Collecta
Ez egy viszonylag új, még béta-állapotú szolgáltatás, amely a real-time (vagyis: valósidejű) keresők közé tartozik. A közvetlen üzenetváltásra kidolgozott XMPP protokollt használja arra, hogy gyorsan változó, frissülő tartalmakat gyűjtsön össze különböző blog, mikroblog, kép- és videomegosztó, valamint közösségi szerverekről. A Collecta gyakorlatilag másodperceken belül kereshetővé teszi az ezeken megjelenő újdonságokat, és nem relevancia szerint, hanem időrendben adja a találatokat, egy folyamatosan frissülő listában. Egészen más módon működik tehát, mint a hagyományos keresők: nem arra szolgál, hogy megtaláljunk valamilyen információt/témát, hanem hogy figyelemmel kísérjük, hogy egy adott témával/eseménnyel kapcsolatban éppen most mi történik a világban.
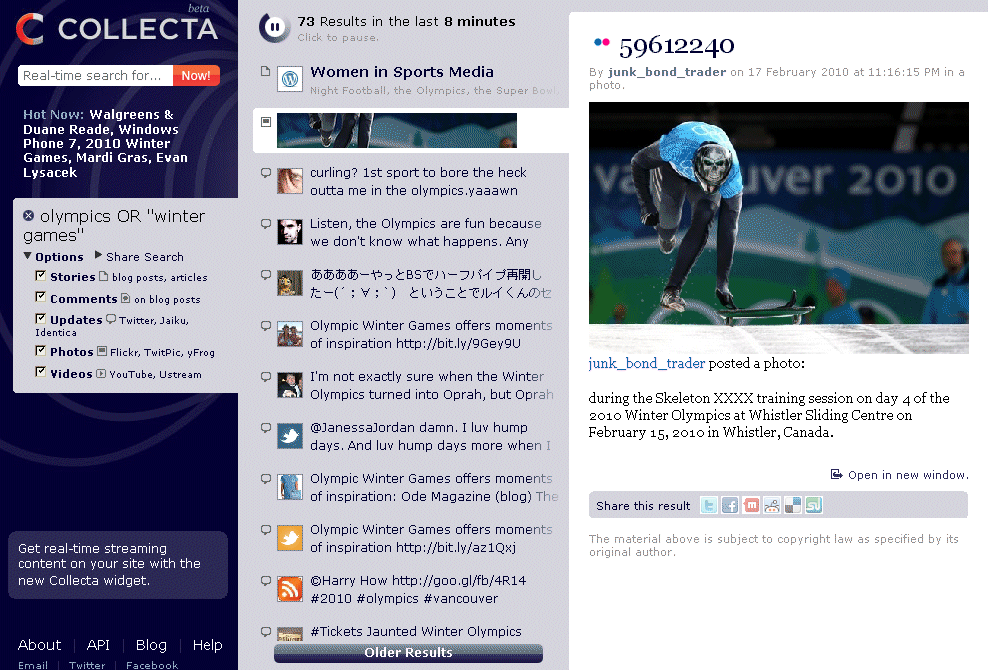 A kezdőlapon az aktuálisan legnépszerűbb témák közül válogathatunk, vagy beírhatjuk a keresőkérdésünket. (A korábbi kérdéseink megmaradnak a keresősor alatt, így később is előhívhatók.) A keresés elindítása után a bal oldali panelen kapcsolhatjuk ki és be, hogy milyen típusú forrásokra vagyunk kíváncsiak, a középső oszlopban pedig elkezdenek sorjázni a találatok. Ha túl gyorsan jönnek, akkor a pause gombbal megállíthatók, majd újraindíthatók és visszagörgetésre is van lehetőség az Older Results gombbal. A jobb szélső hasábban pedig magát az üzenetet, blogbejegyzést, vagy képet láthatjuk, amennyiben rákattintunk valamelyik találatra. Ezt azután egy-két kattintással meg is oszthatjuk másokkal a legnépszerűbb közösségi site-okon (pl. Facebook, Delicious).
A kezdőlapon az aktuálisan legnépszerűbb témák közül válogathatunk, vagy beírhatjuk a keresőkérdésünket. (A korábbi kérdéseink megmaradnak a keresősor alatt, így később is előhívhatók.) A keresés elindítása után a bal oldali panelen kapcsolhatjuk ki és be, hogy milyen típusú forrásokra vagyunk kíváncsiak, a középső oszlopban pedig elkezdenek sorjázni a találatok. Ha túl gyorsan jönnek, akkor a pause gombbal megállíthatók, majd újraindíthatók és visszagörgetésre is van lehetőség az Older Results gombbal. A jobb szélső hasábban pedig magát az üzenetet, blogbejegyzést, vagy képet láthatjuk, amennyiben rákattintunk valamelyik találatra. Ezt azután egy-két kattintással meg is oszthatjuk másokkal a legnépszerűbb közösségi site-okon (pl. Facebook, Delicious).
A Collecta egy widget-et is biztosít, így egy folyamatosan működő "hírügynökséget" építhetünk be a weblapjainkba, mely az általunk megadott témában percrekész információkat szállít.
Europeana
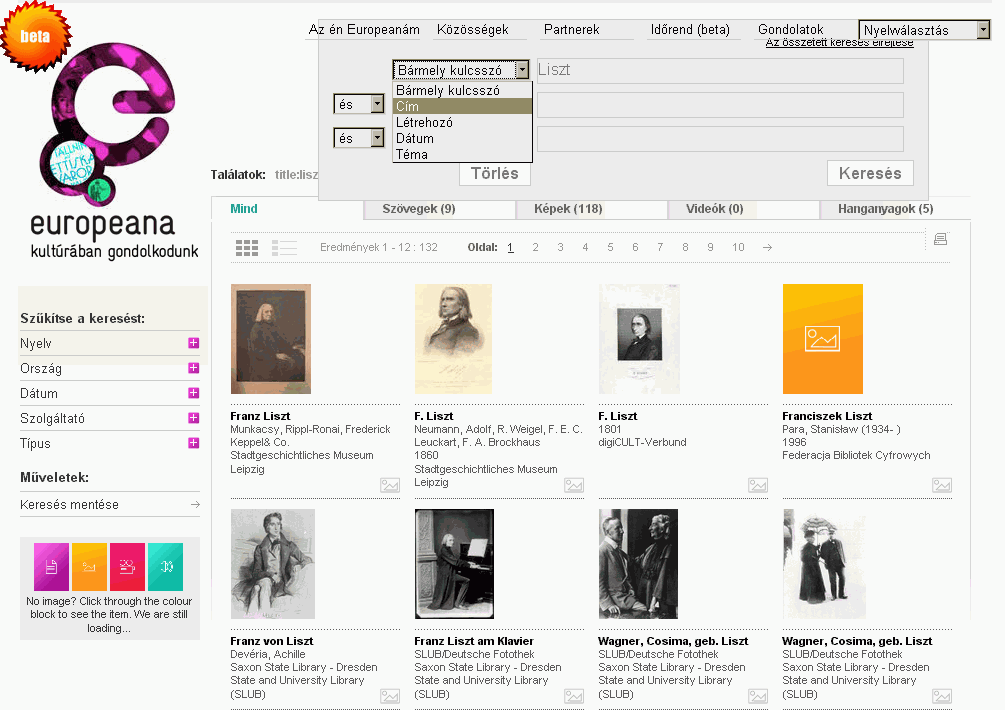 Az "Európai Digitális Könyvtár" néven is emlegetett szolgáltatás 2008. november 20-án nyílt meg, azzal a céllal, hogy egy helyen tegye elérhetővé az európai uniós országok kulturális és tudományos jellegű digitális dokumentumainak minél nagyobb részét.
Az "Európai Digitális Könyvtár" néven is emlegetett szolgáltatás 2008. november 20-án nyílt meg, azzal a céllal, hogy egy helyen tegye elérhetővé az európai uniós országok kulturális és tudományos jellegű digitális dokumentumainak minél nagyobb részét.
A Europeana az OAI protokollt használja arra, hogy összegyűjtse a különböző digitális gyűjtemények (rendszerint Dublin Core alapú) metaadatait - tehát magukat a dokumentumokat nem gyűjti be és nem indexeli le, mint a szokásos webkeresők, hanem csak azok leíró adatait, majd pedig linkekkel kapcsolja hozzájuk a dokumentumokat az őket szolgáltató eredeti szerverekről.
Mivel jelenleg csak a partnerként csatlakozott közgyűjtemények - rendszerint gondosan elkészített - rekordjait "aratja le", ezért nagyon jó találatokat ad - igaz jóval kisebb halmazból mint az általános webes keresők. 2010 elején a katalógus kb. 6 millió dokumentum adatait tartalmazta, ezt még ebben az évben 10 millióra tervezik növelni. A kínálat a könyvtárak, levéltárak, múzeumok és audio-vizuális archívumok gyűjtőkörét tükrözi, nagyrészt már nem jogvédett, régi anyagok közt lehet itt válogatni.
A keresőfelület 26 nyelven áll rendelkezésre, köztük magyarul is. A kezdőlapról elérhető gyorskereső valamennyi adatmezőben keres, így meglehetősen "zajos" találatokat ad. Az Advanced search űrlap már több lehetőséget kínál: mezőszűkítés, logikai műveletek, kifejezések keresése idézőjelek közt (joker-karakterek nem használhatók sajnos). A találati listánál nyelv, ország, dátum, szolgáltató és dokumentumtípus (szöveg, kép, videó, hang) szerint lehet tovább szűkíteni a halmazt.
Ha regisztráljuk magunkat, akkor a My Europeana menüpont alatt belépve lehetőségünk van elmenteni kereséseket, illetve a számunkra fontos tételeket könyvjelzővel vagy címkékkel ellátni. A ThoughtLab feliratra kattintva egy fejlesztés alatt levő szemantikus keresőt is kipróbálhatunk, melynek adatbázisa jelenleg három múzeum mintegy 140 ezer képét tartalmazza, és a találati eredményeket képes klaszterezett formában megjeleníteni, továbbá a GoogleMaps térképére vetíteni, illetve diagramokat készíteni az eredményhalmaz adataiból. Van továbbá egy Timeline nevű keresőfelület is, amely időskála mentén mutatja a találatok képeit.
Internet Archive
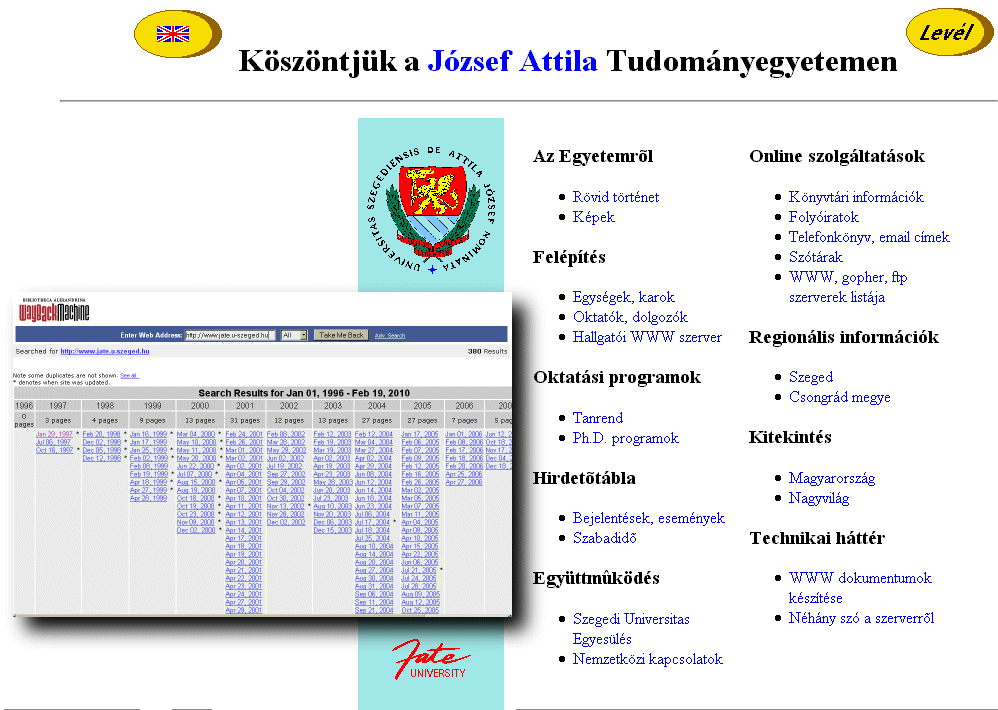 Az 1996-ban San Francisco-ban alapított non-profit szervezet a weblapok tartalmának indexelése vagy a digitális dokumentumok metaadatainak összeszedése helyett a weboldalak és dokumentumok tényleges begyűjtését és archiválását választotta céljának, hogy egy "Internet Library"-t építsen belőlük. A web aratását az Alexa cég végzi számukra, onnan veszik át és jelentetik meg a Wayback machine nevű szolgáltatásukban, legalább 6 hónapos késéssel.
Az 1996-ban San Francisco-ban alapított non-profit szervezet a weblapok tartalmának indexelése vagy a digitális dokumentumok metaadatainak összeszedése helyett a weboldalak és dokumentumok tényleges begyűjtését és archiválását választotta céljának, hogy egy "Internet Library"-t építsen belőlük. A web aratását az Alexa cég végzi számukra, onnan veszik át és jelentetik meg a Wayback machine nevű szolgáltatásukban, legalább 6 hónapos késéssel.
Emellett más szervezetekkel - köztük tömeges digitalizálást végző könyvtárakkal - is együttműködnek, valamint magánszemélyek feltöltéseit is elfogadják, így a jelenleg mintegy 150 milliárd lapot tartalmazó web-archívum mellett egy 2,5 milliós szöveggyűjteményt, egy 400 ezer tételes filmarchívumot, valamint kb. 710 ezer hangfelvételt és élő koncertfelvételt, és több mint 33 ezer féle szoftvert is szolgáltatnak. A web-archívum már 2 petabyte méretű és havonta 20 terabyte-tal növekszik. Segítségével olyan tartalmakhoz is hozzáférhetünk, amelyek már régóta eltűntek az "élő" webről.
Sajnos csak URL cím szerinti keresés van, magukban a weblapok tartalmában nem tudunk keresni - bár ezt a lehetőséget évek óta ígérik az IA működtetői. Az URL-kereső lehetőségeit az Advanced Search oldalon ismertetik (érdekes funkció például ugyanazon weboldal két különböző állapotú mentésének összehasonlítása). Mivel a központi archive.org szerver rendszerint leterhelt és lassú válaszidőket produkál, ezért érdemesebb lehet az International School of Information Science gépén levő másolatot használni, amely az 1996-2007 közötti mentéseket tartalmazza.
Könyvtári szempontból különösen érdekes az IA digitális könyvgyűjteménye, amely a legnagyobb digitalizáló projektek (pl. a Google, a Microsoft, vagy a Yahoo által szponzorált programok, illetve a Universal Library Project/Million Books Project vagy a Project Gutenberg) anyagát teszi együtt kereshetővé és letölthetővé (köztük sok magyar vagy magyar vonatkozású könyvet is). Az egysoros gyorskereső mellett itt is van egy Advanced Search űrlap, amivel bármilyen metaadatra rákereshetünk (teljes szövegű keresés itt sincs). Viszont mivel a könyvek sokféle forrásból származnak, ezért számításba kell venni, hogy a metaadatok is nagyon vegyesek: eltérő mezőket használnak az egyes gyűjtemények, ill. eltérő teljességgel és módon töltik ki ezeket. Emellett a betűhibák is gyakoriak, pl. a magyar karaktereknél, ezért érdemes többféle módon is próbálkozni és kihasználni az Apache Lucene keresőnyelv lehetőségeit.
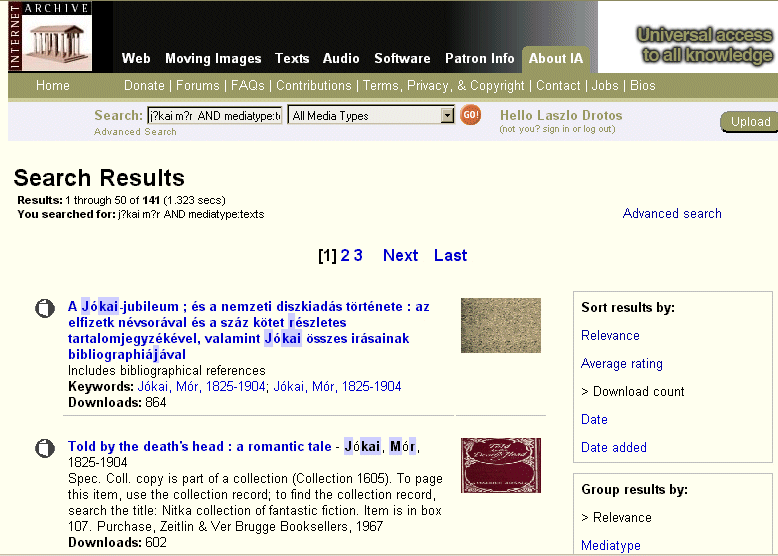 A találati listákat többféle módon szűrhetjük és csoportosíthatjuk, és néhány további opció is megjelenik a képernyő jobb szélén (célszerű például a Turn off thumbnails-re kattintva kikapcsolni a kis animált képek megjelenítését, mert ezek eléggé lelassítják a nagyobb listák böngészését). Ha kiválasztunk egy tételt, akkor megnyithatjuk (Read Online menüpont) vagy letölthetjük azt, a részletes leíró adataitól balra eső sávban felsorolt formátumokban: rendszerint PDF és DjVu, valamint különféle e-book formátumok, illetve egyszerű OCR-es text (ez utóbbit a Google le szokta indexelni, úgyhogy a site:www.archive.org/stream opcióval lehet azért a teljes szövegben is keresni, ha nem is olyan kényelmesen, mint a Google Books-nál). A képoldalakat tartalmazó PDF és DjVu verziókban is van általában OCR-es szövegréteg, így ezeken belül is lehet keresni. Az All Files: HTTP feliratra kattintva még további fájlokhoz is hozzáférünk: pl. eredeti masterképek JPEG2000 (JP2) formátumban, ill. MARC és XML formátumú metaadatok.
A találati listákat többféle módon szűrhetjük és csoportosíthatjuk, és néhány további opció is megjelenik a képernyő jobb szélén (célszerű például a Turn off thumbnails-re kattintva kikapcsolni a kis animált képek megjelenítését, mert ezek eléggé lelassítják a nagyobb listák böngészését). Ha kiválasztunk egy tételt, akkor megnyithatjuk (Read Online menüpont) vagy letölthetjük azt, a részletes leíró adataitól balra eső sávban felsorolt formátumokban: rendszerint PDF és DjVu, valamint különféle e-book formátumok, illetve egyszerű OCR-es text (ez utóbbit a Google le szokta indexelni, úgyhogy a site:www.archive.org/stream opcióval lehet azért a teljes szövegben is keresni, ha nem is olyan kényelmesen, mint a Google Books-nál). A képoldalakat tartalmazó PDF és DjVu verziókban is van általában OCR-es szövegréteg, így ezeken belül is lehet keresni. Az All Files: HTTP feliratra kattintva még további fájlokhoz is hozzáférünk: pl. eredeti masterképek JPEG2000 (JP2) formátumban, ill. MARC és XML formátumú metaadatok.
Összeállította: Drótos László, Magyar Elektronikus Könyvtár