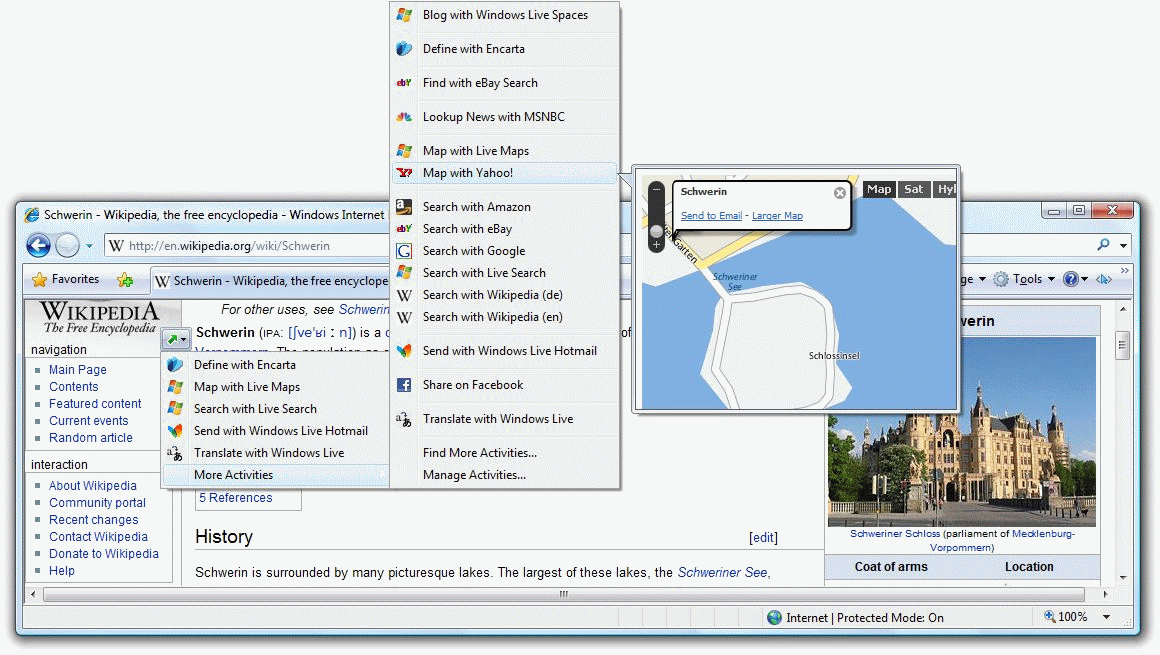 keresőgépek és más források (pl. Wikipédia, Google Maps, IMDB, Encarta, Amazon) adatbázisaiban. Így ha a munkája - pl. egy Word dokumentum olvasása vagy egy weblap böngészése - során szüksége van egy szó definíciójára, egy földrajzi hely térképére, valamilyen adatra egy filmmel vagy könyvvel kapcsolatban stb., akkor nem szükséges egy új ablakot nyitnia, elvándorolni valamelyik keresőoldalra, oda beírni vagy bemásolni a keresett szavakat, majd a találati lista átnézése után visszatérnie az eredeti dokumentumhoz. Ehelyett a program automatikusan felkínálja (egy szemantikus adatbázis alapján) a szerinte az adott esetben leghasznosabb információforrásokat, majd lefuttatja a keresést, az eredményeket rendszerezi, és egy lebegő ablakban megmutatja a szó eredeti szövegkörnyezete mellett, így a felhasználónak nem kell emiatt hosszasan félbeszakítania az olvasást. Ilyen szolgáltatás például az Internet Explorer 8-as verziójába épített Accelerator.
keresőgépek és más források (pl. Wikipédia, Google Maps, IMDB, Encarta, Amazon) adatbázisaiban. Így ha a munkája - pl. egy Word dokumentum olvasása vagy egy weblap böngészése - során szüksége van egy szó definíciójára, egy földrajzi hely térképére, valamilyen adatra egy filmmel vagy könyvvel kapcsolatban stb., akkor nem szükséges egy új ablakot nyitnia, elvándorolni valamelyik keresőoldalra, oda beírni vagy bemásolni a keresett szavakat, majd a találati lista átnézése után visszatérnie az eredeti dokumentumhoz. Ehelyett a program automatikusan felkínálja (egy szemantikus adatbázis alapján) a szerinte az adott esetben leghasznosabb információforrásokat, majd lefuttatja a keresést, az eredményeket rendszerezi, és egy lebegő ablakban megmutatja a szó eredeti szövegkörnyezete mellett, így a felhasználónak nem kell emiatt hosszasan félbeszakítania az olvasást. Ilyen szolgáltatás például az Internet Explorer 8-as verziójába épített Accelerator.
- federated search (közös/kiterjesztett/összevont keresés): Több webes (esetleg mélywebes) forrásban való egyidejű keresés, melynek során a keresőszoftver a keresőkifejezést átalakítja a lekérdezendő információforrások saját nyelvére, továbbítja azt a keresőrendszerekhez, összefésüli a kapott találatokat, majd megjeleníti őket egységes és áttekinthető formában, és esetleg még arra is lehetőséget ad, hogy a felhasználó tovább rendezze, válogassa a találati listát. Ilyen közös keresési lehetőséget nyújt például a WorldWideScience.
- faceted search (irányított/facettás/több kategóriás keresés): Ez a fajta keresési
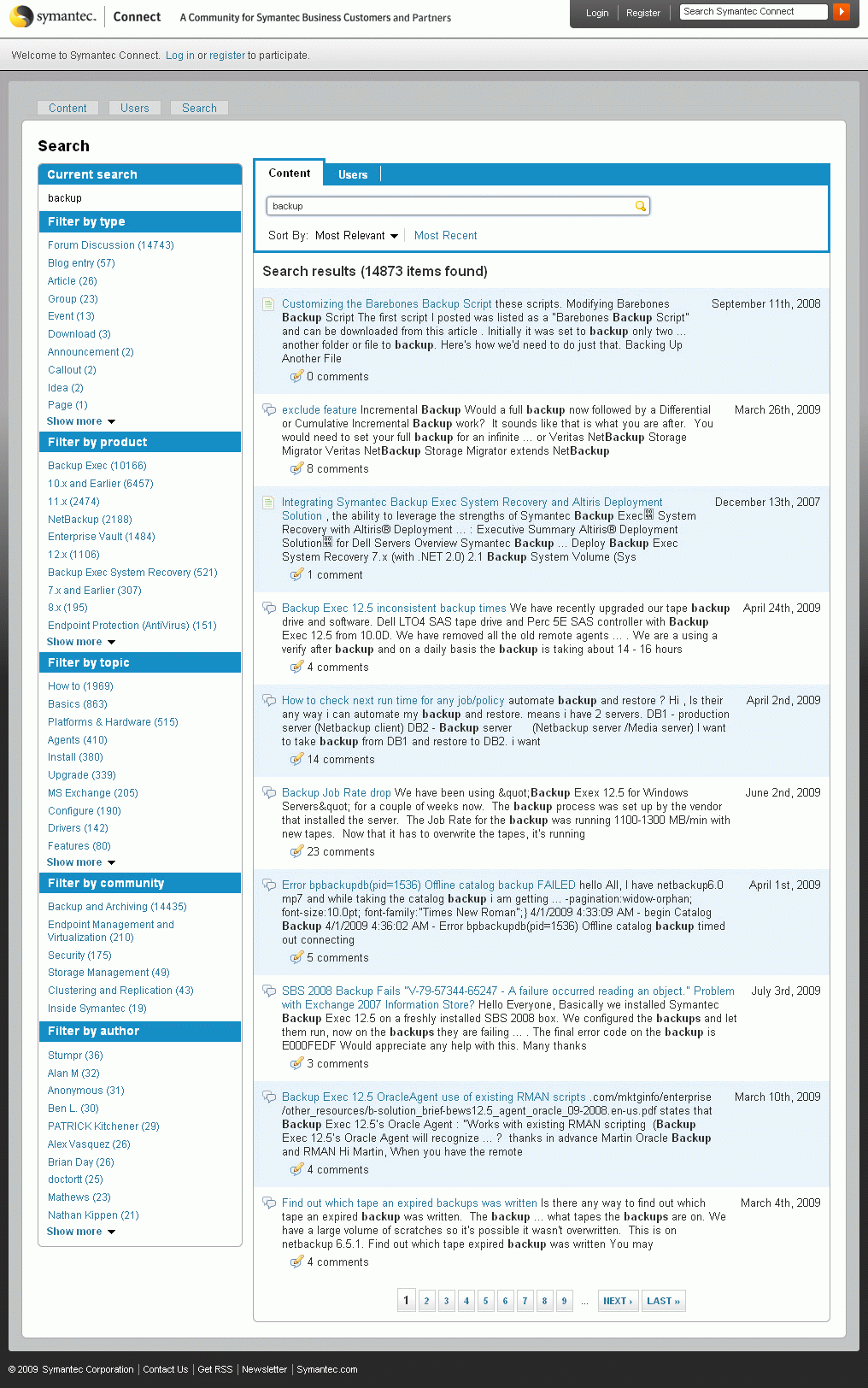 mechanizmus a szabad szavas keresés és a tematikus böngészés előnyeit egyesíti. A felhasználó az általa beírt keresőkérdésre érkező találatokat többféle kategóriarendszer szerint nézheti, szűrheti és sorrendezheti. Minden ilyen facet a találatok valamely közös tulajdonságán alapul (pl. egy termékre való keresésnél ilyen közös jellemzők: típus, ár, gyártó, forgalmazó).
mechanizmus a szabad szavas keresés és a tematikus böngészés előnyeit egyesíti. A felhasználó az általa beírt keresőkérdésre érkező találatokat többféle kategóriarendszer szerint nézheti, szűrheti és sorrendezheti. Minden ilyen facet a találatok valamely közös tulajdonságán alapul (pl. egy termékre való keresésnél ilyen közös jellemzők: típus, ár, gyártó, forgalmazó).
- clustering (klaszterezés/csoportosítás): A találati halmaz kisebb csoportokba való
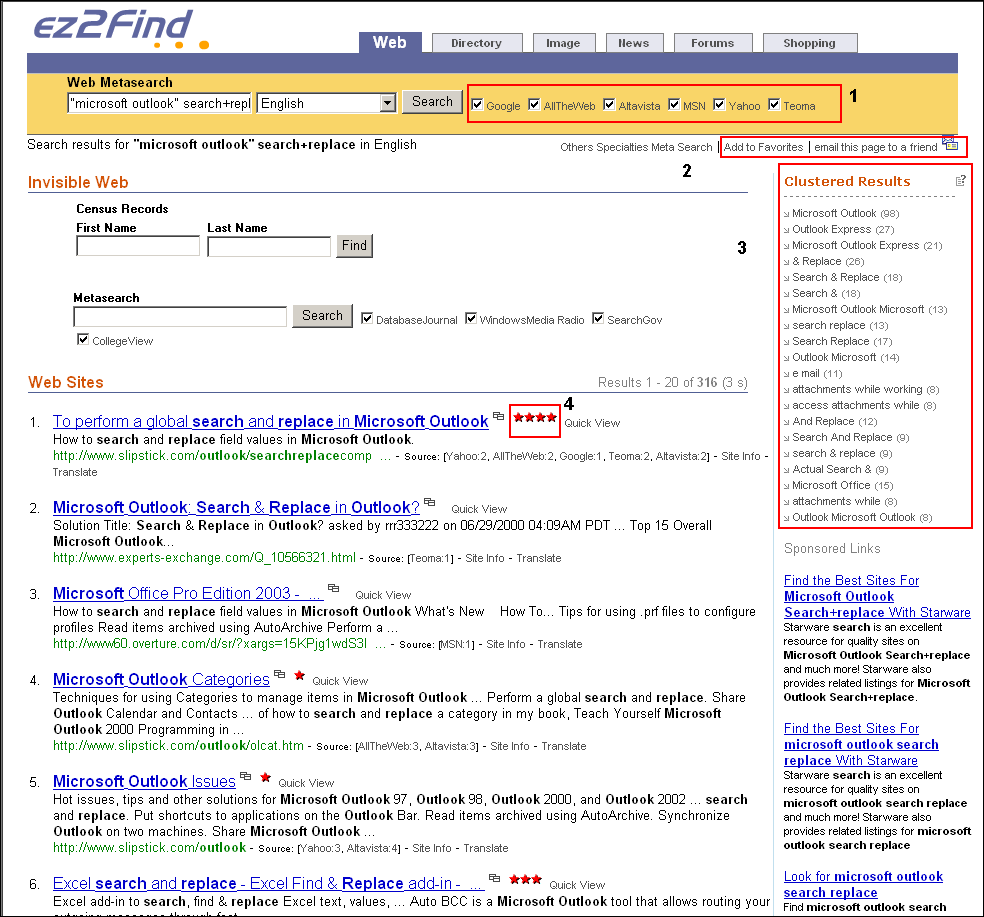 automatikus szétválogatása hasonló tartalom vagy valamilyen egyéb szempont (pl. a találatok forrása vagy típusa) alapján. A klaszterező keresők különösen a többértelmű szavak szétválasztásához vagy egy átfogóbb fogalom szűkítéséhez hasznosak, mert felajánlják azokat a részhalmazokat, amelyekkel a felhasználó a kívánt irányba tudja pontosítani a találati listát. Pl. egész más irányban kell továbbmenni a smart windows keresőkérdés után, ha az alkalmazkodó fényáteresztő-képességű ablakok érdekelnek, mint ha az okostelefonokon futó Windows rendszerek.
automatikus szétválogatása hasonló tartalom vagy valamilyen egyéb szempont (pl. a találatok forrása vagy típusa) alapján. A klaszterező keresők különösen a többértelmű szavak szétválasztásához vagy egy átfogóbb fogalom szűkítéséhez hasznosak, mert felajánlják azokat a részhalmazokat, amelyekkel a felhasználó a kívánt irányba tudja pontosítani a találati listát. Pl. egész más irányban kell továbbmenni a smart windows keresőkérdés után, ha az alkalmazkodó fényáteresztő-képességű ablakok érdekelnek, mint ha az okostelefonokon futó Windows rendszerek.
- search engine results page (SERP) (találati lista/keresési eredmények): Egy
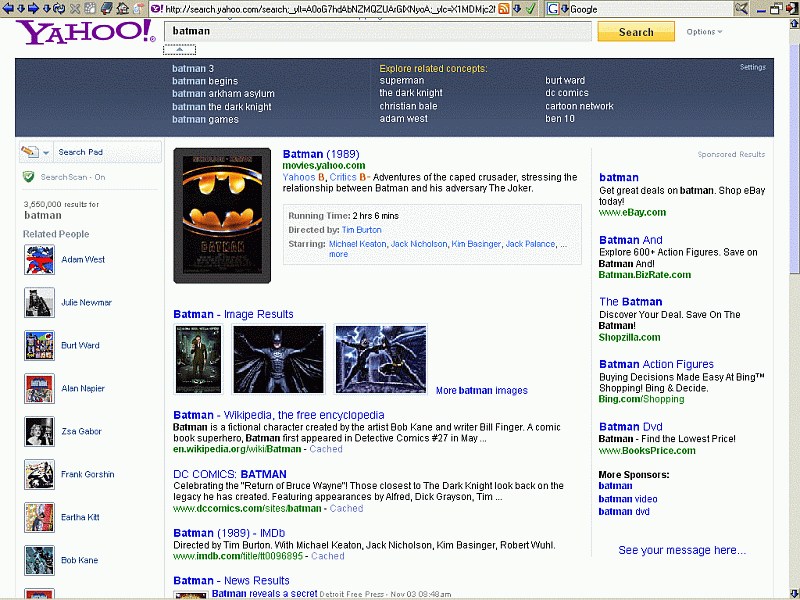 keresőgép által egy adott kérdésre visszaadott weboldal lista, mely rendszerint az egyes weblapok címét, a rájuk mutató linket és egy-egy rövid kivonatot tartalmaz a keresőszavak előfordulási helyét mutatva. Ezenkívül további információk is lehetnek a listában, pl. a találatok (hits) száma, a dokumentumok típusa, mérete, begyűjtési vagy módosítási dátuma, valamint képek/képernyőfotók, fizetett reklámok/linkek, és javasolt egyéb keresőkifejezések. Egyes keresőgépek egy átmeneti gyorstárolóba (cache) teszik a gyakoribb kérdésekre adott találati listákat és ismételt keresésnél onnan küldik el, így azok nem mindig a legfrissebb eredményeket tükrözik.
keresőgép által egy adott kérdésre visszaadott weboldal lista, mely rendszerint az egyes weblapok címét, a rájuk mutató linket és egy-egy rövid kivonatot tartalmaz a keresőszavak előfordulási helyét mutatva. Ezenkívül további információk is lehetnek a listában, pl. a találatok (hits) száma, a dokumentumok típusa, mérete, begyűjtési vagy módosítási dátuma, valamint képek/képernyőfotók, fizetett reklámok/linkek, és javasolt egyéb keresőkifejezések. Egyes keresőgépek egy átmeneti gyorstárolóba (cache) teszik a gyakoribb kérdésekre adott találati listákat és ismételt keresésnél onnan küldik el, így azok nem mindig a legfrissebb eredményeket tükrözik.
- relevance (relevancia/fontosság): A keresőgépek különféle, néha egészen kifinomult algoritmusok alapján igyekeznek rangsorolni a találatokat és meghatározni, hogy egy adott kérdésre melyik találat mennyire releváns, majd a legjobbakat előre helyezik a rangsorban. A gép által megállapított relevancia persze a legritkább esetben egyezik a felhasználó preferenciájával, mert őt például befolyásolják az előzetes ismeretei, vagy olyan további - esetleg teljesen szubjektív - szempontok, amelyeket nem írt bele a keresőkérdésbe (pl. egy napi hírre keresve csak a számára szimpatikus politikai irányzatú média érdekli).
- vertical search (vertikális/mélységi keresés): A horizontális, minden irányú
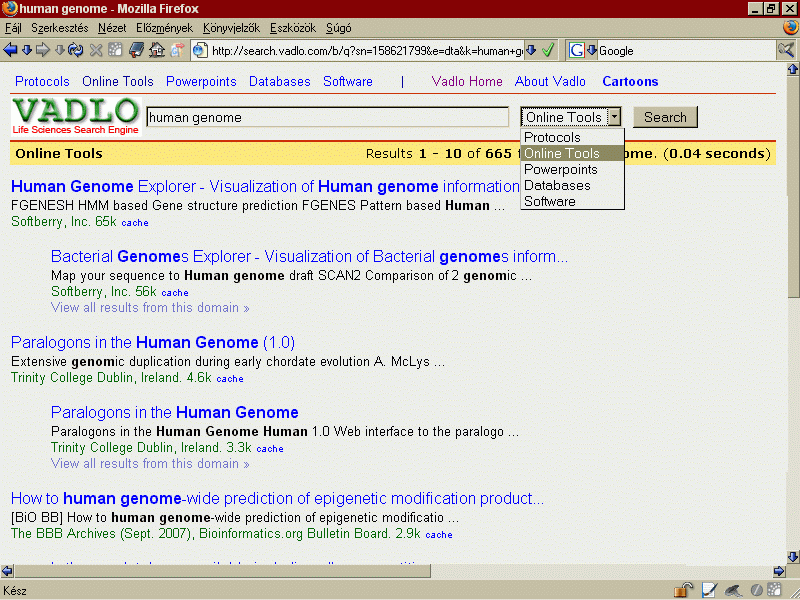 keresőgépek és keresési megoldások helyett téma, típus, műfaj, domain vagy egyéb szempont szerint szűkített keresés. Vannak kifejezetten vertikális keresők, amelyek valamire specializáltak (pl. utazási információk, termékek, tudományos publikációk) és vannak általános keresőgépek, amelyek lehetőséget adnak rá, hogy a felhasználó vertikálisan keressen tovább (pl. a Google-nél hírekben, blogokban, fórumokban, könyvekben stb. tudunk továbbkeresni, illetve korlátozhatjuk a témánkat képekre, videókra, termékekre stb.).
keresőgépek és keresési megoldások helyett téma, típus, műfaj, domain vagy egyéb szempont szerint szűkített keresés. Vannak kifejezetten vertikális keresők, amelyek valamire specializáltak (pl. utazási információk, termékek, tudományos publikációk) és vannak általános keresőgépek, amelyek lehetőséget adnak rá, hogy a felhasználó vertikálisan keressen tovább (pl. a Google-nél hírekben, blogokban, fórumokban, könyvekben stb. tudunk továbbkeresni, illetve korlátozhatjuk a témánkat képekre, videókra, termékekre stb.).
- web directory (webkatalógus/linkgyűjtemény/tematikus katalógus): Teljesen vagy legalább részben emberi közreműködéssel szerkesztett és kategóriák szerint rendezett nyilvántartások az interneten található
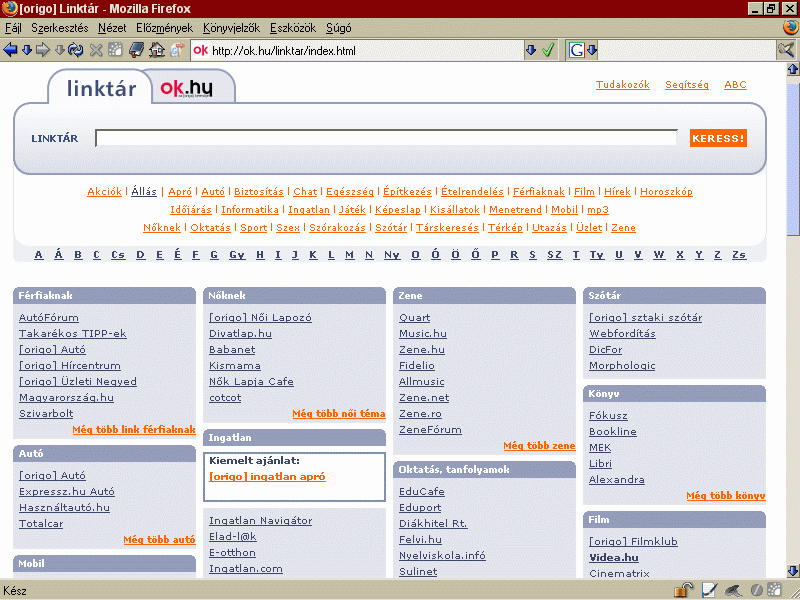 website-ok válogatott részéről. A site neve és címe mellett témakörök, kulcsszavak/címkék és esetleg rövid leírások is lehetnek bennük. Egyes katalógusokat szerkesztők válogatnak, másoknál bárki bejelenthet webhelyeket egy vagy több kategóriába (de rendszerint ilyenkor is van valamilyen előzetes vagy utólagos kontrol), és van ahol fizetni is kell a bekerülésért vagy a bentmaradásért. Az általános, szinte minden témára kiterjedő rendszerek (pl. a Yahoo! Directory, az Open Directory Project, vagy a könyvtárosok által szerkesztett Ifomnine) mellett vannak vertikális katalógusok is, amelyek valamilyen szempontra fókuszálnak (pl. az egyben vertikális keresőt is működtető Business.com). A web directory-k egy része saját belső keresővel is rendelkezik, így nemcsak böngészéssel lehet megtalálni a számunkra érdekes webhelyeket, viszont mivel a katalógusok humán erőforrással szerkesztett adatbázisai jóval kisebbek a robotokkal működő keresőgépekéinél, ezért sokkal kevesebb, bár értékesebb találatot kapunk. A webkatalógusokban való jelenlét megnöveli az adott website page rank értékét, így sokan megpróbálnak visszaélni a lehetőséggel. Emiatt több webkatalógusból ki vannak tiltva a keresőrobotok vagy nofollow opció van beállítva a robots.txt-ben, hogy ezek a linkek ne növeljék a site-ok fontosságát.
website-ok válogatott részéről. A site neve és címe mellett témakörök, kulcsszavak/címkék és esetleg rövid leírások is lehetnek bennük. Egyes katalógusokat szerkesztők válogatnak, másoknál bárki bejelenthet webhelyeket egy vagy több kategóriába (de rendszerint ilyenkor is van valamilyen előzetes vagy utólagos kontrol), és van ahol fizetni is kell a bekerülésért vagy a bentmaradásért. Az általános, szinte minden témára kiterjedő rendszerek (pl. a Yahoo! Directory, az Open Directory Project, vagy a könyvtárosok által szerkesztett Ifomnine) mellett vannak vertikális katalógusok is, amelyek valamilyen szempontra fókuszálnak (pl. az egyben vertikális keresőt is működtető Business.com). A web directory-k egy része saját belső keresővel is rendelkezik, így nemcsak böngészéssel lehet megtalálni a számunkra érdekes webhelyeket, viszont mivel a katalógusok humán erőforrással szerkesztett adatbázisai jóval kisebbek a robotokkal működő keresőgépekéinél, ezért sokkal kevesebb, bár értékesebb találatot kapunk. A webkatalógusokban való jelenlét megnöveli az adott website page rank értékét, így sokan megpróbálnak visszaélni a lehetőséggel. Emiatt több webkatalógusból ki vannak tiltva a keresőrobotok vagy nofollow opció van beállítva a robots.txt-ben, hogy ezek a linkek ne növeljék a site-ok fontosságát.
- social search (közösség-alapú keresés): Az automatikus keresőrendszerek helyettesítése vagy kiegészítése az internethasználók ismereteivel, ítéleteivel. Többféle formája lehet: az egyszerű
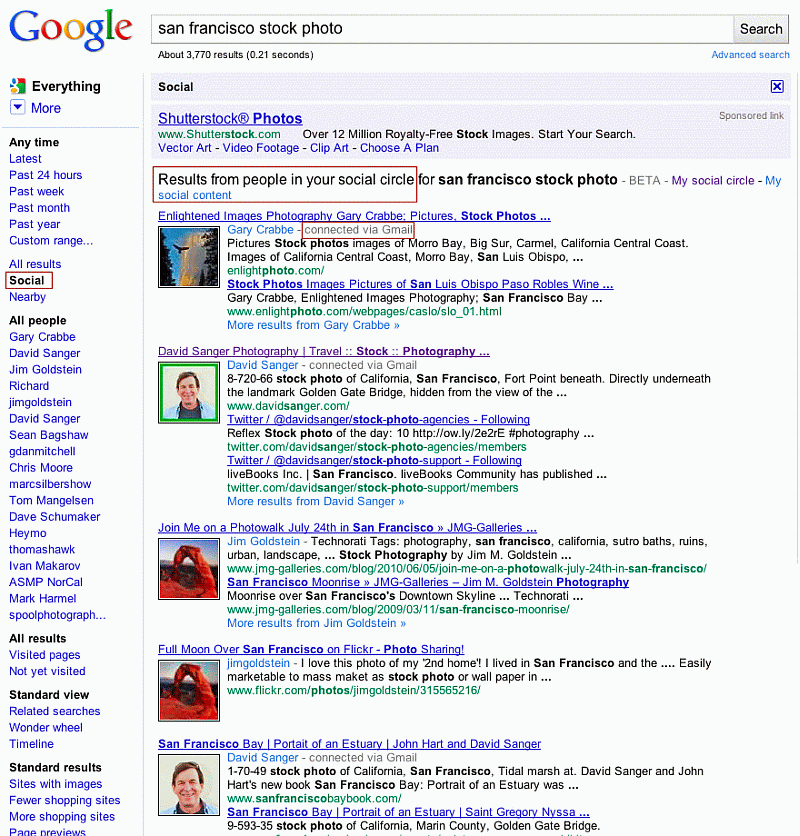 könyvjelző-megosztástól a webhelyek címkézésén és minősítésén át a találati listák sorrendjének megváltoztatásáig. Egyre több keresőrendszer beépíti a közösségi oldalakról, ismeretségi hálókról, linkmegosztó helyekről, blogokról és mikroblogokról származó információkat is a webhelyek fontosságának megállapításába, csökkentve ezzel - elvileg - az automatikus módszerek hátrányait, pl. a spam és a SEO hatását. A 2009-ben bevezetett Google Social Search a Gmail levelezőpartnereink, a Twitter, FriendFeed, Picassa oldalainkon levő kontaktjaink, az általunk figyelt RSS csatornák stb. alapján állítja össze az ismerőseinkből és az ismerőseink ismerőseiből azt a kört, amelyet figyelembe vesz ezután, és ha a kereséseink során talál általuk megosztott tartalmat, akkor azt a találati oldal alján megjeleníti.
könyvjelző-megosztástól a webhelyek címkézésén és minősítésén át a találati listák sorrendjének megváltoztatásáig. Egyre több keresőrendszer beépíti a közösségi oldalakról, ismeretségi hálókról, linkmegosztó helyekről, blogokról és mikroblogokról származó információkat is a webhelyek fontosságának megállapításába, csökkentve ezzel - elvileg - az automatikus módszerek hátrányait, pl. a spam és a SEO hatását. A 2009-ben bevezetett Google Social Search a Gmail levelezőpartnereink, a Twitter, FriendFeed, Picassa oldalainkon levő kontaktjaink, az általunk figyelt RSS csatornák stb. alapján állítja össze az ismerőseinkből és az ismerőseink ismerőseiből azt a kört, amelyet figyelembe vesz ezután, és ha a kereséseink során talál általuk megosztott tartalmat, akkor azt a találati oldal alján megjeleníti.
- search engine optimization (SEO) (keresőoptimalizálás/keresőmarketing): Olyan módszereknek, technikáknak az összefoglaló neve, amelyekkel befolyásolni lehet egy weboldal fontosságát és ezzel pozícióját a keresőrendszerek találati listájában. Ide tartoznak például a következők: a robottal való bejárhatóság biztosítása, az oldal tartalmában levő kulcsszavak és a fejlécében levő metaadatok megfelelő megválasztása, az oldalra hivatkozó linkek számának növelése, lehetőleg olyan helyekről, amelyek fontosak a keresőgépek számára, valamint elkerülése az olyan megoldásoknak és trükköknek, amelyeket büntetnek a keresőgépek. 2010 áprilisában a Google bejelentette, hogy ezentúl a letöltési sebességet is figyelembe veszi a page rank kiszámításánál, így kis mértékben már az oldal összmérete és a szerver hálózati kapcsolata is befolyásolja - több mint 200-féle egyéb szempont mellett - azt, hogy hányadik helyre kerül a találati listában.
Összeállította: Drótos László, Magyar Elektronikus Könyvtár




