A 2016 elején kezdődött megmozdulás során többezer tanár, diák és támogató vett részt a tüntetéseken, hogy kifejezzék a kormány oktatáspolitikájával szembeni nemtetszésüket. A Budapesten és más nagyobb városokban szervezett események közül a február 13-i és március 15-i tüntetések keltették a legnagyobb visszhangot a médiában és az emberek körében. Az aktív résztvevőkön kívül sok tízezren jelezték érdeklődésüket vagy fejezték ki véleményüket, aminek tökéletes helyszínt nyújtott a két esemény Facebook oldala.

Hogy elemezni tudjuk a 2016. február 13-i és március 15-i Facebook események szövegeit és a felhasználók aktivitását, készítettünk egy dashboardot, ami ezen a linken érhető el.
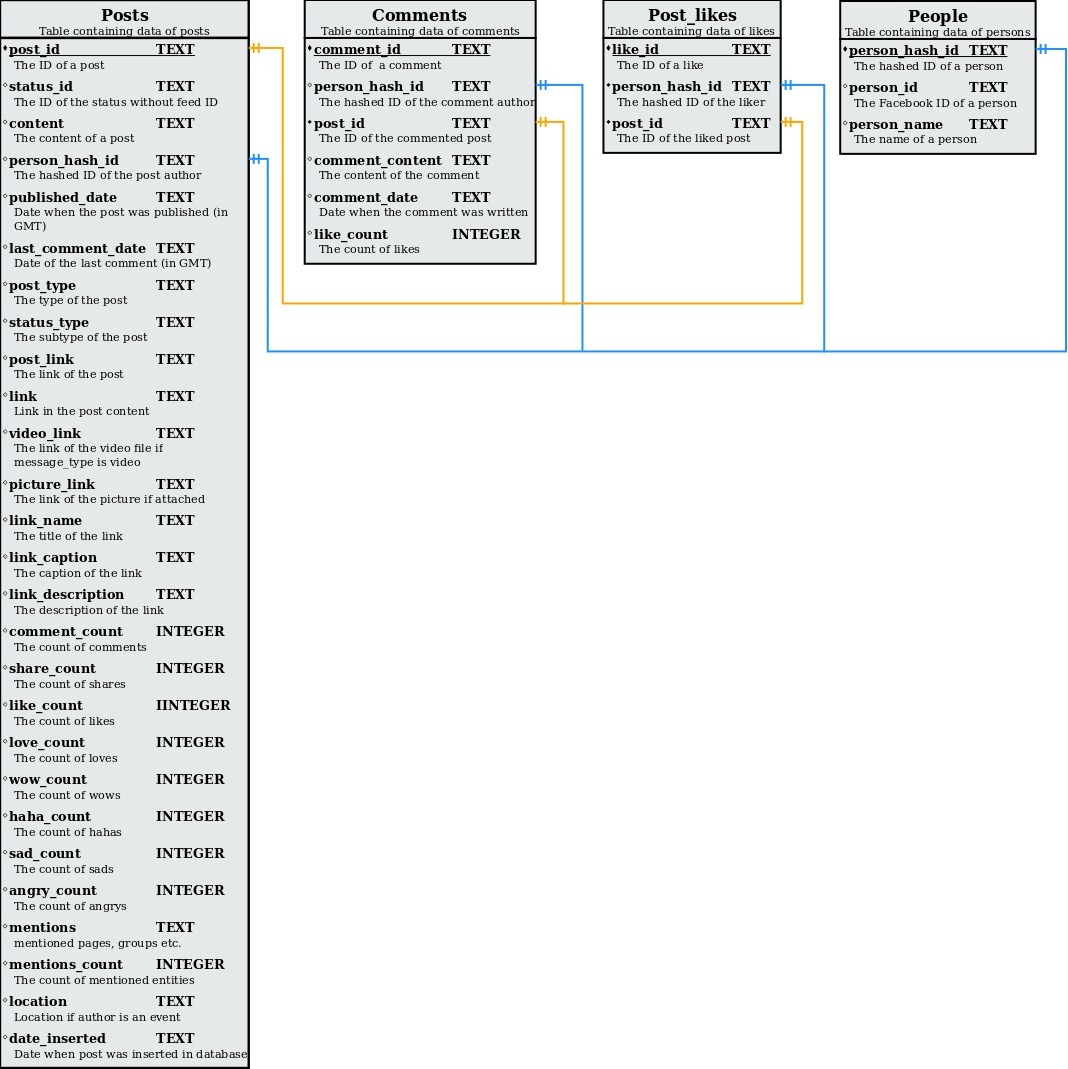
Az adatokat a Facebook scraperünk segítségével szedtük le, ami a két Facebook eseménynél keletkezett posztokat, kommenteket, lájkokat, reakcióikat és az eseményeknél aktív felhasználókat, valamint az ezekkel kapcsolatos információkat nyerte le. Ezután vizualizációkat készítettünk és egy Shinyval készült dashboardon jelenítettük meg őket.
A dashboard egyik része az aktivitást jelző adatokat (posztolás, megosztás, komment, lájk), a másik része a szöveges adatokat (posztok és kommentek szövege) elemzi ábrák segítségével.
Az ábrák alapján többek között az is kiderül, hogy a posztok mellett a februári eseménynél a linkek, a márciusi eseménynél a képek esetében voltak aktívabbak az embereket. A lájkok és kommentek alapján készült hálózatokból pedig az is látszik, hogy a két eseménynél ugyanaz a két felhasználó a legközpontibb szereplő, őket kommentelik és lájkolják a legtöbben. (A felhasználók identitása el van fedve.)
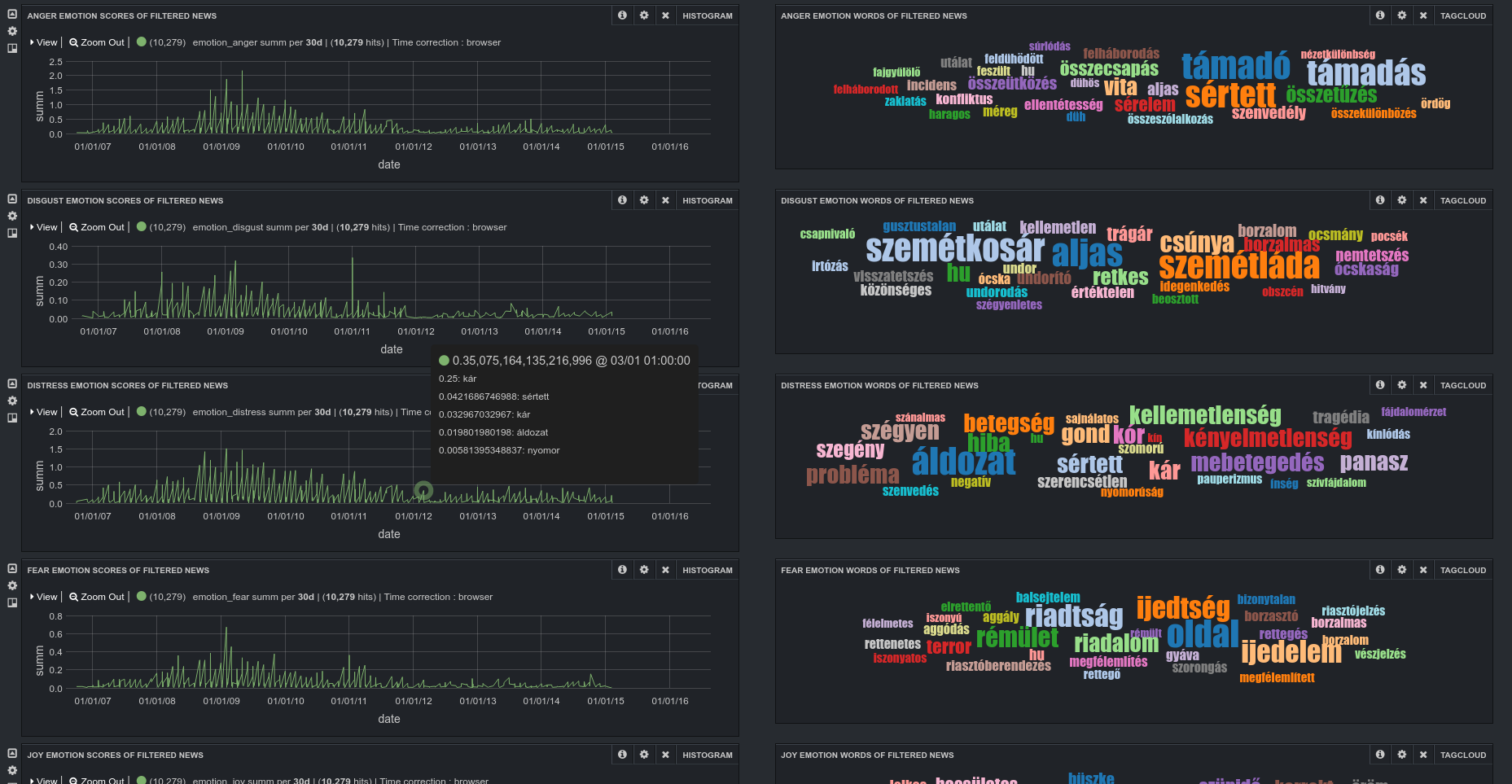
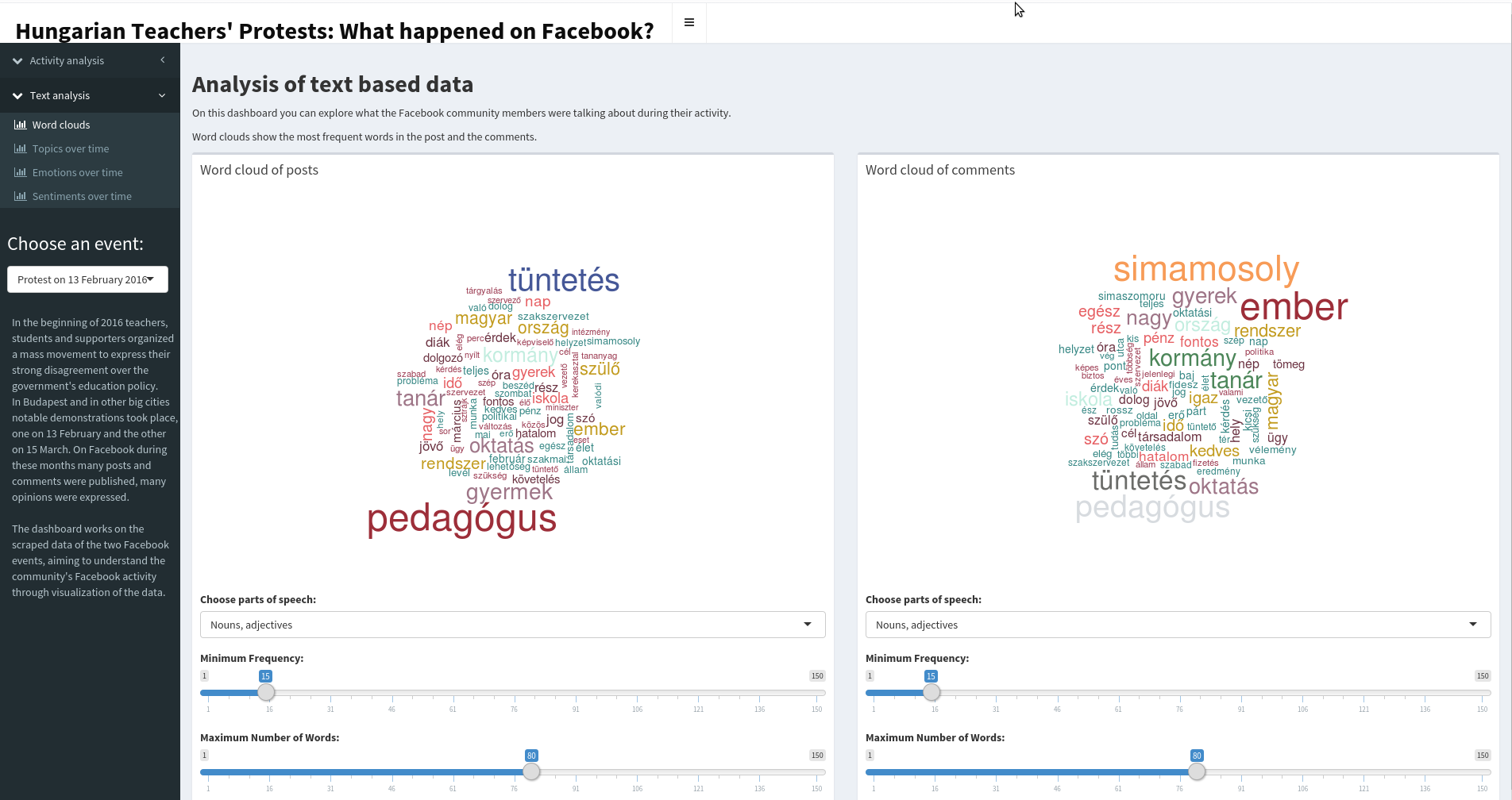
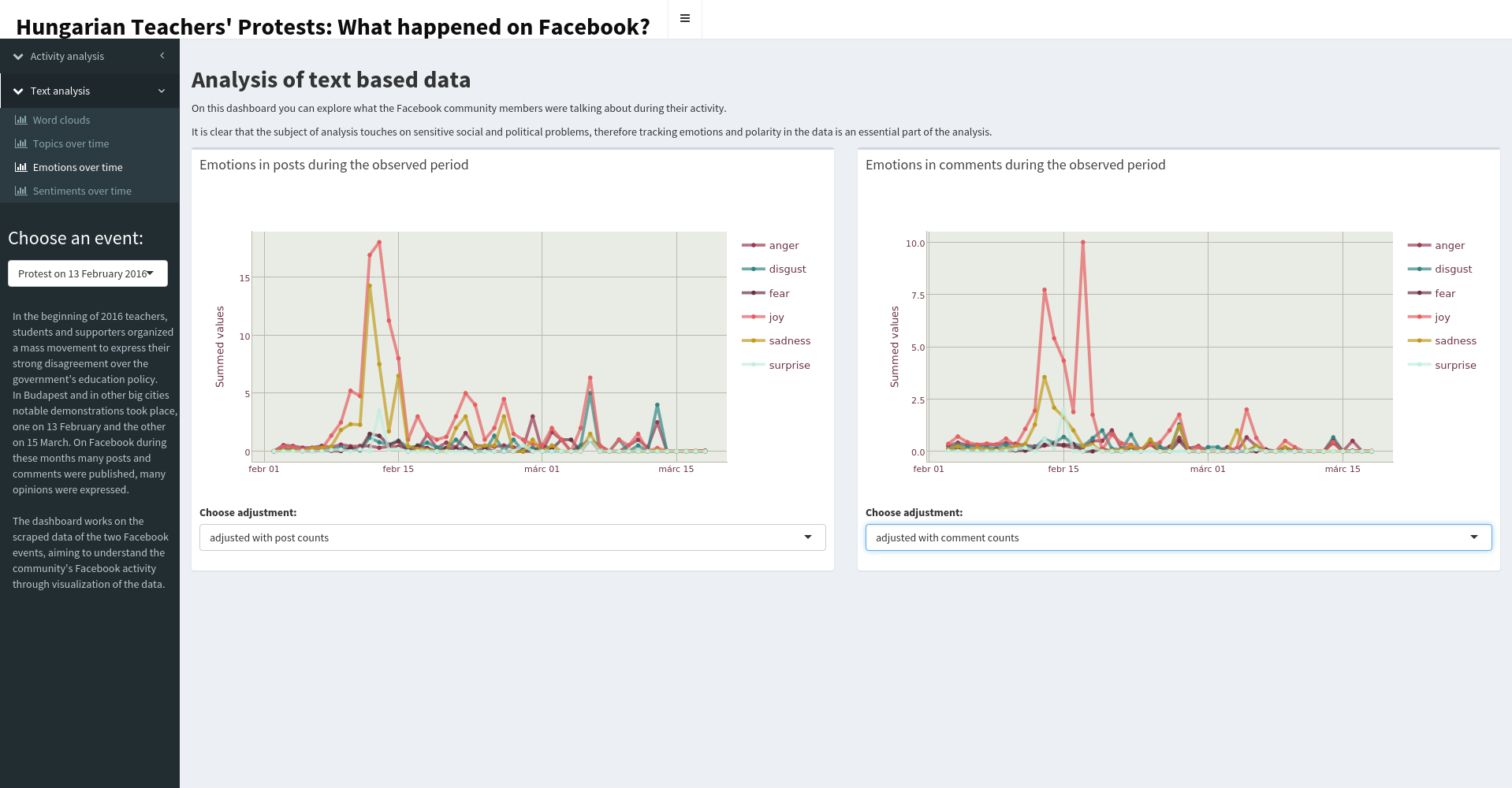
A szófelhők mutatják a két esemény leggyakoribb szavait, amik a februári eseménynél a pedagógus, a tüntetés, a gyermek, a kormány, az ember, míg márciusban az 1848 március 15-i események felelevenítése miatt a március szó is nagy szerephez jut. A szöveges adatokban megjelenő érzelmek is érdekes képet mutatnak. A februári eseménynél a posztokban végig az öröm a legerőteljesebb érzelem, míg a második legjellemzőbb az esemény időpontja körül a szomorúság, majd átveszi a szerepet az undor. A márciusi eseménynél szintén az öröm volt a legerőteljesebb emóció, azonban a második legjellemzőbbnek itt a félelem bizonyult.
Ezeken kívül természetesen még sok érdekes dolog leszűrhető a dashboard alapján, például, hogy milyen témákról beszélgettek a felhasználók, úgyhogy érdemes rákattintani.