Az utóbbi hetekben szorgosan készülünk a magyar politikai blogok elemzésére. Elkészült egy kis crawler, ami begyűjtötte nekünk az adatokat, majd rávetettük magunkat gráfokra és a rengeteg szövegre, tekintsük ezt tesztüzemnek, amiről be is számolunk kedves olvasóinknak.
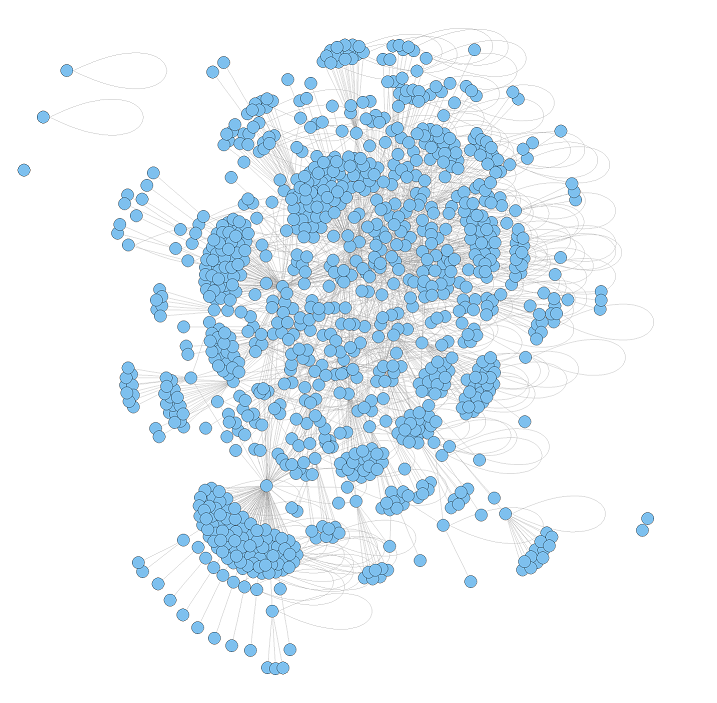
Az adatok begyűjtése
Crawler-ünk Toby Segaran Programming Collective Intelligence c. könyvének negyedik fejezete alapján készült Pythonban. Mivel a kötet már hét éves és azóta történt egy-két dolog a Python nyelvvel és a használt SQLite adatbázissal is, kénytelenek voltunk leporolni egy kicsit a kódot, ill saját igényeinek megfelelően módosítottunk is rajta. Pl. nem egy egész oldalt szedünk le, hanem csak a tartalmilag releváns részt (vizsgálódásunk ebben tér el leginkább a "hagyományos" webes tanulmányoktól, minket ugyanis csak az érdekel mire hivatkoznak a bloggerek és a politikai témákban érintett egyéb szerzők, az egész oldalt nem vizsgáljuk) és elmentjük a linkek szövegkörnyezetét is (hogy később megvizsgáljuk milyen ezen hivatkozások polaritása, emóciója, stb).
Egy ötven, magyar politikai blogot tartalmazó ún. seed lista alapján indult el crawlerünk és hármas mélységben gyűjtött be minden linkelt oldalt. A gyűjtés eredménye 10785 oldal, melyek között 155182 link található.
Az adtok előkészítése
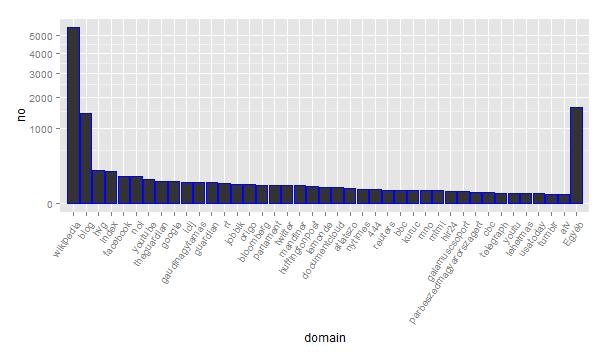
Az 10785 oldal egyedi url-t takar, ezeket top-level domain-re (tld) normalizálva az egyes doménekbe tartozó oldalak eloszlása azt mutatja, itt is érvényesül a webes topológiára jellemző hatványfüggvény eloszlás. A legtöbb oldalt tartalmazó tld-kről az alábbi ábra ad egy kis infót.
Az eredeti gráfunkat nem irányítottként elemezve a legrövidebb utak átlagos hossza 8.024154, a gráf átmérője pedig 31. Természetesen a gráf nem összefüggő.
Mivel a tld nem túl informatív (a blog.hu takarja például a számunkra legérdekesebb blogokat), az ún. pay-level domain-re (pld) normalizáltuk az url-eket. (Pl. blogunk a http://keres.blog.hu tld-je a blog.hu, a pld-je pedig a kereses.blog.hu) Az alábbi grafikon mutatja mely pld-kről származik a legtöbb url.
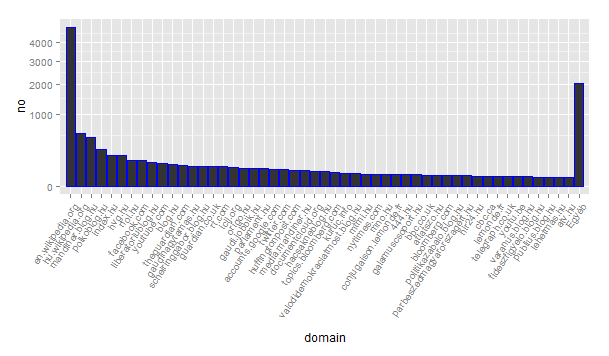
Az adatok begyűjtését és normalizálását Python-ban végeztük, majd az igraph által is olvasható gráf formátumra konvertáltuk azokat, hogy az általunk megszokott R környezet segítségével végezhessük elemzésünket. Az url-ek normalizálása után 1002 pld-ből és a közöttük lévő 1835 kapcsolatból álló gráfot kaptunk, ami nem összefüggő, a legrövidebb utak átlagos hossza 3.609506, átmérője pedig 7. A pld-k kódja megtalálható ebben a táblázatban.
A normalizált gráf főbb jellemzői
Jelen posztban a gráfot mint egy nem-irányított gráf jellemezzük, azaz nem teszünk különbséget az A-ból B-be és vissza mutató linkek között.
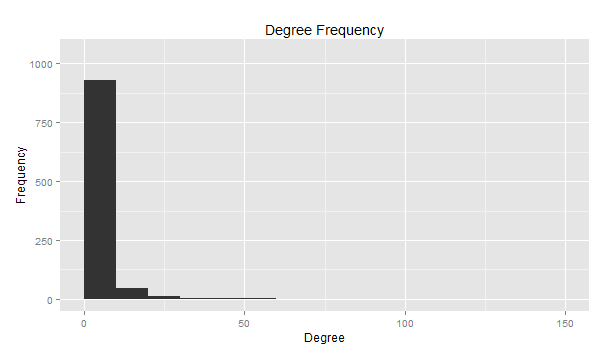
Az egyes oldalak fokszáma alacsony, a legtöbb egy és tíz közöttivel rendelkezik.
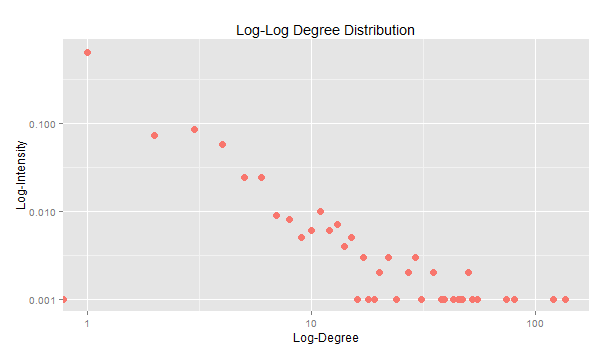
Logaritmikus skálán talán jobban érzékelhető hogy a legtöbb oldal fokszáma alacsony.
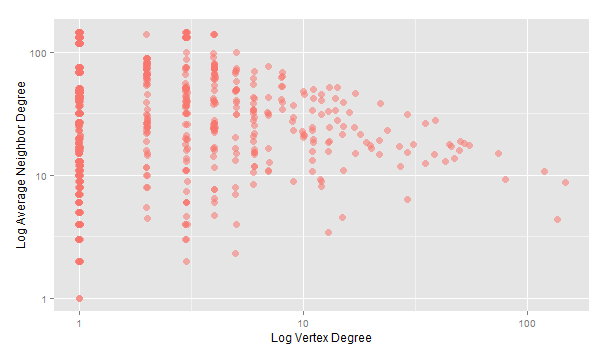
A szomszédosság foka (azaz hogy hány másik oldalhoz kapcsolódik az adott oldal) és a fokszám log plotja is a szakirodalomban megszokott képet rajzolja ki.
Topológia
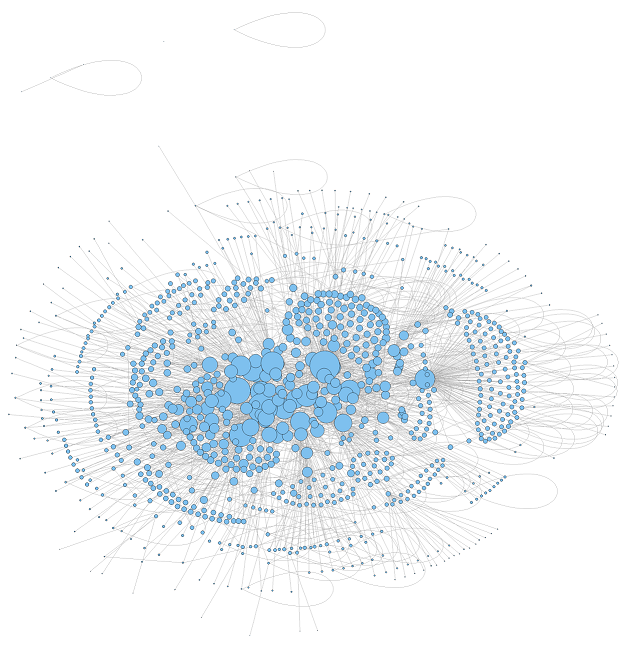
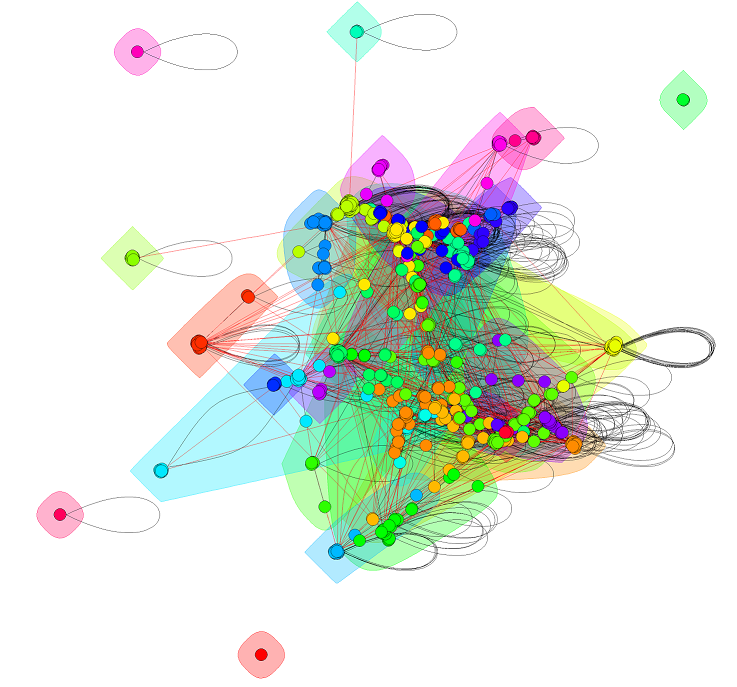
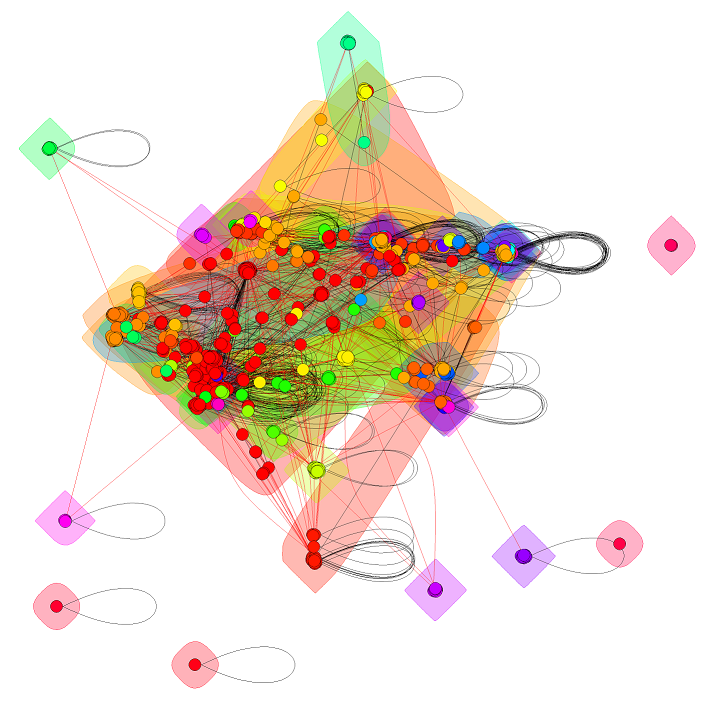
A nem-irányított gráffal elsődleges célunk csupán az egyes vizualizációs lehetőségek kipróbálása volt, de ez is egy kis betekintést enged az adatok mögötti struktúrába. Az egyes képek nagyobb, a csomópontokhoz tartozó kódokat is megjelenítő változatai itt találhatók (a kódokat pedig a fentebb említett táblázat segítségével tudja feloldani).
A HITS algoritmus segítségével a "legforgalmasabb" csomópontokat tudjuk azonosítani egy gráfban, azaz azokat, melyek olyan élek mentén fekszenek, amik sok más csomópont felé nyújtanak elérést (amúgy ez a módszer a PageRank elődje!)
A HITS-hez hasonló módszer az ún. edge betweenness segítségével próbáltuk meg klasszifikálni az egyes csomópontokat.
Majd a walktrap módszerrel is tettünk egy próbát.
Kérdések, tanulságok
Habár a 10785 oldal soknak tűnik, sajnos nagyon kevés a magyar nyelvű tartalom rajtuk. Minden linket megvizsgálva azt találtuk, hogy csupán 3877 darab azonosítható úgy mint magyar. A linkek struktúrája azt mutatja, hogy nagyon hamar eljuthatunk külföldi oldalakhoz, ezért a crawler mélységét növelni nem célszerű (no meg arról nem is beszélve, hogy ezzel a linkek száma exponenciálisan nőne), marad tehát a seed lista bővítése.
Kapott gráfunkat már most is nagyon szeretjük, de a puszta deskriptív jellemzésénél többre vágyunk. Szeretnénk összekapcsolni a hálózatelemzést a tartalomelemzéssel. Eltér-e a nyelvezete a baloldali bloggernek a jobbosétól? Milyen témákkal/topikokkal foglalkoznak a blogok? Időben és térben hogyan jelennek meg az egyes topikok a blogokon? Nagy kérdések, könnyen lehet hogy megválaszolatlanok maradnak, de azon vagyunk hogy olvasóinknak beszámoljunk kalandozásainkról. Hamarosan foly.köv.!