A machine learning esetében hatványozottan igaz a garbage in, garbage out elve. Az iparban nagy erőforrásokat teszünk abba, hogy az adatokat legyűjtsük, transzformáljuk, kitisztítsuk, majd a legtutibbnak mondott algoritmusokba dobjuk, hogy végül bosszankodjunk mert "a 99%-os pontosság csak az akadémiai világban létezik". Ilyenkor indul megint egy kör, még több adatot akarunk, vakarjuk a fejünket, hívjuk kutató barátainkat. Ezeknek a köröknek a jelentős része megspórolható, ha néha belenézünk az adatainkba.
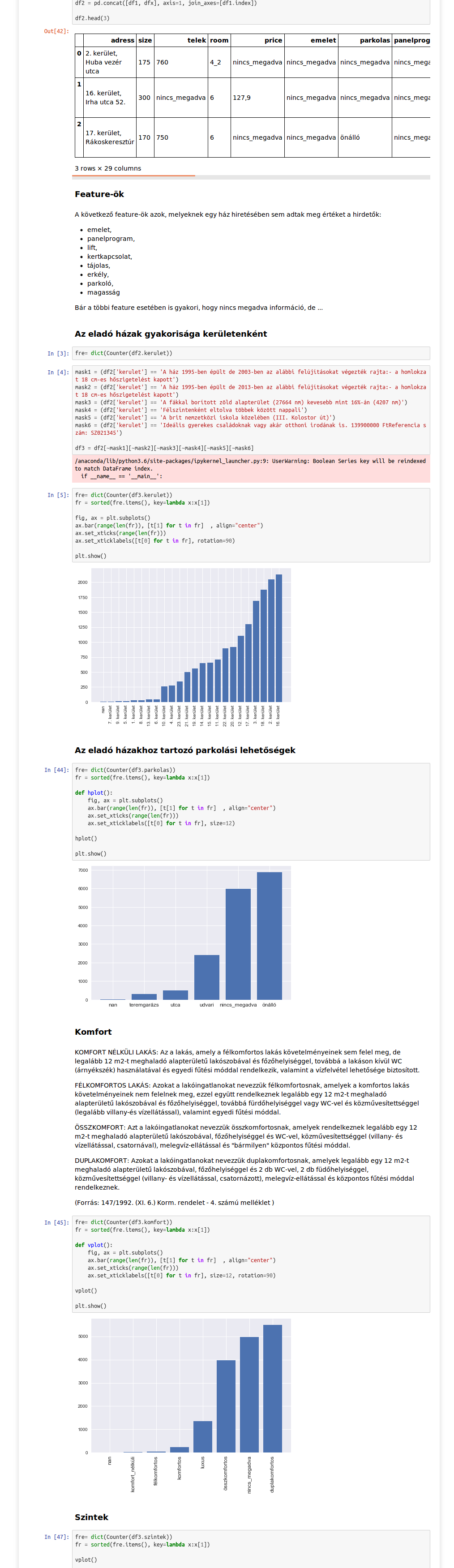
A fenti ábra egy jelenleg futó projektünkhöz készült. A projekthez van minden, amit szeretünk, szép feldolgozó pipeline, feature extraction, stb. Leszedünk több gigányi lakáshirdetést, hogy a végén legyen egy hatvanezer soros csv fájlunk. A feldolgozott adatokra aztán lesz minden, egy csodás report, modell mert prediktálni is kell és biztos vagyok benne, hogy menet közben sok más dolog is eszünkbe fog még jutni. Amíg a feldolgozósor elnyeri végső formáját, addig is lehet nézegetni az adatokat, nem árt egy leíró statisztika hogy lássuk mivel állunk szembe. Erre találták ki a Jupyter Notebook-ot.
Ha nincs kéznél lelkes kolléga, aki alapos riportot készít Jupyter-ben, akkor van látványos és könnyen használható alternatíva; a Facets. A Google PAIR Code projektje a Jupyter notebookok használatát gondolta tovább, pár sorba sűríti a szokásos adatfelfedezést és egy interaktív felületet generál nekünk. Így tényleg szinte ránézésre látszik mivel is van dolgunk.
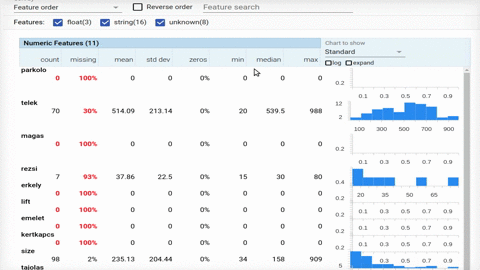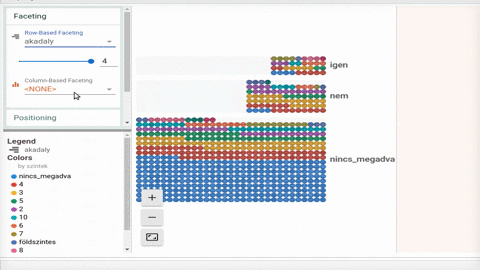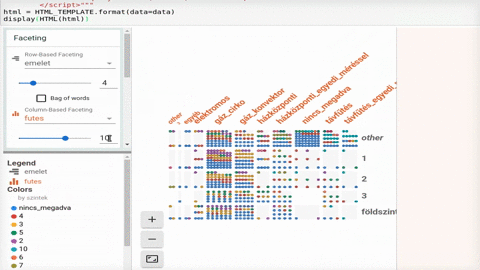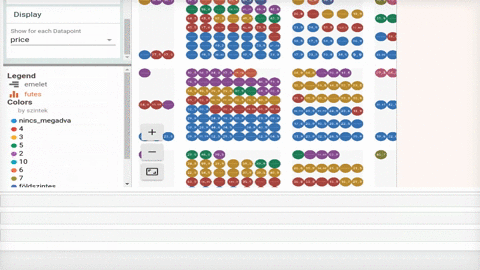
Habár elsőre megszerettük a Facets, úgy gondoljuk a munka első fázisában igazán hasznos, amikor sokat pörgünk az adatok beszerzésén és reszelésén, mi nem dobnánk el a szokásos riportot még.
De miért is olyan fontos folyton az adatainkat nézni? A legtöbb algoritmus amiről olvasunk remekül előkészített adatokon lett tanítva az őket bemutató publikációhoz. Ez annyit tesz, hogy pl. egy osztályozó minden osztályból kb. ugyanannyi példát lát. A "való világban" azonban nem ilyen adataink vannak, a legtöbb ügyfelünknél egy osztályból rengeteg, másból meg alig akad, ez egyenes út a "Class Imbalance Problem"-hez. Ha megismerjük alaposan az adatainkat, akkor egyrészt jó tippjeink lesznek arra, milyen eljárásokat érdemes bevetni majd a kívánt eredmények elérésére, másrészt felkészülhetünk lelkileg arra, hogy majd be kell vetnünk az imbalanced-learn-t.