



A nyelvazonosítás problémája elsőre nem tűnik nehéznek. Az ember egyszerűen felismeri hogy különböző nyelveket hall vagy éppen olvas, még akkor is, ha nem ismeri ezen nyelveket. De mi a helyzet a gépekkel? Mivel politikai blogokat elemző projektünk során felmerült a magyar tartalmak azonosításának problémája alaposabban megvizsgáltuk az elérhető eszközöket az R és Python nyelvekben is.
A fenti számban tökéletesen el tudjuk különíteni a francia és a bambara nyelvet, de hogy miért, azt már nagyon nehezen tudjuk megmagyarázni. A nyelvre - legnagyobb sajnálatunkra - jellemző, hogy tudása ösztönösen, magától jön, ezért a nyelvtechnológus sokszor inkább valamilyen gyors megoldást keres és nem a nyelvtudást modellezi. A nyelvazonosítás során is így járnak el a modern eszközök, melyek a TextCat program köpönyegéből bújtak ki.
A TextCat elsők között szakított azzal, hogy bármilyen nyelvészeti információt próbáljon megtudni az elemzett szövegről. Ehelyett ún. n-gram karakter modellekkel dolgozott, azaz egy-egy nyelvből korpuszok segítségével előállították az n hosszúságú karaktersorok eloszlását. A kapott nyelvmodellhez hasonlít a program minden inputot és megpróbálja megtalálni melyik eloszláshoz közelít.
textcat - a state-of-the-art algoritmus R-ben van implementálva
A textcat (így csupa kisbetűvel) a jelenleg elérhető legjobb nyelvazonosító könyvtár. A hagyományos karakter alapú nyelvmodellek készítését gondolták újra megalkotói, illetve a korral haladva jelentősen megnövelték a modell nagyságát is, s evvel igen nagy hatékonyságot értek el. A textcat mögötti elméleti megfontolásokról a készítők tanulmányából lehet többet is megtudni, mi itt csak azt emeljük ki, hogy viszonylag nehéz "megfektetni" az eszközt. Miképp az alábbi ábra is mutatja, külön nyelvtudományi vita tárgya lehetne hogy a szerb-horvát-bosnyák hármas keverése hibának tekinthető-e, vagy hogy a skandináv nyelvekkel mit kezdjünk.
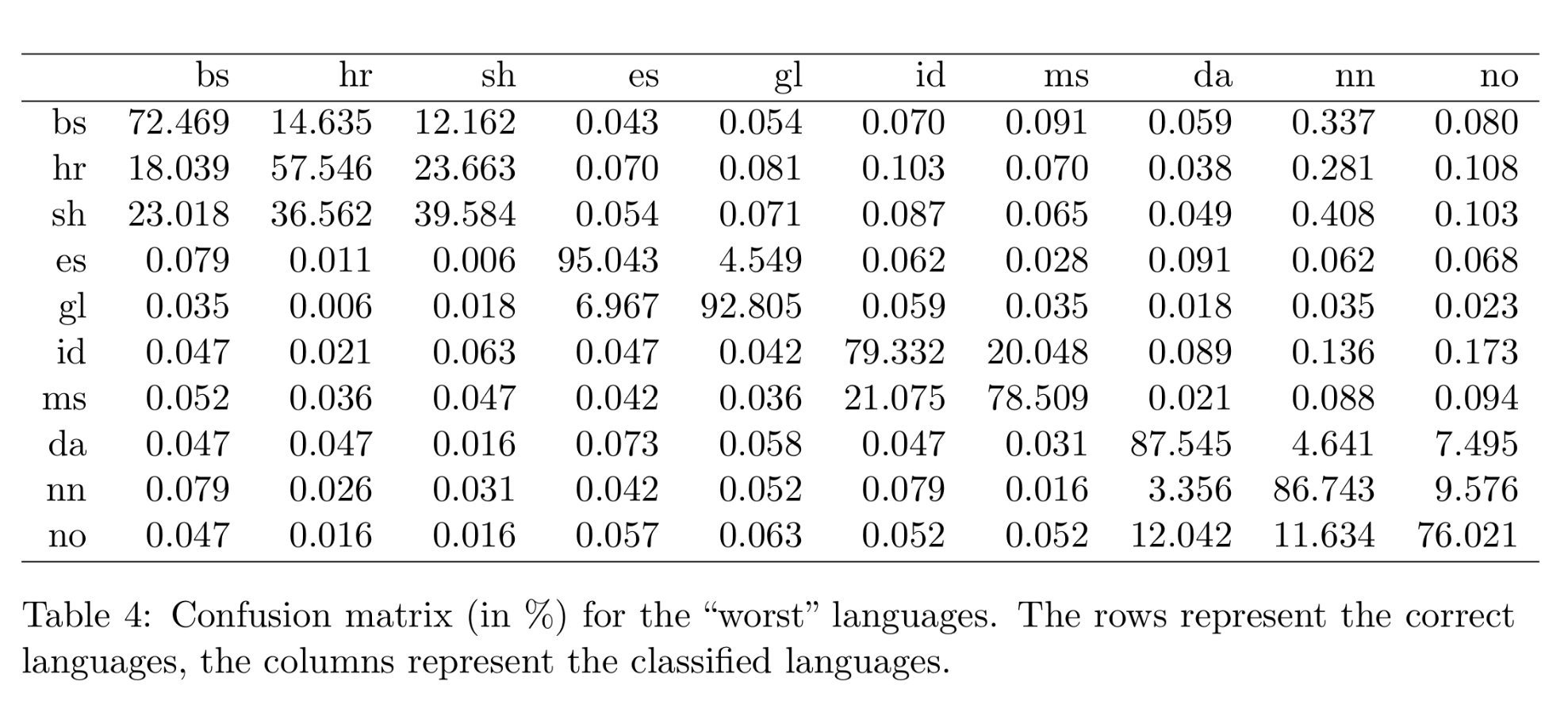
A szerzők hierarchikusan klaszterezték hogy a modellek összevetése során miképp alakulnak a tippek, ebben látható hogy a valenciai és a katalán pl. nagyon hamar kerül egymás mellé. A tudománytalan nyelvrokonítási kísérletek híveinek pedig ajánlom a magyar-breton és magyar-baszk rokonság megfontolását, karakter n-gramokra alapozva lehet mellette érvelni!
langid.py - a pythonisták válasza a nyelvazonosításra
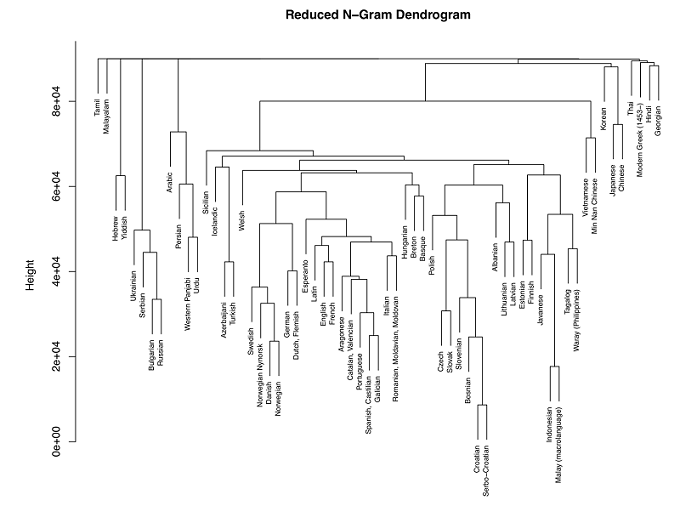
A langid.py alkotói a hagyományos megoldást választották, de nagy gondot fordítottak a tréningadatokra és arra, hogy sok nyelvet legyen képes felismerni eszközük.
A kiértékelés során nagyon szép eredményeket ért el a langid.py Az, hogy 97 nyelvet képes felismerni, igazi, rögtön bevethető könyvtárrá teszi, amit minden pythonista tud használni, előzetes nyelvtechnológiai ismeretek nélkül is. Akit érdekel hogyan készült az eszköz, az mindenképpen olvassa el megalkotóinak tanulmányát!
Verdiktet nem mondunk. Mindkét eszköz nagyon jó - hogy ki melyiket használja, az ízlés és megszokás kérdése.
