A deep learning buzzword lett, a big data területén lassan nem szexi az, ami nem alkalmaz valamilyen deep neural networköt vagy valami hasonlót. A Google Brain projekt kapcsán a mesterséges intelligencia reneszánszáról beszélnek sokan. Avval viszont kevesen vannak tisztában, hogy alapvetően a "forradalmian új" ötlet a kognitív tudományból érkezett, leánykori nevén konnekcionizmusnak és párhuzamos megosztott feldolgozásnak hívták, gyökerei egészen a számítástudomány hajnaláig, Neumann és Turing írásaihoz köthetők.
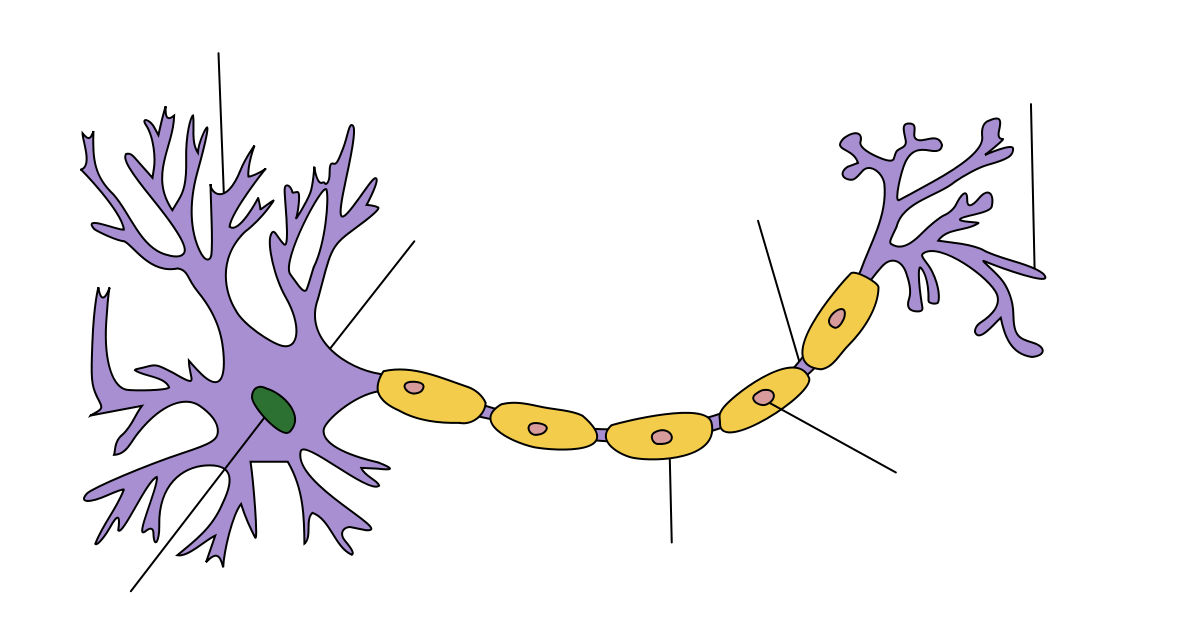
Neumann és a digitális számológépek
A első idealizált neuron modell McCulloch és Pitts írta le A logical calculus of the ideas immanent in nervous activity című dolgozatukban. Neumann eképpen foglalja össze ennek jelentőségét Az automaták általános és logikai elméletében:
McCulloch és Pitts elméletének fontos eredménye, hogy a fenti értelemben vett bármely olyan működés, amelyet véges számú "szó" segítségével logikailag szigorúan és egyértelműen egyáltalán definiálhatunk, ilyen formális neurális hálózattal meg is valósítható. [...] A McCulloch-Pitts-féle eredmény [...] bebizonyítja, hogy minden, amit kimerítően és egyértelműen szavakba lehet foglalni - alkalmas véges neuronhálózattal ipso facto realizálható is. Minthogy az állítás megfordítása nyilvánvaló, állíthatjuk, hogy bármely reális vagy elképzelt, teljesen és egyértelműen szavakba foglalható viselkedési mód leírásának a lehetőse és ugyanennek a véges formális neuronhálózattal való megvalósításának a lehetősége között nincs különbség. A két fogalom terjedelme egyenlő.
Neumann A számológép és az agy című írásában veti részletesebben össze a természetes és mesterséges automatákat, azaz az emberi agyat és a számítógépeket. A természetes automatákkal kapcsolatban külön kiemeli, hogy a mai szakzsargonnal élve meglepő módon jó hibatűrők, nem akasztja meg őket egy-egy "alkatrész" hiánya vagy a zavaros input. Megállapítja továbbá, hogy
[...] az adatok arra mutatnak, hogy természetes alkatelemekből felépített berendezések esetében nagyobb számú, bár lassúbb szerv alkalmazása részesíthető előnyben, míg mesterséges alkatelemekből felépített berendezések esetében előnyösebb, ha kevesebb, de gyorsabb szervet alkalmaznak. Így tehát azt várhatjuk, hogy egy hatékonyan megszervezett természetes automata (mint az emberi idegrendszer) minél több logikai (vagy információs) adat egyidejű felvételére és feldolgozására lesz berendezve, míg egy hatékonyan megszervezett nagy mesterséges automata (például egy nagy modern számológép) inkább egymás után látja majd el teendőit - egyszerre csak egy dologgal vagy legalábbis nem olyan sok dologgal foglalkozik. Röviden: a nagy és hatékony természetes automaták valószínűleg nagy mértékben párhuzamos működésűek, míg a nagy és hatékony mesterséges automaták inkább soros működésre rendezhetők be.
Neumann álma valóra válik a nyolcvanas években
A konnekcionizmus szülőapja Donald O. Hebb a múlt század negyvenes éveiben javasolta az idegrendszerhez hasonló modellek használatát először. Egy idealizált konnekcionista modellben az inputokat outputokhoz kötjük, az asszociáció erősségét is megadjuk (azaz mikor tüzel képzeletbeli neuronunk) és van egy nagyon egyszerű hálónk. Ezek közül a legegyszerűbbek pl. a AND, NAND és OR logikai függvényeket megvalósító hálózatok, mivel csupán két réteg (layer) mesterséges neuronnal megvalósíthatóak.
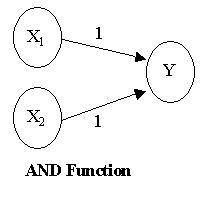
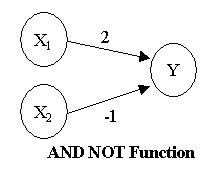
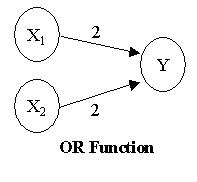
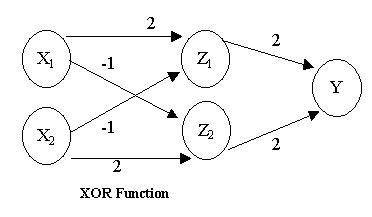
Kicsit bonyolultabb a XOR logikai kapu neurális megvalósítása, mivel ehhez már három rétegre van szükségünk. (Bővebben erről itt)
A nyolcvanas években Paul Smolensky (nyelvész olvasóinknak az optimalitáselméletből lehet ismerős a neve) köré kezdtek szerveződni a konnekcionisták, akik a kor színvonalához képest már nagyon jó számítógépes modellekkel dolgoztak. A kétrészes Parallel Distributed Processing tanulmánykötetben összegezték munkáikat 1987-ben, melyet még ma is szívesen hivatkoznak a terület kutatói. A PDP csoport alapvetően Neumann gondolatát vitte tovább a párhuzamos feldolgozást illetően. A gyakorlatban egy-egy ún. szubszimbolikus kognitív folyamatot modelleztek (pl. számjegyek felismerése, szófelismerés, a legbonyolultabb és egyben legismertebb magasabb szintű folyamatot modellező kísérlet a Rumelhart és McCelland On the learning of past tenses of English verbs tanulmányban leírt modell). Habár nagyon sikeres volt a csoport és figyelemre méltó eredményeket értek el, a kutatási irányzat a kilencvenes években kiesett az ipar látóköréből és megmaradt akadémiai hobbinak.
Hogyan reprezentál és tanul egy konnekcionista rendszer?
Már Neumann számára is felmerült ez a kérdés. Az automaták általános és logikai elméletében a Smolensky által javasolt megoldást előlegezte meg:
A logikai műveleteket [...] olyan eljárással kell tárgyalni, amelyek kicsi, de nem zérus valószínűséggel megengednek kivételeket (hibás működést. Mindez olyan elméletekhez fog vezetni, amelyek sokkal kevésbé mereven "minden vagy semmi" természetűek, mint a fomális logika a múltban és a jelenben. [...] Ez a termodinamika, elsősorban abban a formájában, amelyet Boltzman alkotott meg.
Smolensky On the proper teatment of connectionism (magyarul A konnekcionizmus helyes kezeléséről in. Pléh (szerk.): Kognitív tudomány) c. tanulmányában tesz kísérletet a PDP határainak és módszereinek kijelölésére. A Neumann által kifejtett következtetést Smolensky a Legjobb Illeszkedés Elvének hívja:
Egy adott bemenet esetén a szubszimbolikus rendszer kimenete egy következtetéshalmaz, amely mint egész a legjobb illeszkedést mutatja az inputhoz, abban a statisztikai értelemben, amelyet a rendszer kapcsolataiban tárolt statisztikai tudás határoz meg.
Ez nem más mint egy Boltzmann-gép, ami egy olyan H harmóniafüggvény, ami bemenethez illeszkedő kimeneteket rangsorolja az előállításukhoz szükséges komputációs "hőmérséklet" vagy energiaszint szerint. (Ezeket a Boltzmann-gépeket tökéletesítette kiszámíthatósági szempontból Geoffry Hinton, a deep learning alapítója) Képletek helyett nézzük meg inkább egy gyakorlati példán keresztül mit is jelent ez!
Rakéták és Cápák
Clark A megismerés építőköveiben McCelland, Rumelhart és Hinton(!) példáján keresztül nagyon szemléletesen mutatja meg, hogyan is reprezentálható tudás egy hálózatban és mit jelent a Legjobb Illeszkedés Elve szerint következtetni. Ehhez először nézzünk meg két New York utcáin tevékenykedő banda felépítését.

A táblázat hálózatban így néz ki.
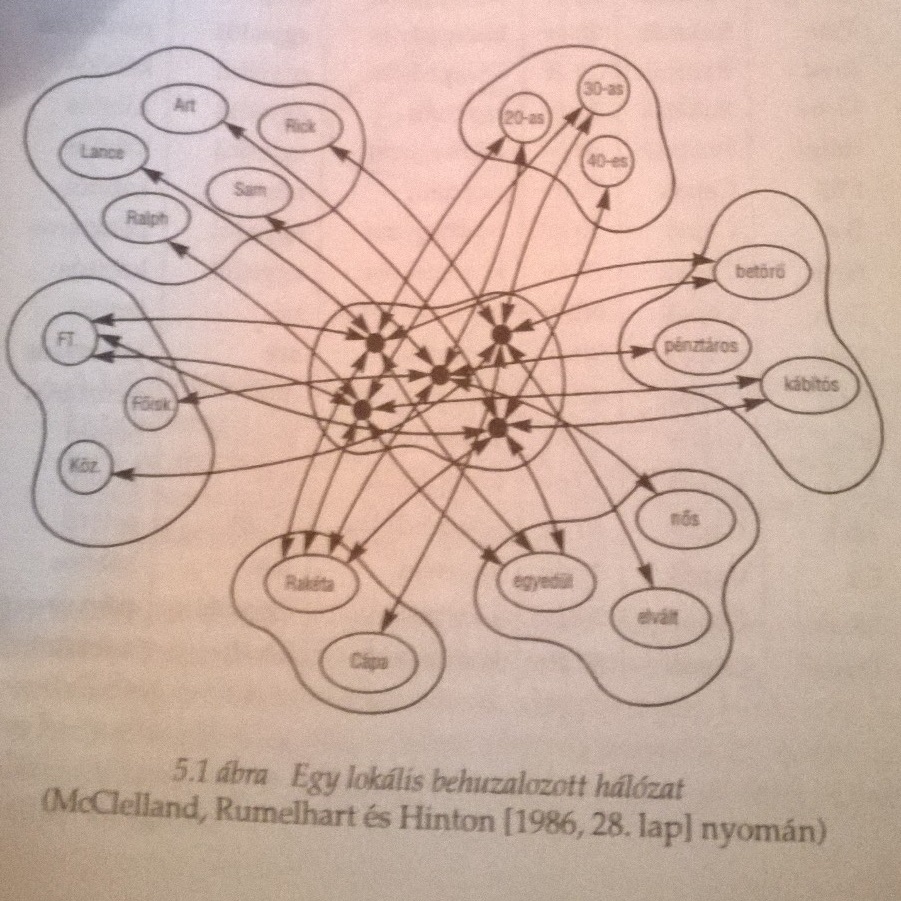
Tegyük fel, hogy meg akarjuk tudni milyen egy harmincas cápa. Ekkor a bemeneti aktivitások tovaterjednek és a legerősebb kapcsolatok irányában. Úgy tűnik, ezzel megkapjuk a prototipikus harmincas cápát, aki elvált, betörő és középiskolát végzett...
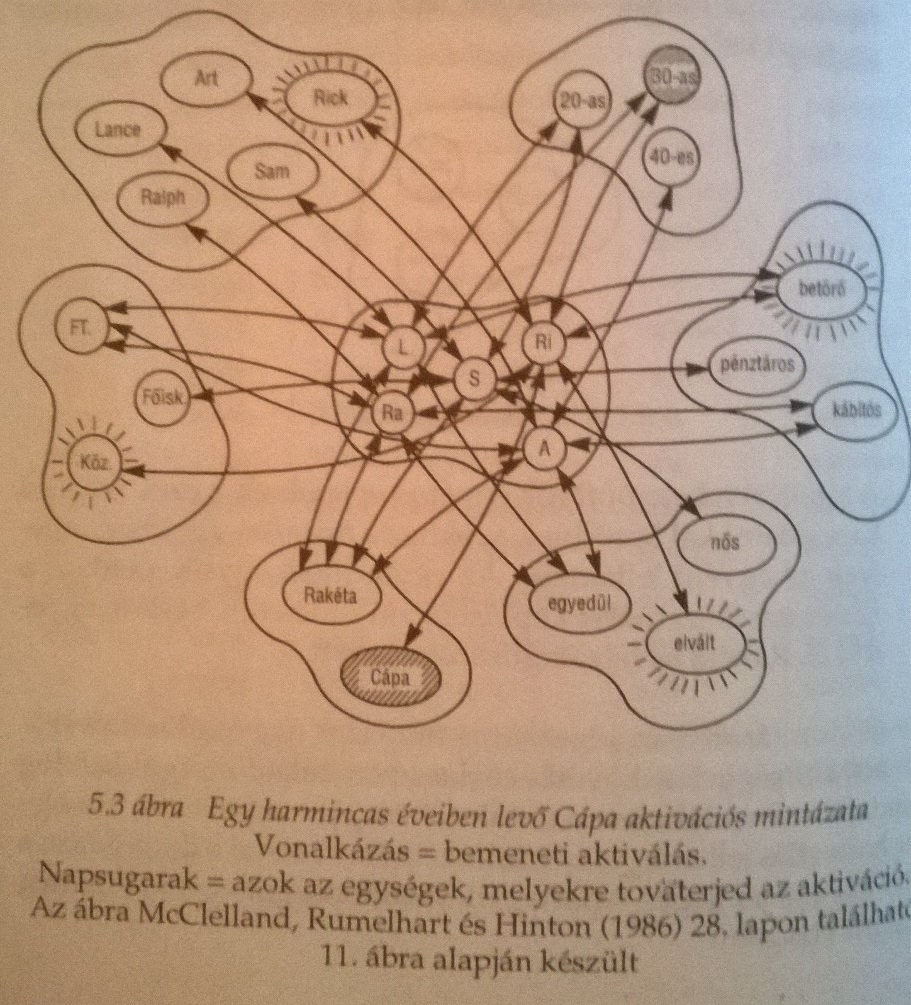
Jól látható, hogy a konnekcionista hálónk bizonyos mértékig tűri a hibákat. Ha valamiért pl. a családi állapotra vonatkozó információ nem elérhető, akkor is egész jól közelíti az optimumot az eredmény, hiszen a betörő és a középiskolai végzettség továbbra is aktív marad.
Geoffry Hinton és a deep learning
Hinton a pszichológia felől érkezett a mesterséges intelligenciába, érhető hogy a PDP csoportnál találta magát. Itt a Boltzmann-gépek tökéletesítése során érdeklődése a számítástudományi alkalmazások felé fordult és a kilencvenes években egy sor új eljárást dolgoztak ki a neurális hálókkal történő tanulásra. Mindeközben erős tudományszervező tevékenységet folytatott és Kanadát igazi neurális háló nagyhatalommá tette.
A deep learning neve onnét ered, hogy a XOR kapu három rétegénél jóval több ún. rejtett réteggel (hidden layer) dolgozik ez ilyen elven megvalósított rendszer. A mély rétegek többféle architektúrával dolgoznak (a deep learing szócikk a Wikipedia-n nagyon jó a témában!) és általános problémájuk hogy rendkívül számításigényesek és sok adattal adnak igazán jó eredményeket. Ezért sokkal inkább mérnöki bravúr egy deep learnign rendszer, mint kognitív modell! A deep learning kutatói általában GPGPU technológiával dolgoznak, nagyon gyakran olcsó, játékosoknak szánt GPU-kkal felszerelt gépeken. A Google kutatói által publikál Large Scale Distributed Deep Networks paper alaposan megkritizálta ezt a paradigmát s egyben körvonalazta, hogyan lehet big data infrastruktúrán megvalósítani egy deep learning rendszert. Napjainkban sorra indulnak a deep learning startupok - meglátjuk mire jutnak. Nem árt észben tartani, hogy a mesterséges intelligenciában két nagyobb ún. "AI winter"-t tartanak nyilván, számtalan kisebb mellett, melyeket hatalmas lelkesedés előzött meg és jókora csalódás követett!