Közel húsz évvel a Google kereső első helyesírás-ellenőrző rendszerének bevezetése után továbbra is hatalmas kihívás a Cég számára a keresőfelületen begépelt kifejezések (gyakran teljes mondatok) értelmezése.
Problémák a kereséseknél
Mielőtt a Google kereső elkezdhetné keresni a releváns találatokat, először tudnia kell, hogy valójában milyen információ után kutat a felhasználó. Ehhez meg kell állapítani a keresési kifejezések helyesen írott formáját. Ez azonban nem kis feladat, hiszen ezt számos körülmény nehezíti, így többek között az alábbiak:
- a keresések 10%-a hibásan gépelve kerül a keresőablakba
- gyakran több kifejezés együttesével keres a felhasználó
- szinte naponta jelennek meg újabbnál újabb kifejezések
- időről-időre módosulnak a helyesírási szabályok.
Helyesírási hibák
Helyesírási hibáink általában két fő kategóriába sorolhatók: konceptuális és elgépelési hibák. Konceptuális (fogalmi) hibákat akkor követünk el, ha nem vagyunk biztosak abban, hogyan kell az adott kifejezést helyesen leírni, így megpróbáljuk a legjobb "tippünket" használni a keresés során. Az elgépelési hiba pedig természetesen a a számítógépes klaviatúra (billentyűzet) hibás használatából ered. Ilyenkor a "félregépelt" keresési kifejezéssel indítjuk meg a lekérdezést. Az okostelefonok térhódításával egyre gyakoribbá váltak az utóbbi hibák, köszönhetően annak, hogy a számítógépes billentyűzettel összehasonlítva jóval nehézkesebb a gépelés a kisebb "digitális billentyűkkel". A Google többek között ezért is tapasztalt több mint 10 000 különböző téves lekérdezést a YouTube-ra történő kereséseknél. Ezek közül néhány példa: „ytoube”, „7outub”, „yoitubd” és „tourube”.

Jobb modellekkel a sikeres keresésért
Annak ellenére, hogy mennyire gyakoriak a helyesírási hibák a keresés során, sok hibás lekérdezés csak egyszer fordul elő, ezek pedig komoly kihívást jelentenek. Függetlenül attól, hogy milyen helyesírási hibát követett el a felhasználó, a Google keresője rendszerint megtalálja a módját, hogy azt megértse.
Korábban ezeknek a soha nem látott elírások megoldásakor a Google a billentyűzetkiosztást vette figyelembe. Például, ha a felhasználó megpróbálta beírni az „u” betűt, de hibát követett el, akkor nagyobb valószínűséggel írta be az „z” betűt, mint a „v”-t, hiszen az "u" és a "z" szomszédos billentyűk a klaviatúrán. A Google korábbi modellje azt az általános koncepciót alkalmazta, hogy a keresési kifejezésen betűnként haladva számos verziót is vizsgált, tekintetbe véve a lehetséges elgépeléseket. mindezt addig folytatva, amíg be nem azonosította a legvalószínűbb (helyettesítő) kifejezést. Bár ez a megközelítés az elgépelési hibák kiküszöbölését célozta, mégis hatékonyan kezelte a konceptuális hibákat is.
Megoldás az elgépelés problémájára vállalati keresés esetén
Az olyan keresőrendszerek, mint például a Precognox által kifejlesztett TAS Vállalati kereső, rendelkeznek loganalízáló modullal, amelyekkel nyomonkövethetőek az elvégzett lekérdezések, így többek között a találat nélküli keresések. Amennyiben ezek között találunk nyilvánvalóan elgépelt kifejezéseket, akkor ezeket összeköthetjük a helyesen leírt formájukkal, így ha a felhasználó ismét a helytelenül gépelt formátummal keresne, akkor is képes a keresőmotor megjeleníteni a helyes lekérdezésnek megfelelő találatokat.
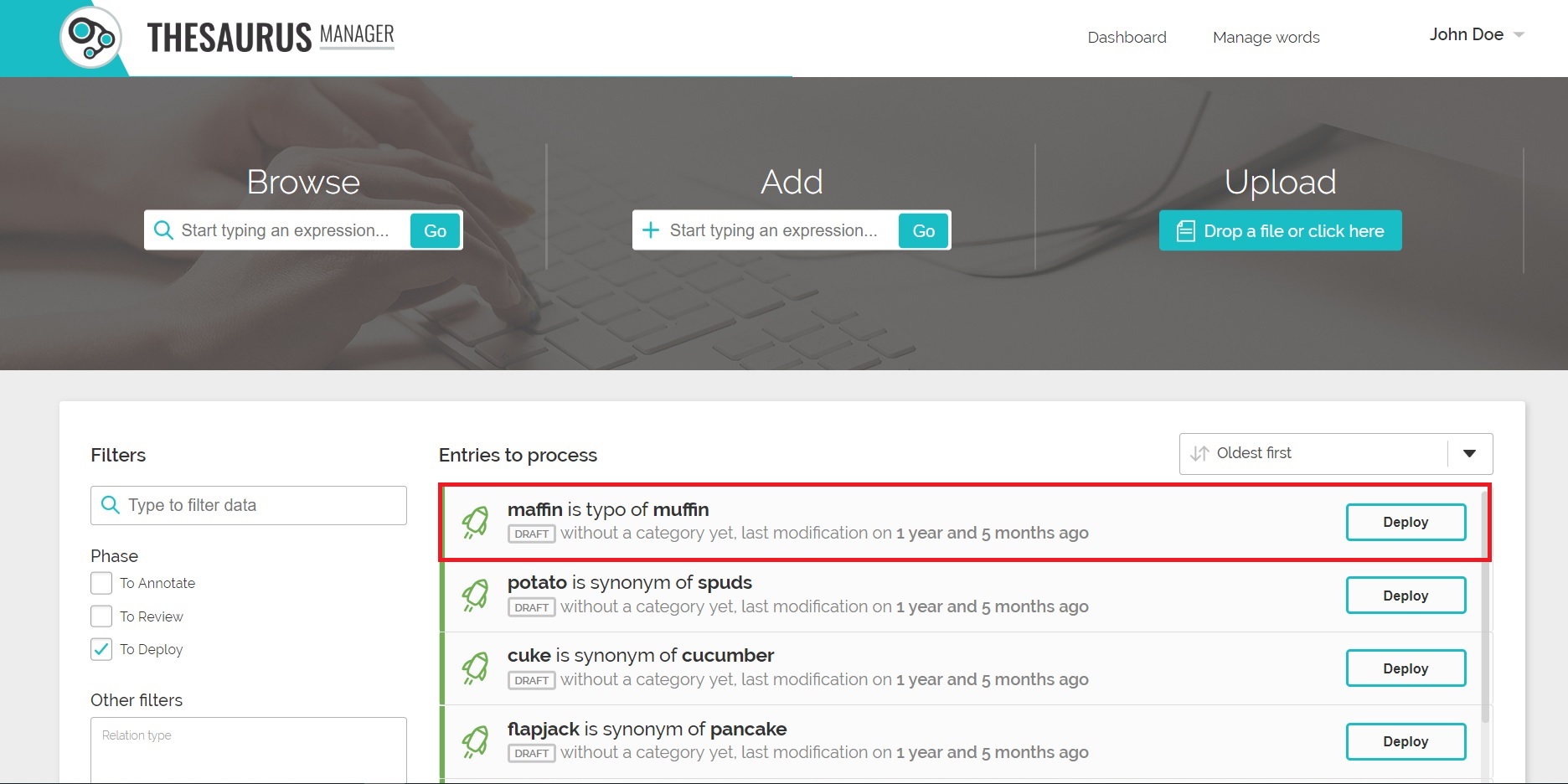
Elgépelés felvétele a TAS Thesaurus Managerben
A gépi mélytanulás terén elért haladásnak köszönhetően ma már hatékonyabb módszert alkalmaz a Google az indított keresések megértésére. A tavalyi év végén került bejelentésre az az új algoritmus, amely mély neurális hálót használ, jobban modellez és ritkán előforduló, illetve egyedi helyesírási hibákból (is) tanul. Ez az előrelépés lehetővé tette a Vállalat számára, hogy több mint 680 millió paramétert tartalmazó modellt legyenek képesek lefuttatni két milliszekundum alatt, így nyújtva zavartalan keresési élményt a felhasználóknak.
És honnan tudják a Google rendszerei, hogy mit keres valaki, még akkor is, ha korábban soha nem látott elírással találkozik a rendszer?
A fenti kérdés megválaszolásakor jön képbe maga a lekérdezés mögött meghúzódó kontextus. A Google természetes nyelvmegértési (NLU - Natural Language Understanding) modelljei összefüggéseiben vizsgálják meg az adott keresést, így például a lekérdezésben szereplő szavak és betűk egymáshoz való viszonyát. Rendszereik azzal kezdenek, hogy először megfejtik vagy megpróbálják megérteni a teljes lekérdezést. Ez alapján generálják a legjobb helyettesítő opciókat a lekérdezésben elgépelt szavakra.
A lekérdezés javítási opciói
A Google Kereső használatakor a rendszer már a keresési kifejezés begépelésekor is ajánlásokkal segít, azonban a felhasználók számos esetben nem élnek ezzel a lehetőséggel. Ilyenkor nagyobb a hibázási lehetőség és szükségessé válhat a lekérdezés javítása, módosítása.
A lekérdezések lehetséges javítási formái különböző módokon jelennek meg a Google Keresőben. Amikor eléggé biztos az algoritmus abban, hogy mit keres a felhasználó, és szinte nyilvánvaló, hogy elgépelés történt, akkor udvariasan megkérdezi: "Erre gondolt?", és egyúttal megmutatja azt az alternatívát, amelyet szerinte keresni szerettünk volna. Amikor teljesen biztos a rendszer abban, hogy helyesen azonosította az elírási hibát, automatikusan megjeleníti a találatokat annak alapján, amit az összeállított lekérdezés kontextusba helyezése után az algoritmus helyesnek ítélt meg. Ebben az esetben a lekérdezés korrigálásáról azonban mindig tájékoztatja a felhasználót, és módot kínál arra, hogy visszatérjen az eredetileg begépelt (összeállított) kereséshez és azt futtassa.
Tehát a Google a fent leírt módszerek segítségével “tudja”, hogy valójában mit keres a felhasználó. Természetesen a tanúsított felhasználói viselkedés és a futtatott keresések alapján a Google folyamatosan fejleszti keresőrendszerét a felhasználói élmény és a hatékonyság érdekében. Éppen ennek a folyamatosan fejlődésnek köszönhetően érezzük egyre gyakrabban azt, hogy a Google valójában tudja, mit is keresünk.
Amennyiben többet szeretne a témáról megtudni, kérjük olvassa el a Pandu Nayak tollából származó cikket, amely a Google Blog oldalán jelent meg, és amely jelen blogbejegyzésünk alapjául szolgált.