November 30-án egy szuper konferencián szerepeltünk, egy igazán szuper helyen!

![]()
Bár ez nem tartozik szorosan a konferencia tárgyához, megjegyezzük, hogy teljesen lenyűgözött minket a a Pécsi Tudományegyetem Szentágothai János Kutatóközpontja, mind a technikáját, mind az építészeti sajátságait illetően.

A Big Datára idén 160-an regisztráltak!
A plenáris előadásokra a "Kavics" előadóban került sor.

Polyák Gábor (PTE BTK, SZKK, habilitált doktor, egyetemi docens) bemutatta a Szentágothai János Kutatóközpont Big Data kutatócsoportját. Botz Lajos (PTE GYTK, PhD, habil, egyetemi tanár, főgyógyszerész, intézetigazgató) a Big Data jelenségről az egészségügy szempontjából, a gyógyszerezéssel összefüggő adatelemzések lehetőségéről beszélt. Végül Feldmann Ádám (PTE Big Data kutatócsoport, ÁOK Magatartástudományi Intézet) tartott egy rendkívül érdekes előadást a Personogram projektről, amely személyiségvonások kinyerését célozza strukturálatlan szövegekből.
Ezután párhuzamos szekciók következtek. A precognoxos csapat a „Szövegbányászat, Duo-mining” szekcióban adott először elő.
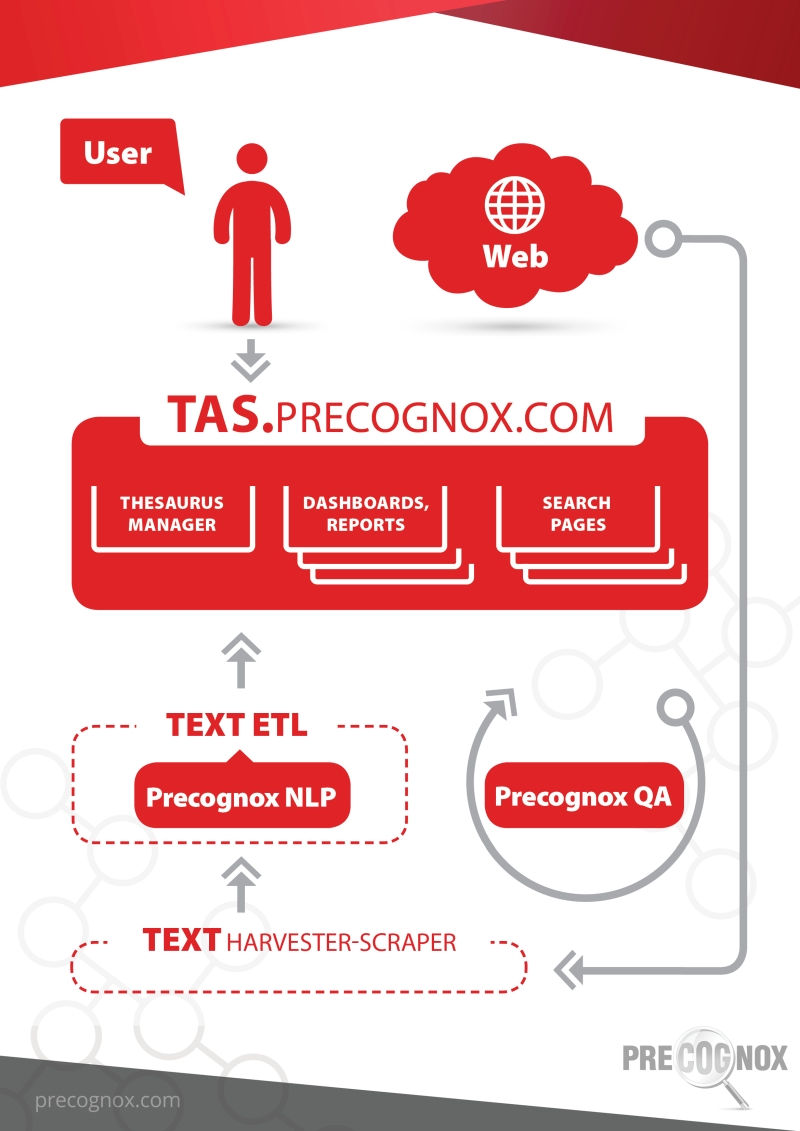
Magam a magyar és orosz nyelvű írott szövegek alapján végzett érzelemkivonatolási projektjeinkről beszéltem, Tavali Gábor kollégám pedig a strukturálatlan adatok kezelésének a kérdéséről a Solvonak végzett közbeszerzési témájú feladatunk kapcsán, valamint röviden bemutatta cégünk TAS nevű feldolgozó rendszerét.


A szekció vezetői Feldmann Ádám (PTE Big Data kutatócsoport, ÁOK Magatartástudományi Intézet) és Kruzslicz Ferenc (PTE Big Data kutatócsoport, KTK egyetemi docens) voltak.
Köszönjük a sok érdeklődőnek, aki meghallgatott bennünket, és izgalmas dolgokat kérdezett tőlünk :)

Az előadások után standoltunk és beszélgettünk.


Dálután, az ún. Big Data Labor” workshopot Gazdag András és Katona Richárd kollégáink vezették. És hogy miről volt szó, arról a következő rövid összefoglaló ad képet:
„Mind az újságírás, mint a tudományos munkák, kutatások területén igen fontos szerepe van manapság az Internetnek. Rengeteg releváns információ érhető el a világhálón, de ezek megtalálása, begyűjtése és rendszerezése nem is olyan egyszerű feladat. Ezt a területet célozza meg az adatbányászat, melynek eszközeit és módszertanát egy készülő projektünkön keresztül szeretnénk bemutatni. A project az atlatszo.hu Közhasznú Nonprofit Kft. megbízásából készül és a 2003. évi XXIV. törvény ("Üvegzseb törvény") végrehajtásának monitorozását tűzte ki célul.”

Nagyon szuper és eredményes napot zártunk!
Hálásan köszönjük a rendezvényt és a meghívást a szervezőknek!

 A meetupokat hárman, Nyíri Zsófival és Lázár Bernivel együtt szervezzük a Szegedi Tudományegyetem Bölcsészettudományi Karának épületében.
A meetupokat hárman, Nyíri Zsófival és Lázár Bernivel együtt szervezzük a Szegedi Tudományegyetem Bölcsészettudományi Karának épületében.


 A körülbelül 500 órányi hanganyagon feldolgozása a következő munkafolyamatokból áll: a verbális közlések rögzítéséből, a nem verbális hanghatások kódolásából, valamint egy, a kutatás szempontjából kardinális, szemantikai‒pragmatikai jellegű sajátság jelöléséből. Mindez egy rendkívül komplex feldolgozási folyamattá áll össze, amelytől azt reméljük, hogy a kutatási kérdés, vagyis a pletyka sokrétű és automatikus megoldásokkal hatékonyan támogatott vizsgálatát fogja lehetővé tenni a a jövőben.
A körülbelül 500 órányi hanganyagon feldolgozása a következő munkafolyamatokból áll: a verbális közlések rögzítéséből, a nem verbális hanghatások kódolásából, valamint egy, a kutatás szempontjából kardinális, szemantikai‒pragmatikai jellegű sajátság jelöléséből. Mindez egy rendkívül komplex feldolgozási folyamattá áll össze, amelytől azt reméljük, hogy a kutatási kérdés, vagyis a pletyka sokrétű és automatikus megoldásokkal hatékonyan támogatott vizsgálatát fogja lehetővé tenni a a jövőben.