A Tilburgi Egyetemre írt tézisem angol címe Grounded Learning for Source Code Component Retrieval és erről fogok mesélni röviden ebben a posztban. Az alapötlet a konzulensem Grzegorz Chrupala és előző tanítványa Jing Deng közös munkájából származik, ahol különböző szokatlan modelleket alkalmaznak forráskód keresésre. Több poén is van a munkájukban. Az egyik az, hogy source code component-ek vagyis forráskód komponensek között keresnek, ami újdonságnak számít, a másik pedig, hogy a keresést, mint fordítási problémát fogják föl programnyelvről természetes nyelvre. Alapvetően két oldala van a történetnek: egyrészt a cél az, hogy létrehozzunk egy kereső motort, ami forráskód komponensek között keres, másrészt, hogy fogjuk meg a természetes-nyelvi kifejezések jelentését valamilyen formális nyelvvel, jelen esetben forráskód komponensekkel. Az első ponttal még egyet is lehet érteni, a kereső motorok jók, mert keresnek, de minek “belegroundolni” a természetes-nyelvi kifejezéseket forráskódba? A rövid válasz az, hogy fölösleges, de ha valakit érdekel a hosszabb magyarázat olvassa tovább a posztot.
A nyelvészet különböző szinteken elemzi a nyelveket: a fonológia foglalkozik a hangokkal, a morfológia nagyobb, hangokból álló és jelentéssel rendelkező egységeket kutat, a szintaxis több jelentéssel bíró egységből - mondjuk szavakból - álló szerkezetekkel foglalkozik, a szemantika pedig a különböző nyelvi egységek jelentését kíséri meg leírni. A tézisem a szemantika témakörébe tartozik, hiszen a kifejezések jelentésével kapcsolatban barkácsolok. Eszméletlenül sok szemantikai elmélet írja le a jelentés különböző aspektusait, de alapvetően két fontos témát boncolgatunk már több ezer éve:
1.) Hogy kötődnek a nyelvi kifejezések a külvilághoz?
2.) Milyen kapcsolatban állnak egymással?

A disztribúciós szemantika a második kérdéssel foglalkozik. Már számtalan cikk jelent meg a disztribúciós technikákkal kapcsolatban a blogon, de az alap ötlet az, hogy a szavak jelentése a kontextus függvénye. Firth (1957): "You shall know a word by the company it keeps". A disztribúciós technikák nagy előnyei, hogy nem igényelnek annotációt, átlátható és elég általános matematikai modelleken nyugszanak, nem bonyolult az implementációjuk, rahedli könyvtár létezik hozzájuk, sokrétűen és hatékonyan használhatóak. A tézisem egyik fő problémája tulajdonképp az, hogy ezeket a modelleket, hogy lehet úgy csűrni-csavarni, hogy valamilyen módon az 1-es kérdésre adjanak választ.
A nyelvi kifejezéseket a szemantika hagyományosan a következőképp képezi le a nyelven kívüli valóságra: A kifejezéseket valamilyen logikai formulákkal reprezentálja és ezeket a formulákat matematikai modellekre értelmezi pl.: halmaz elmélet, kategória elmélet. Az ötlet Grzegorz Chrupala és Jing Deng munkájában az, hogy a logikai formulákat cseréljük le programnyelvi kifejezésekre, amik alatt amúgy is van modell és így tulajdonképp egy fordítási problémára redukáltuk a természetes-nyelvi kifejezések megalapozását. A fordítási problémákat pedig egy elég egyszerű ötlettel szokás megoldani: paralell-corpussal. A lényeg az, hogy keresünk egy corpust, ahol az X nyelven megfogalmazott gondolatok és azok Y nyelvi megfelelői össze vannak párosítva. Egy ilyen paralell-corpuson megint csak a disztribuciós alapvetésünket vetjük be csak ez esetben nem nyelv-internálisan, hanem nyelvek között tételezzük fel azt, hogy hasonló kontextusban szereplő szavak jelentése hasonló. Esetünkben olyan paralell-corpust kell találnunk, ami a természetes-nyelvi megnyilatkozások és azok programnyelvi megfelelőjét tartalmazza.
Úgy gondoltuk, hogy erre a célra kifejezetten jó parallel-corpust nyújtana egy programnyelv különböző könyvtárainak dokumentációja. A Java Standard Library-t használtuk és az úgy nevezett method-signature-k szolgáltatták a programnyelvi kifejezéseket míg azok leírásai az angol nyelvi megfelelőjüket. A szokásos előfeldolgozási lépesek után - pl.: stemming, funkciószavak kiszűrése - meg is volt a data set, amire lehet illeszteni egy modellt, amely képes Java method-signature-ket angolra fordítani. Grzegorz Chrupala és Jing Deng az IBM model 1-t és a PLDA modelleket alkalmazza fordító modellként, ami nem meglepő, hisz az előbbi egy gépi-fordításra, míg az utóbbi nyelvek közti dokumentum keresésre alkotott modell.
Chrupla és Deng munkájában tetszett, hogy ilyen un-orthodox módon fordítással keresnek ráadásul ilyen fura dolgok között, de egy igaz magyar un-orthodox fordító modelleket is használ! Az én olvasatomban ez a "bag-of-words fordítás" a regresszió probléma körébe tartozik, hiszen ha az angol leírásokat és azok method-signature megfelelőit tf*idf mátrixokban ábrázoljuk egyszerűen regressziós modellt illeszthetünk a két vektor-térre, ahol a bemenet a deskripció-vektor és a cél pedig a hozzá tartozó method-signature vektor. Több modellt is kipróbáltam, de a Ridge-regresszió teljesített a legjobban megverve a PLDA-t és azért viszonylag alul múlva az IBM modell 1-t. Szerintem az alábbi táblázatban az Acc@10 a legfontosabb mutató, azt mondja meg, hogy az esetek mekkora részében adja vissza a rendszer a megfelelő találatot az első kereső oldalon.
| MRR | Acc@1 | Acc@10 | |
| Ridge | 0.39 | 0.23 | 0.71 |
| PLDA | 0.35 | 0.24 | 0.56 |
| IBM model 1 | 0.49 | 0.34 | 0.79 |
De mint említettem nem kizárólag az volt a cél, hogy írjak egy fura keresőmotort, hanem hogy hozzájáruljak a ma még gyerekcipőben járó Grounded Learning módszertanához. Arra voltam kíváncsi, hogy a Java terminusok mennyire tudják megragadni az angol kifejezések jelentését egy ilyen regressziós fordítás során és hogy mindezt, hogy lehetne letesztelni. Végül úgy döntöttem, hogy neurális hálót használok a kísérletezgetéshez méghozzá több szintes neurális hálót azaz Multilayer Perceptront, ami a projektem szempontjából azért érdekes, mert a köztes (rejtett) szinteken érdekes absztrakt reprezentációt tanulhat a nyelvi adatokból.
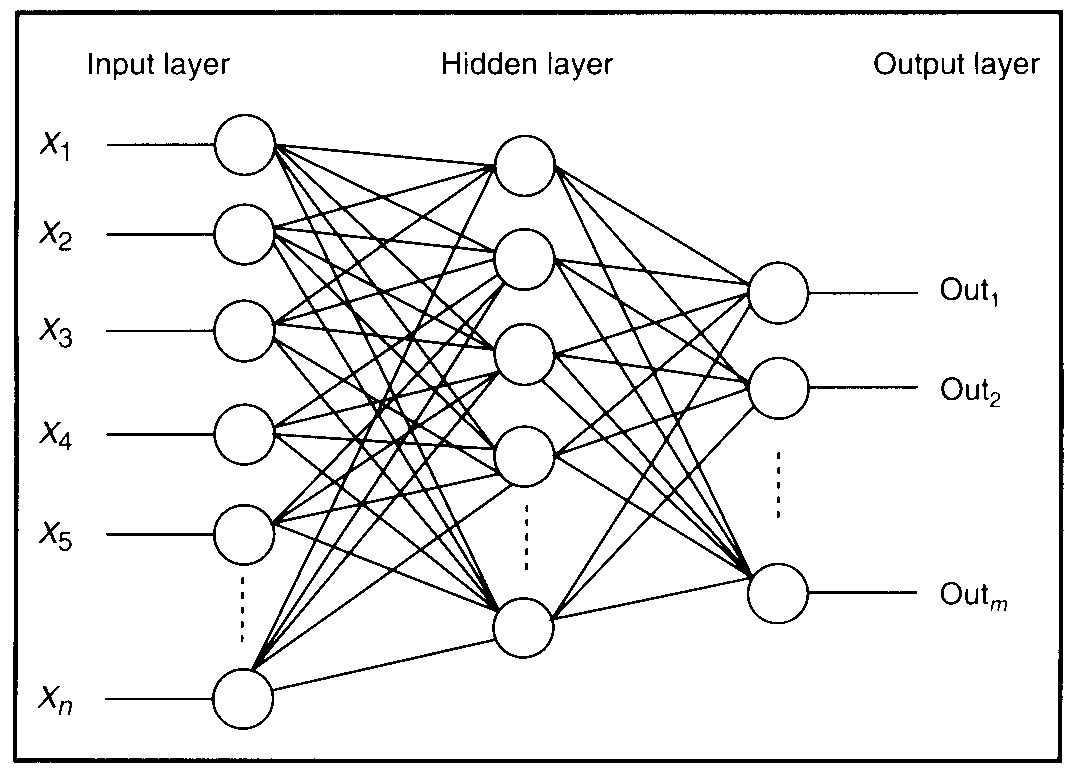
Ahogy a fentiekben már ecseteltem a képen illusztrált neurális háló is tf*idf deskripció-vektorokból tanul meg jósolni tf*idf method-signature-vektorokat. Hogy szemléletes legyek a háló baloldalán van az Angol-tér, a jobb oldalán a Java-tér és ott középen vagyunk a nyelvek között. Az volt az ötletem, hogy csinálok a deskripció összes szavához one-hot-encodinggal szó-vektort (jó sok 0 és egyetlen 1-es a szó indexének helyén) és ezekből kapott mátrixokat "beágyazom a háló közepébe". A poén az, hogy one-hot-encodinggal a szavak közti kapcsolatok nincsenek reprezentálva, de ha a tanulás során az angol kifejezések jelentését valamennyire megfogtuk Java terminusokkal, akkor a beágyazott szó-vektorok esetében azt várjuk, hogy a hasonló szavak vektora hasonló helyen helyezkedjen el (hasonló irányba mutasson) a beágyazott vektortérben. Szerencsére teljesült a kívánságom, alább mutatok pár példát az így kapott szólistáimból.
| zip | currency | cos | true | yyyy |
| compressed | symbol | argument | whether | sep |
| compression | represent | trigonometric | boolean | oct |
| checksum | territories | cosine | equality | nov |
| uncompressed | countries | angle | false | mm |
Ahogy láthatjátok tényleg "összeklasztereződtek" a hasonló szavak, ami azt jelenti, hogy valamit elcsíptünk az angol szavak jelentéséből Java terminusokkal. Kicsit másképp megfogalmazva: a poén az, hogy a neurális hálóba ágyazott szó-vektorok egész reálisan reprezentálják az angol szavak egymás közti viszonyait, de ezt nem úgy értük el, hogy megfigyeltünk angol szövegeket, hanem azok viszonyát figyeltük meg rajtuk kívül eső dologhoz.
Ez mind tök király és cum laude is lett a vége, de nem árultam a poszt elején zsákbamacskát és így a vége felé is nehéz lenne megmondanom, hogy valójában mi értelme volt az egész vállalkozásnak. Amikor elkezdtem írni a szakdogát teljesen nyilvánvaló volt, hogy itt nagy dolgok vannak készülőben, kis idő távlatából azonban inkább egy ilyen "Rube Goldberg search engine avagy a keresőmotor a modern lélek tükre" című installációnak látom az Ernst múzeum egyik ingyenesen látogatható kiállításán. Mindenki döntse el maga mit gondol. Az egész rendszer az adatokkal együtt elérhető egy publikus repóban, mert azért a reproducable research az igazi party.