Tempfli Péter, a Számítógépes nyelvészet blog egyik szerzőjének vendégposztja
A Yandex a világ nyolcadik, Oroszország legnagyobb keresője – bár helyesebb talán “az orosz nyelvű internetről” beszélni (RUNET), mert az egész oroszul beszélő világban használják. Sokat mondó a tény, hogy a hazai – orosz nyelvű – pályán megveri a Google-t: a Yandex a piac 64 százalékát tudja magáénak, míg az amerikai vállalat 21 százalék felett rendelkezik.
Mit tud a Yandex?
Gyakorlatilag mindent, ami egy keresőtől elvárható. Hasonlóan adhatunk meg bonyolult keresési kifejezéseket, mint a Google-nél. Hasonlóan használhatók az idézőjelek, plusz- és mínusz jelek; ezenkívül megadhatunk * szimbólumot (bármilyen szó), beállíthatjuk, hogy két szó között pontosan hány szó forduljon elő, és megadhatunk “vagy” operátort is. Mivel az orosz erősen ragozó (egész pontosan: flektáló) nyelv, fontos szerepet játszanak a szóformák. Alapbeállításként a szavak összes ragozott változatára keres, vagyis nincs jelentősége hogy orosz nyelven a “tea” vagy a “teával” formát adjuk meg. Ha azonban fontos a szóforma, eléírhatunk egy felkiáltójelet, és úgy fog viselkedni, mintha időzőjelek között lenne. Ha pedig egy ragozott forma szótári alakját szeretnénk kikerestetni, akkor két felkijáltójellel utasíthatjuk erre a programot. Egyébként, a ragozott formák közti keresést a Google is tudja, de a keresési kifejezések megadásánál sokkal rugalmasabb a kifejezetten orosz nyelvre kihegyezett Yandex.
A kevesebb több?
A Google többi trükkjét is ismeri az orosz keresőmotor: képeket, videókat, térképet, fordítást, illetve az utóbbi idők slágerét is, a keresési kifejezések automatikus kiegészítését (autocomplete). A Yandex néhánnyal több ajánlatot ad, és szubjektív értékelésem szerint egy kicsivel pontosabb, abban az értelemben, hogy “oroszosabbnak” tűnnek a javaslatok. Egyébként, a Yandex keresési találatai is jobbnak tűnnek időnként, jobbak leképezik az orosz nyelvű internetet. Például, a Google a “социальная сеть” (szociális háló) keresésre gyakorlatilag csak a filmről ad információt, a Yandex pedig elsőként a legnagyobb orosz közösségi oldalt (Vkontakte.ru) adja, azután kapunk Wikipedia-cikket, a filmről némi információt, és a többi orosz közösségi oldal is megjelenik az első 10 találatban. Ez talán azzal magyarázható, hogy a Google adatbázisában az egész világ adataival kell versenyeznie a helyi oldalaknak, míg “hazai pályán” a globálisan nem olyan releváns oldalak is magas helyezést érhetnek el. Ezek szerint, a kevesebb néha talán mégis több? (hozzá kell tenni azt is, hogy a Yandex által indexelt orosz oldalak száma felveszi a versenyt a Google orosz nyelvű adatbázisával)
Keresési extrák
Jópofa, és a Google-nél is létező szolgáltatás az különféle “extrák” beépítése a keresésbe, ha az releváns, pl. térkép, szótár vagy devizaárfolyamok. Tőzsdei, időjárás, földrajzi és hasonló “magától értetődő” dolgokat a Yandex is tud, ezen kívül időnként aranyos, időnként pedig hasznos egyéb trükköket is be tud mutatni. Például, jó pontossággal ismeri fel, ha verssorokra keresünk, és egyből adja is az egész szöveget. Ha megszomjazunk és valami alkoholos italra vágyunk, egyből koktélreceptekkel siet a segítségünkre a program. Ha beütjük, hogy “мой айпи”, vagyis: “az én áj-pím”, akkor az IP-címünkről és a kapcsolatunk sebességéről kapunk információt, amennyiben pedig a városunkban aktuális nyári víz-elzárásokról szeretnénk valamit tudni, akkor is egyből megkapjuk a választ (ez utóbbi nagyon gyakori orosz reália!).
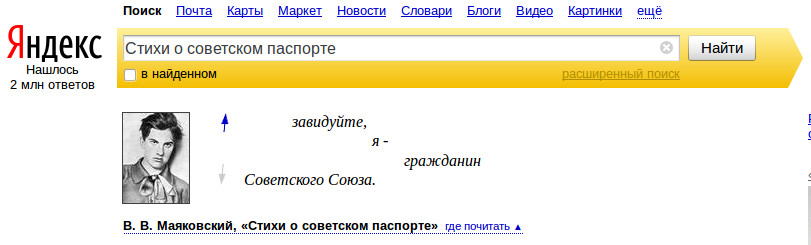
Majakovszkij: Vers a szovjet útlevélről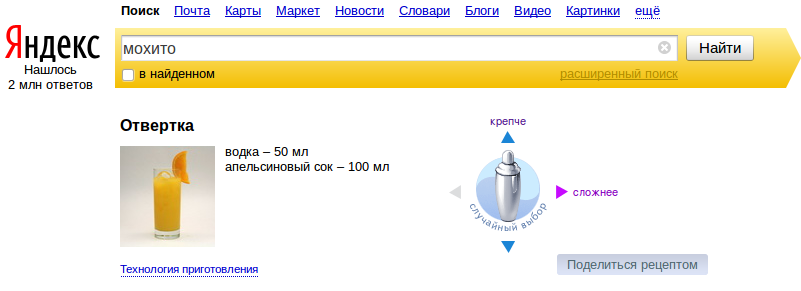
A “Dugóhúzó” koktél. Jobbra az iránytűvel bonyolultabb és/vagy erősebb italt is kérhetünk.
Talán egy kicsit magukra is gondoltak a fejlesztők, amikor beépítették a keresőbe a nagyobb programozási nyelvek főbb funkcióinak a leírását – a “python sorted” kifejezés első találata egyből megadja a kifejezés szintaxisát és az alapvető tudnivalókat. A nyelvek listája imponáló: Perl, PHP, PostgreSQL, Python, C/C++/STL, Win32, Java, HTML/CSS/JavaScript, MySQL.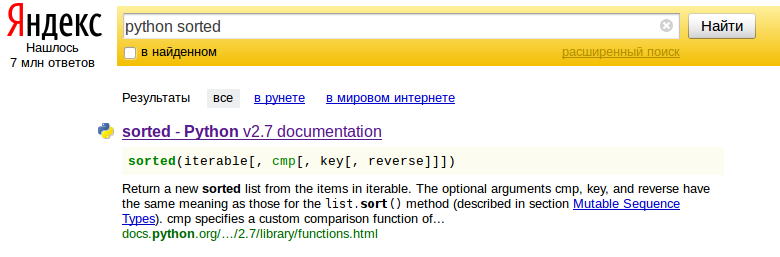
A kémiai elemekről információt adó szolgáltatás talán nem túl érdekes, annál inkább az időt megmondó. Az még nem túl meglepő, hogy a “время” (idő) szó megadására megadja a helyi időt, az már kicsit izgalmasabb, hogy a kérdést feltehetjük többféleképpen: Hány óra van? Mennyi az idő? A “Разница во времени между Москвой и Будапештом” – “A különbség a Moszkvai és a Budapesti idő” kifejezést is tudja értelmezni a gép, amiben az az érdekes, hogy ehhez fel kell ismernie a városnevek ragozott formái.
Utazás a Matrix(net) mélyére
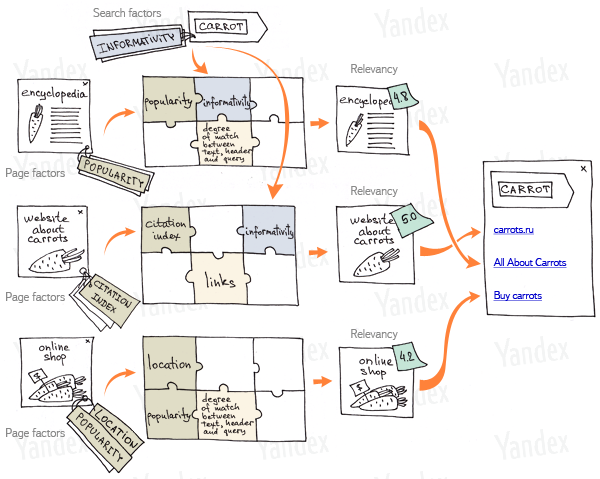
A Yandex-nek Californiában található a Yandex-Labs nevű kirendeltsége, itt foglalkoznak a keresési technológiák és kapcsolódó területek (nyelvi feldolgozás, gépi tanulás)kutatásával. Itt fejlesztik a Yandex mélyén futó Matrixnet-algoritmust is, ami a találatok rangsorolásáért felel. Ez az eljárás nem egy szimpla formulán, hanem a különböző faktorok dinamikus rangsorolásán, illetve a korábbi keresési eredmények sikerességéből való statisztikai tanuláson alapul. A fő érdekessége abban rejlik, hogy maga az algoritmus minden keresésnél változik, úgy, hogy hozzáigazodjon mind a keresési kifejezéshez, mind a találatok természetéhez.
Ez alatt körülbelül azt kell érteni, hogy a gép figyelembe veszi, hogy mondjuk egy városnévre vagy egy programozási nyelv funkciójára kerestünk, és a kapott eredmények tartalmát is átnézi, mielőtt a végső rangsorolást létrehozná. Például elképzelhető, hogy bizonyos kereséseknél jobban számít a hivatkozások száma egy találat relevanciájánál, míg más fajta kereséseknél fontosabb a többi felhasználó véleménye az adott dokumentumról. Ezen kívül, felügyelt gépi tanulást is beépítettek a rendszerbe, ami azt jelenti, hogy emberi erőforrással készítenek mintákat a “jó” találatokból, és ezek alapján finomítja az algoritmus a találatokat.
A fenti technika tehát abban tér el pl. a Google keresésétől, hogy nem csak a találatokat szabja személyre, de magát a kiinduló formulát is (ez a Google esetében a PageRank algoritmus). Formula persze nyilvánvalóan a Yandexnél is van, de ez a saját bevallásuk szerint rendkívül hosszú és bonyolult, rengeteg paraméterrel, amelyek változtatásával minden keresésnek gyakorlatilag önálló algoritmust jön létre.
Végül, az is tudható a Yandexről, hogy a hatalmas mennyiségű adat miatt a keresések párhuzamosan zajlanak az index különböző részein, az eredmények pedig egy végső lépésben kerülnek összefésülésre. A Yandexnek, mint a többi más keresőnek is, nincs központi szervere, sem központja, hanem a gépek több data-centerben vannak elhelyezve. Sokak számára valószínűleg nem meglepő az a tény sem, hogy a Yandex munkatársai többségének fogalma sincsen arról, hol találhatók a gépek.
Forrás: http://company.yandex.com/technologies/matrixnet.xml
A Yandex egyik data-centere
Angol nyelvű leírás a Matrixnet technológiáról:
http://company.yandex.com/technologies/matrixnet.xml