Az alkalmazott nyelvészeti kutatási és nyelvtechnológiai fejlesztési munka egyik legfontosabb eszközét az ún. szövegkorpuszok jelentik. Bár létrehozásuk - különösen manuális módszerrel - elég költséges, hasznuk mind a kutatásban, mind a fejlesztésben kimagasló jelentőséggel bír. Lássuk a korpuszokat most közelebbről is!
Mi a korpusz?
A korpusz fogalmának a meghatározását illetően a szakirodalom nem egységes. A Magyar Nemzeti Szövegtár honlapja a következőképpen definiálja a korpuszt:
„A korpusz ténylegesen előforduló írott, vagy lejegyzett beszélt nyelvi adatok gyűjteménye. A szövegeket valamilyen szempont szerint válogatják és rendezik. Nem feltétlenül egész szövegeket tartalmaz, és nem csak tárháza a szövegeknek, hanem tartalmazza azok bibliográfiai adatait, bejelöli a szerkezeti egységeket (bekezdés, mondat)”.
A definícióban megfogalmazottakon túl fontos rámutatnunk, hogy a szövegkorpuszok a legtöbb esetben valamilyen manuális vagy automatikus feldolgozási folyamaton esnek át, és ennek a feldolgozási folyamatnak (másképpen: annotációnak) a sajátságait gyakorta a korpusz jövőbeli felhasználási céljai határozzák meg.
Az alábbi ábra például (hogy tematikában a korábbi poszthoz kapcsolódjunk) egy névelem-annotált korpusz részletét mutatja be:

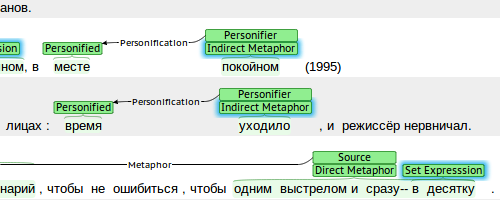
A korpuszokban az egyes elemeken kívül az azok közötti, különböző típusú kapcsolatokat, összefüggéseket is annotálhatjuk. Erre mutat példát az alábbi ábra, amely egy orosz nyelvű metafora-korpuszból közöl részletet:
A korpuszok tehát mindig valamilyen céllal készülnek, és ennek nem mond ellent az sem, ha az adott korpusz nem egy bizonyos jelenség vizsgálatához jön létre, hanem például egy adott nyelv reprezentatív korpusza kíván lenni (mint amilyen például a Magyar Nemzeti Szövegtár). Ilyenkor ugyanis a készítők úgy válogatják össze a korpusz szöveganyagát, hogy az éppen ennek az igénynek tudjon megfelelni.
Bár a korpusz definíciójába nem tartozik bele elengedhetetlen kritériumként, fontos említést tenni arról is, hogy a korpuszok legtöbbször digitalizált formájúak, ugyanis csupán ez teszi lehetővé a gépi elemzést. A korpusznyelvészet egyik legfontosabb célja az, hogy a nyelvi jelenségeket empirikusan, kvalitatív és kvantitatív szempontból egyaránt vizsgálja, ehhez pedig nagy mennyiségű szöveg elemzésére van szükség, ami manuálisan kivitelezhetetlen feladat. A korpusz szövegeinek tehát digitalizált formájúnak, ezáltal géppel olvashatónak kell lennie.
Egy kicsit a korpuszok történetéről...
Annak ellenére, hogy a korpuszalapú kutatások számítógépes támogatottság hiányában nehezen kivitelezhetőek, a korpuszok alkalmazásának kezdetleges formáival a számítógépek elterjedését megelőző időben is találkozunk. Már ekkor alkalmaztak ugyanis szövegkorpuszokat grammatikák és szótárak szerkesztésére.

Egy doboznyi cédula a Nagyszótárhoz (A magyar nyelv nagyszótára) forrás: http://www.matud.iif.hu/2016/07/06.htm
Mivel ezeket az adatbázisokat nem elektronikus formában tárolták, számítógéppel támogatott elemzésük értelemszerűen nem is volt lehetséges. Egy szövegkorpusz papíron, kézzel végzett elemzése ugyanakkor rendkívül időigényes és fáradságos feladat, s már néhány száz mondat manuális vizsgálata is nehezen hajtható végre.
Nem véletlen tehát, hogy az elektronikus szövegkorpuszok megjelenése új távlatokat nyitott az egyes nyelvek, illetve nyelvi jelenségek tanulmányozásában. Automatikus módszerrel gyorsabban, egyszerűbben és pontosabban végezhető el jelentős mennyiségű szöveg feldolgozása, ami egyben arra is lehetőséget ad, hogy általános érvényű, empirikusan igazolt megállapításokat tehessünk a vizsgált jelenség vonatkozásában.
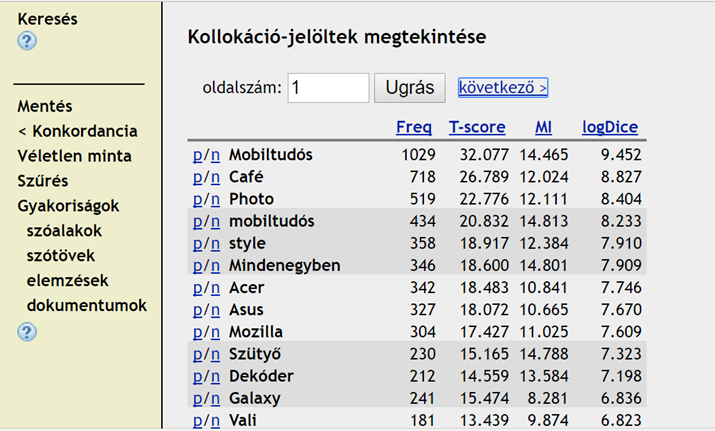
Részlet a blog szótő kollokációiból a szót követő pozícióban az MNSZ2 adatai alapján forrás: http://clara.nytud.hu/mnsz2-dev/
A korpuszok alkalmazása ma már nélkülözhetetlen a különböző nyelvészeti munkák során. Többek között a lexikográfia is nagymértékben épít rájuk, hiszen a segítségükkel könnyedén vizsgálható a szavak jelentése és kollokációs mintája, valamint a különböző regiszterekhez kötött szógyakoriság is. Hazánkban a Magyar Tudományos Akadémia 1984-ben határozatban döntött arról, hogy a nagyszótár munkálatainak folytatását elektronikus szövegkorpusz alapján kell végezni. A lexikográfia mellett jelentős szerepet töltenek be a korpuszok a fordításkutatásban és a fordítóképzésben is. Emellett sokszor alkalmazzák őket az anyanyelv és idegen nyelv elsajátításának vizsgálatában, valamint az idegen- és szaknyelvoktatás területén.
A korpuszok szerepe a fejlesztésben
A korpuszok nem kisebb szerepet játszanak a kutatás mellett a fejlesztési oldalon is. A különböző nyelvfeldolgozó algoritmusok fejlesztése és tesztelése ugyanis legtöbbször kézzel annotált korpuszok alapján történik. Ez azt jelenti, hogy azokat a nyelvi jelenségeket, amelyeket jelenleg géppel nem tudunk kezelni, manuális munkával feldolgozzuk, létrehozva ezáltal egy a gép számára olvasható, megfelelő méretű tanító adatbázist. E korpusz segítségével azután már lehetővé válhat egy olyan feldolgozó eszköz fejlesztése, amely az addig automatikus módszerrel elvégezhetetlen feladatot képes lesz kivitelezni.
A kézzel annotált korpuszok jól alkalmazhatóak többek között a jelentésegyértelműsítésben, amely számos nyelvtechnológiai feladat egyik kulcsproblémája. Így fontos támogatói lehetnek az anaforák kezelésének, a szintaktikai elemzésnek vagy a gépi fordításnak is.
A korpuszannotáció típusai
A korpuszok tipizálásának egy lényegi szempontja, hogy bennük a szövegeket milyen annotációval látták el a korpusz építői. Az annotáció olyan annotációs jelek (számítógépes nyelvészeti terminussal: tagek) alkalmazását jelenti, amelyeket a korpuszban levő különböző elemekre, kifejezésekre visznek fel. Ezek a jelek hivatottak explicitté tenni a nyelvi adatokban már meglevő, azonban addig implicit formájú információt, ahogy azt már a poszt elején közölt ábrákon is láttuk.
Az annotációt tipizálhatjuk aszerint, hogy a korpuszban levő szövegekben milyen mélységig „hatol le”, tehát, hogy mit tekint a feldolgozás egységének. Eszerint megkülönböztetünk szöveg-, mondat-, valamint tokenszintű elemzést.
Az annotálási feladat automatikus, félautomatikus, valamint manuális munkával is megvalósítható. Számos feldolgozási munka (pl. a lemmatizálás vagy a szófaji egyértelműsítés) ma már olyan hatékonyággal végezhető el automatikus módszerrel, hogy ezekben a feladatokban nem szükséges humán annotátorokat alkalmazni.
A legtöbb annotálási munka azonban – mint már emíltettük – automatikusan nem végezhető el kielégítő eredményességgel, illetve a különböző elemző eszközök fejlesztéséhez is gyakorta kézzel annotált korpuszokra van szükség. Ezekben az esetekben tehát nélkülözhetetlen a manuális feldolgozó munka. Amennyiben az annotálás egy része automatikus módszerrel elvégezhető olyan hatékonysággal, hogy az már támogatni tudja az emberi munkavégzést, úgy először géppel elemeztetik a korpusz szövegeit, amelyet humán ellenőrzés és korrekció követ. Ezt nevezzük félautomatikus megoldásnak. Amennyiben azonban az annotálás – annak jellege miatt – automatikus módszerrel egyáltalán nem támogatható, úgy a teljes munkát humán annotátoroknak kell elvégezniük. Az alábbi ábra a GATE nevű eszközben végzett humán annotációból mutat egy példát:
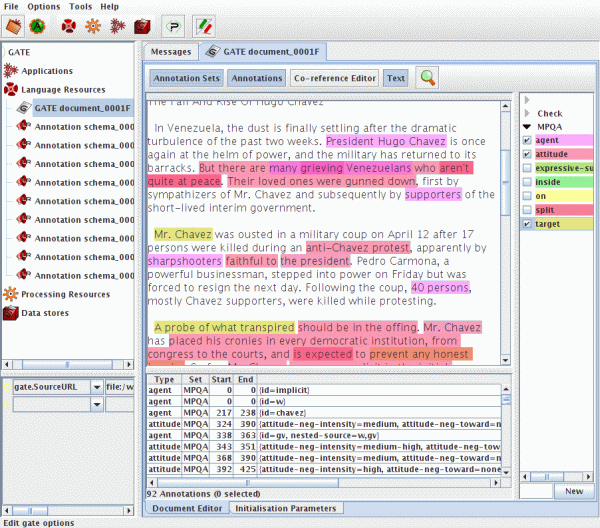
Forrás: http://mpqa.cs.pitt.edu/annotation/
Az annotátorok a feldolgozói munkát legtöbbször egy a fentebbihez hasonló, specifikusan erre a célra kialakított felületen végzik. Az eszköz lehetőséget ad nekik arra, hogy a feldolgozás során a korpuszban ne magukat az annotációs tageket, azok nyitó- és zárótagjeit kelljen alkalmazniuk, hanem egyszerű, kijelöléses megoldással tudjanak a megfelelő elemekhez annotációt kapcsolni. Ez a megoldás azon túl, hogy a munkavégzést jelentősen megkönnyíti és gyorsítja, az annotálási hibák esélyét is csökkenti.
A minőségbiztosítás jelentősége
Az annotátorok közötti egyetértés mérése rendkívül fontos. Ez ugyanis már a munka első szakaszában megmutatja, ha a feladat tulságosan szubjektív, vagy éppen az annotálási útmutató vagy az annotátorok betanítása nem volt megfelelően eredményes. Ily módon lehetőséget ad a korrekcióra még azelőtt, hogy egy nagy méretű, ám rossz minőségű adatbázis születne.
Az annotátorok közötti egyetértés mérése úgy történik, hogy a korpusz egy bizonyos részét (lehetőség szerint a 10%-át) a korpusz összes annotátora feldolgozza, majd az annotációt valamely, erre a célra fejlesztett algoritmus segítségével összevetik egymással. Ilyen mérési eszköz például az ún. Cohen’s Kappa-statisztika (angolul: Cohen’s Kappa statistic). A méréssel kapott értékek (annotátorok közötti egyetértési ráta, angolul: inter-annotator agreement rate) megmutatja, hogy az annotátorok hány esetben látták el valamilyen taggel a korpusz bizonyos egységeit, valamint azt is, hogy hány alkalommal használták rájuk ugyanazt a taget. Ennek köszönhetően a Cohen’s Kappa-statisztika komplex, a minőség javítására jól alkalmazható mutatónak tekinthető.
A minőség mérése során értelemszerűen nem várunk el 100%-os egyezést, hiszen humán annotátorok dolgoznak, megengedhető valamennyi szubjektív döntés és némi pontatlanság. A munka minőségét a Kappa-statisztika alapján is ún. Kappa-sávok alapján értékeljük. 80%-os vagy afölötti egyetértés esetén például már kiválónak tekintjük a súlyozott Kappa értékét.

A korpusz mint a nyelvtechnológia motorja
Végezetül, érdemes rámutatni arra a tendenciára, amely a szövegkorpuszok és a szövegfeldolgozó algoritmusok keletkezését jellemzi. Azt láthatjuk ugyanis, hogy minél több, nagyobb méretű és jobb minőségű annotált korpusz áll a rendelkezésünkre, annál több és jobb minőségű feldolgozó eszköz fejlesztésére nyílik lehetőségünk. Ez pedig értelemszerűen újabb, még nagyobb méretű és még jobb minőségű annotált korpuszok létrehozását segíti elő. A folyamat tehát öngerjesztő, és a nyelvtechnológia egyre nagyobb ütemben zajló fejlődését eredményezi.
IRODALOM
Cohen, J. 1960. A Coefficient of Agreement for Nominal Scales. Educational and Psychological Measurement 20. 37–46.
Gábor K.–Hája E.–Kuti J.–Nagy V.–Váradi T. 2008. a lexikon a nyelvtechnológiában. In Kiefer F. szerk. Strukturális magyar nyelvtan 4. A szótár szerkezete. Budapest, Akadémiai. 853–895.
Károly K. 2003. Korpusznyelvészet és fordításkutatás. Fordítástudomány 5(2). 18–26.
Klaudy K. 2005. Párhuzamos korpuszok felhasználása a fordításkutatásban. In Lanstyák I.–Vanconé Kremmer I. szerk. Nyelvészetről változatosan. Dunaszerdahely, Gramma. 153–185.
Krug, M.G. 2000. Emerging English Modals: A Corpus-Based Study of Grammaticalization. Topics in English Linguistics 32. Berlin and New York, Walter de Gruyter.
McEnery, T. 2005. Corpus Linguistics. In Mitkov, R. 2005. The Oxford Handbook of Computational Linguistics. Oxford, Oxford University Press. 448–463.
Nikunen, A. 2007. Different approaches to word sense disambiguation. Language technology and applications Essay. University of Helsinki, Department of Computer Science.
Péch O. 2007. A lexikai kohézió vizsgálata a fordításkutatásban – új távlatok a korpusznyelvészeti módszernek köszönhetően. Fordítástudomány IX(1). 79–96.
Prószéky G.–Olaszy G.–Váradi T. 2003. Nyelvtechnológia. In Kiefer F. szerk. A magyar nyelv kézikönyve. Budapest, Akadémiai.
Szabó M.K–Nyíri Zs.–Lázár B. 2017c. Negatív emotív szemantikai tartalmú fokozó elemek vizsgálata az angol–orosz és orosz–angol fordítás tükrében. In XI. Alkalmazott Nyelvészeti Doktoranduszkonferencia konferenciakötete. Megjelenés előtt.
Szirmai M. 2005. Bevezetés a korpusznyelvészetbe. Budapest, Tinta.
Vincze V. Előadásjegyzet. (http://www.inf.u-szeged.hu/~vinczev/oktatas.html)
Копотев, М.В.–Гурин, Г.Б. 2006. Принципы синтаксической разметки Хельсинкского аннотированного корпуса русских текстов ХАНКО. In Копотев, М.В.– Гурин, Г.Б. Компьютерная лингвистика и интеллектуальные технологии: труды Международной конференции «Диалог-2006». Москва, РГГУ. 280–284.
Шаров С. А. 2003. Представительный корпус русского языка в контексте мирового опыта. In Шаров, С.А. Научно-техническая информация (НТИ) 2(6). 9–17.