



Tomas Mikolov és tsai a Google laboratóriumában egy új gépi fordítási eljárást dolgoztak ki, ami alaposan felkavarta a szakmát. Mivel a Nyelv és Tudomány már összefoglalta a lényeget, mi most a kalandvágyóbb olvasókat csábítjuk a vektorterekbe, hogy lássuk hogyan lehet hasonlóságot találni két különböző nyelvű és tárgyú dokumentumhalmaz között.
Miért kell új módszer?
Jogosan merülhet fel a kérdés, miért kell nekünk új módszer. Erre válaszolni csak úgy lehet, hogy a hegymászók is azért másznak meg egy hegyet, mert ott van. A kutatóknak meg problémáik vannak, és ahogy a hegymászók is felmennek olyan csúcsokra, melyeken előttük mások már jártak, úgy a kutatók is nekiesnek régi, részben vagy egészben már megoldott kérdéseknek. Jelen esetben azonban van egy nagyon praktikus magyarázata is a dolognak; nincs elegendő ún. párhuzamos korpusz, azaz több nyelven is elérhető szöveg, mely tartalma megegyezik. Ha lenne elegendő ilyen szövegünk minden lehetséges nyelvpárra, akkor a napjainkban divatos statisztikai módszerekkel egész jól működne már a gépi fordítás.

Sajnos azonban kevés párhuzamos szöveg létezik, ha akad is, akkor az általában egy vagy két világnyelven, vagy egy kisnyelv és egy világnyelv viszonylatában létezik. Az Ethnologue katalógusában 7105 élő nyelvet tartanak nyilván, ha minden nyelvre csupán az angol szöveggel készítünk párhuzamos korpuszt, már az is hatalmas szövegmennyiséget jelent (eltekintve attól, hogy a nyelvek jelentős részének nincs írott formája). Egyszerűbb tehát azzal dolgozni ami van, szövegekkel.
Vektorterek
A legtöbb kereső és információkinyerő alkalmazás ún. vektorterekkel dolgozik, ami nagyon egzotikusnak hangzik, de valójában egyszerű, mint egy faék. Minden dokumentum (vagy mondat, bekezdés stb.) jellemezhető a benne előforduló szavak számával, így egy dokumentum tkp. egy vektor. Az alábbi ábra ezt szemlélteti, amin az M1,...,M14 oszlopok az egyes dokumentumok.
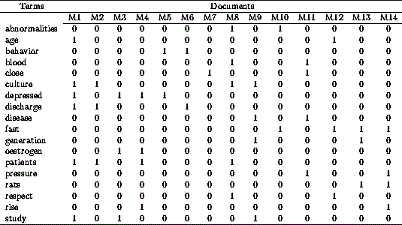
Egy ilyen táblázatot term-document mátrixnak hívunk. Ez tkp. egy ún. szózsák, vagy bag-of-words modell, mivel a nyelvtani struktúrát figyelmen kívül hagyja. Ez annyit tesz, hogy a "Kutya megharapta a postást" és a "Postás megharapta a kutyát" mondatok között nem tud különbséget tenni, hiszen mindegyikben ugyanazok a szavak ugyanannyiszor fordulnak elő (természetesen szótövezés után). Ugyanakkor a táblázat egyes sorai megadják egy adott szó disztribúcióját. Amelyik oszlopban értéket vesz fel az adott szó, ott az adott dokumentumot leíró oszlop egyben jelzi, milyen más szavakkal fordul elő. Ha elfogadjuk a disztribúciós szemantika alaphipotézisét, mely szerint egy szó jelentését ismerni annyi, mint ismerni lehetséges előfordulásait, akkor a term-document matrix sorai egyben egy-egy szó jelentését is rögzítik.
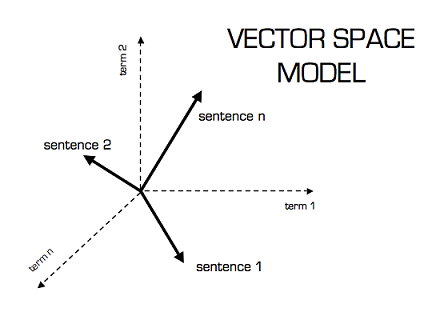
Ha geometriailag szeretnénk ábrázolni egy-egy term-document mátrixot, akkor a fenti ábrához hasonló ún. többdimenziós teret kapnánk, melynek minden szó egy dimenziója, egy dokumentum pedig ezen tengelyek mentén felvett értékekkel jellemezhető. Többdimenziós terekben nagyon nehéz egy embernek gondolkodnia, és momentán még a számítógépek sem dolgoznak velük eléggé fürgén. Szerencsére azonban a főkomponens-analízis nevű technikának hála a sok-sok dimenzió leredukálható akár kettőre is.
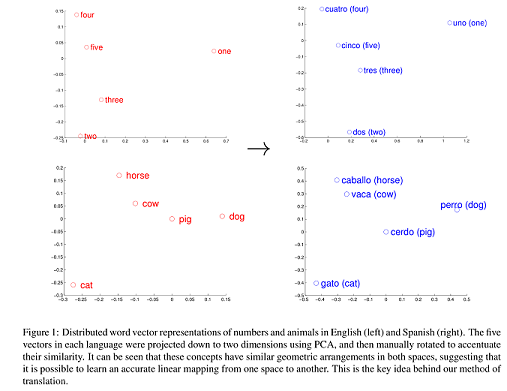
Régóta ismert jelenség, hogy különböző nyelveken a (kb.) azonos jelentésű szavak helyzete a vektortérben hasonló. A fenti ábra, melyet Mikolov és tsai tanulmányából vettünk át, remekül szemlélteti ezt a jelenséget. Az új módszer lényege, hogy a két- vagy többdimenziós vektortérben kereshetünk hasonló pozíciókat, nem kell feltétlenül párhuzamos korpuszokkal rendelkeznünk a fordításhoz.
Kérdések
Az új eljárás azért izgalmas különösen, mert nyelvelméleti kérdéseket is felvet. Mennyire hasonlóak a nyelvek, mennyire tartható a hipotézis, hogy a vektorterek hasonló pozíciói, hasonló fogalmakat jelenítenek meg? Ha a szózsák modell el is tekint a nyelvtani szerkezettől, a hasonlóság okának tarthatjuk-e azt, hogy a nyelvek rendelkeznek univerzális tulajdonságokkal? Fordítva is kérdezhetjük, az eljárás működőképessége alátámasztja a nyelvi univerzálék meglétét?
Napjainkban az ún. generatív grammatika irányzata egyre inkább visszaszorul, mivel általános szabályokat keres és nem igazán vizsgálja a nyelv statisztikai tulajdonságait. Az új eljárás viszont épp arra épít, hogy minden nyelv mögött ott van egy univerzális struktúra és a gépi tanulás módszereivel a szisztematikus különbségek "megtanulhatóak". Lappin és Shieber Machine learning theory and practice as a source of insight into universal grammar című tanulmányukban is amellett érveltek, hogy a gépi tanulás módszere talán sikeresen tárhatják fel az univerzális grammatikát.
Az eljárás legnagyobb hátránya szerintünk az, hogy hiányzik belőle a kompozicionalitás, mely szerint egy összetett kifejezés jelentése függ a benne szereplő tagok (szavak, kifejezések stb.) jelentésétől és az összetétel módjától. Azaz a "A kutya megharapta a postást" és a "A postás megharapta a kutyát" mondatok jelentésbeli különbségét nem csupán a bennük előforduló szavak gyakorisága (disztribúciója), hanem azok grammatikai struktúrája által jelzett sorrendje is meghatározza. Ezért úgy gondoljuk, a jövőt a kompozicionális disztribúciós szemantika jelenti a gépi fordítás és a nyelvtechnológia egyéb területein is - de ehhez sokkal izmosabb számítógépekre lesz szükségünk, addig pedig marad a szózsák modell és a vektorterek.




